Hoy vamos a hacer una introducción a Apache Spark, el nuevo motor del Big Data, se trata de un framework de computación paralela enfocando especialmente hacia la ciencia de datos.
Hay que destacar que Spark lleva incluidas librerías específicas para tratar datos estructurados (SparkSQL), integración con lenguaje R (Spark R), capacidades para el streaming de datos (Spark Streaming), machine learning (MLib) y computación sobre grafos (GraphX).
Esta primera introducción es una guía para su instalación, conceptos, estructura y el primer contacto que tendremos será la implementación de un Clúster Standalone con PySpark, las aplicaciones se ejecutan como un grupo independiente de procesos en el Cluster, dirigido por el programa principal.

 La gestión de los datos no estructurados se ha convertido en uno de los principales retos a los que hacen frente las compañías en lo relativo a gestión de información y Big Data. En este post damos una breve introducción al tratamiento de los mismos y las problemáticas más comunes en su gestión..
La gestión de los datos no estructurados se ha convertido en uno de los principales retos a los que hacen frente las compañías en lo relativo a gestión de información y Big Data. En este post damos una breve introducción al tratamiento de los mismos y las problemáticas más comunes en su gestión...jpg) A raíz de una consulta recibida en el post anterior a continuación mostramos las principales diferencias entre el “schema on write” que es el que ya conocemos de las BBDD tradicionales y el “schema on read” más ligado a la arquitectura Big Data.
A raíz de una consulta recibida en el post anterior a continuación mostramos las principales diferencias entre el “schema on write” que es el que ya conocemos de las BBDD tradicionales y el “schema on read” más ligado a la arquitectura Big Data. .png) Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.
Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.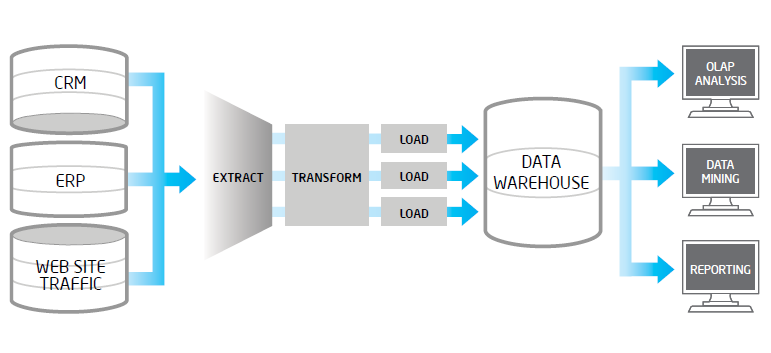 En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas..
En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas.. 
 En principio un concepto como el Big Data, puede parecer que es un traje que le queda demasiado grande a una pyme. El Big Data se define como la capacidad para recopilar y analizar las enormes cantidades de datos que el mundo genera actualmente, y aquí también las empresas, consumidores, máquinas con las que interactúan..
En principio un concepto como el Big Data, puede parecer que es un traje que le queda demasiado grande a una pyme. El Big Data se define como la capacidad para recopilar y analizar las enormes cantidades de datos que el mundo genera actualmente, y aquí también las empresas, consumidores, máquinas con las que interactúan..
 Ya está aquí el nuevo sorteo de Dataprix! Conseguir uno de los 3 ejemplares del libro 'Big Data Analytics with R and Hadoop' es muy fácil! En este post explicamos como!
Ya está aquí el nuevo sorteo de Dataprix! Conseguir uno de los 3 ejemplares del libro 'Big Data Analytics with R and Hadoop' es muy fácil! En este post explicamos como!
 Estos días he estado leyendo el libro Big Data Analytics with R and Hadoop, de Vignesh Prajapati, un libro que explica cómo integrar el paquete de análisis estadístico R y la plataforma de Big Data Apache Hadoop, para romper la barrera de la mayor limitación de R, que es la limitada cantidad de datos que acepta como juegos de datos para procesar.
Estos días he estado leyendo el libro Big Data Analytics with R and Hadoop, de Vignesh Prajapati, un libro que explica cómo integrar el paquete de análisis estadístico R y la plataforma de Big Data Apache Hadoop, para romper la barrera de la mayor limitación de R, que es la limitada cantidad de datos que acepta como juegos de datos para procesar.