
Una de las técnicas más utilizadas dentro del análisis predictivo son los árboles de decisión. Esta técnica tiene múltiples aplicaciones en el campo de la estadística, pero nos vamos a centrar en su uso para realizar predicciones, concretamente obtener probabilidades de eventos. En este post revisamos una posible forma de hacerlo con el software de uno de los principales fabricantes del software de business analytics: SAS (www.sas.com)

Existen diferentes formas de implementar árboles de decisión en SAS. En base a los módulos SAS existentes actualmente en el mercado, tenemos las siguientes opciones:
- Proceso predictivo guiado en SAS/Visual Analytics
- Construir modelo de forma guiada en SAS/Enterprise Miner
- Realizarlo con el módulo SAS/IML (macro treedisc)
- Realizarlo con el módulo SAS/OR (proc dtree)
- Realizarlo en código BASE con procedimientos SAS/STAT (Entorno Enterprise Guide)
En caso de hacerlo en Miner el modelo generado en Miner podría ser posteriormente ejecutado en Enterprise Guide utilizando la tarea de Data Mining -> Model Scoring.


En este post vamos a realizar el árbol de decisión en SAS/BASE que es un módulo más extendido y que requiere menor inversión económica. Hacerlo en SAS/EM (proc arboretum) o SAS/VA supondría un proceso guiado, en principio más sencillo.
Para realizar el árbol de decisión vamos a emplear el procedimiento proc hpsplit (disponible en SAS/STAT 12.3 en SAS 9.4), es un procedimiento de la familia hp (high performance) orientados a alto rendimiento y que pueden ser ejecutados en una única máquina o en múltiples nodos. En este caso hpsplit nos va a permitir crear y ejecutar un arbol de decisión.
El ejemplo sobre el que vamos a trabajar es un caso de analítica predictiva aplicada a las campañas de marketing. Nuestra situación de partida es un dataset que contiene el target de clientes sobre el que pensamos ejecutar una campaña de marketing por el canal que corresponda (e-mail, correos postal, llamada, SMS, etc..). Este target es un filtro determinado del total de nuestra cartera de clientes en base al producto o servicio objeto de la campaña. Con objeto de ajustar los costes de la campaña nos interesa obtener la probabilidad de respuesta a la campaña y aquí es donde entra la analítica predictiva. Los clientes cuya probabilidad de respuesta fuera muy baja serían eliminados del target, para no caer en costos que van a producir muy bajo retorno. Contamos con un fichero histórico de datos de campañas ejecutadas. En este histórico tenemos un campo que nos indica si hubo o no respuesta a la campaña (1 o 0) y una seríe de variables que caracterizan el cliente sobre el que se realizó la campaña.
res: respuesta a la campaña (1: redención, 0: sin redención)
id_cliente: código de cliente
edad: edad del cliente
compras_3m: número de compras realizadas en los últimos 3 meses
compras_12m: número de compras realizadas en los últimos 12 meses
tipo_cliente: Tipo cliente por canal principal de compra (W: web, T: tienda)
Para obtener el modelo dividimos la tabla que contiene el histórico de campañas (100k) en dos tablas una para entrenar el modelo (test) y otra para validarlo (validar).
data test validar;
set campañas_hist;
if _N_ < 70000 then output test; else output validar;
run;
Aplicamos el procedimiento hpsplit, la variable a predecir es res (respuesta a la campaña) y las variables predictoras son: tipo_cliente edad compras_3m compras_12m
proc hpsplit data=test maxdepth=4 maxbranch=2 nodestats=arbol; /* nodestats guarda el arbol */
target res_campaña; /* variable a predecir */
input tipo_cliente edad compras_3m compras_12m; /* variables en base a las q predecimos */
code file="%sysfunc(pathname(work))/model_dtree.sas"; /* guarda el modelo construido */
rules file="/home/juanvg1972/ficheros/rules_dtree.txt"; /* reglas aplicadas */
output importance=imporvar; /* importancia de cada variable */
run;
En la tabla arbol guardamos el arbol de decisión obtenida:
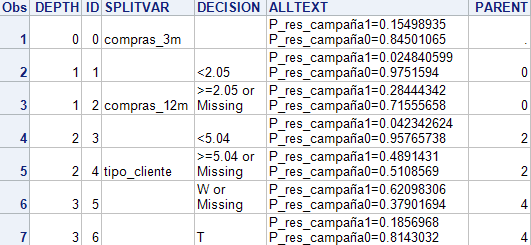
Podemos ver la importancia de cada variable que hemos guardado en la tabla imporvar
proc print data=imporvar (keep = itype tipo_cliente edad compras_3m compras_12m);
run;

