
Consideraciones procesos ETL en entornos Big Data: Caso Hadoop
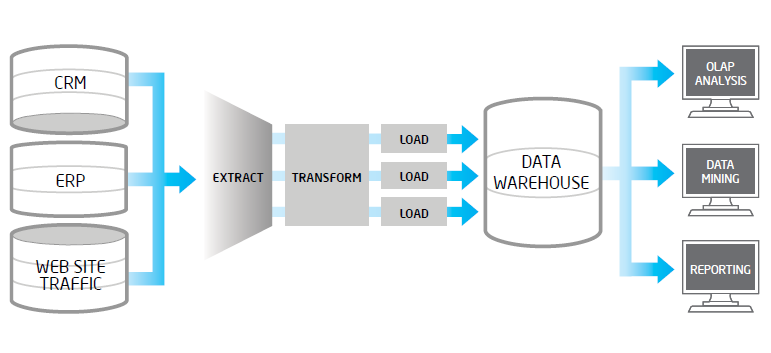 En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas..
En el presente post pretendemos mostrar la problemática que con frecuencia encontramos en los procesos de extracción, validación y carga de datos en los entornos Big Data. Un proceso ETL tradicional, extrae datos desde múltiples fuentes origen, después los valida, normaliza, realiza determinadas transformaciones y vuelca los mismos en un entorno datawarehouse para su posterior análisis. Cuando en los datos fuentes, tenemos volúmenes altos, una frecuencia de actualización alta en origen o bien son datos no estructurados, estos procesos ETL suelen tener problemas..
.png) Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.
Una de las herramientas más maduras en el mundo Big Data es el framework de licencia libre Apache Hadoop. En este post exponemos de forma resumida la integración entre Hadoop y uno de los fabricantes líder en analítica de negocio: SAS.