Para visualizar gráficamente el arbol creado, empleamos el procedimiento netdraw que nos permite obtener una representación rápida, pero visualmente no es el más óptimo. Hay otras opciones para visualizar el arbol:
- Calcular el layout del arbol y pintarlo con proc sgplot
- Pintar la salida del fichero plaño rules_dtree.txt con una herramieta tipo GraphViz
- Generar arbol interactivo en SAS/GRAPH (ds2tree macro)
data arbol_or;
length parent_or id_or $2. desc_node $20.;
set arbol;
if parent = . then parent_or = 'OR'; else parent_or = parent;
id_or = id;
desc_node = strip(splitvar||'-'||decision); /* construimos el campo descriptivo que queremos visualizar */
run;
proc netdraw graphics data=arbol_or;
actnet / act=parent_or
succ=id_or
id=(desc_node)
nodefid
nolabel
pcompress
centerid
tree
arrowhead=0
xbetween=3
ybetween=2
rectilinear
carcs=black
ctext=white
htext=1;
run;
Una vez visualizado el arbol, lo aplicamos a la tabla validar para evaluar su capacidad predictiva.
data validar_res;
set validar;
%include "%sysfunc(pathname(work))/model_dtree.sas";
run;
En los campos P_res_campaña1 (prob res = 1) y P_res_campaña0 (prob res = 0) obtenemos la probabilidad de respuesta a la campaña.

Para validar el nivel de acierto del modelo podemos hacer una validación cruzada:
data validar_res1;
set validar_res;
if P_res_campaña1 >= 0.5 then res_campaña_p = 1;else res_campaña_p = 0;
run;
proc sql;
create table tabla_valid as
(select res_campaña, res_campaña_p, count(*) as conteo
from validar_res1
group by res_campaña, res_campaña_p);
quit;

El modelo definitivo una vez realizados los pasos e iteraciones necesarias para la depuración del modelo se aplica sobre el target de clientes de la campaña actual.
Este ajuste que hacemos sobre el target, permite rediseñar el target optimizando la probablidad de respuesta. Posteriormente a la ejecución de la campaña se realiza una comparación de probabilidad con la realidad

Por último, indicar que la forma de medir la mejora que sobre un target produce su redefinición mediante analítica predectiva es la obtención de la curva Lift (elevación) ,que mide la cantidad de veces en que la aplicación del Modelo Predictivo mejora el resultado que hubiéramos obtenido aplicando el target inicial.
Más info acerca de analítica de datos con SAS:
https://www.youtube.com/@datademyformacion6610

hola, me tira un error en el
Subido por fausto (no verificado) el 1 Agosto, 2015 - 13:31
hola, me tira un error en el proc hpsplit not found... tendras un mail donde te pueda hacer una consulta?
Grs.
Hola Fausto, proc hpsplit
Subido por Juan_Vidal el 5 Agosto, 2015 - 10:46
Hola Fausto,
proc hpsplit está disponible desde la última versión SAS 9.4.
Escribe aquí el detalle del error o puedes escribirme a cursos_a_medida_r@yahoo.es.
Saludos,
Hola, una pregunta. Cuando
Subido por Omar (no verificado) el 8 May, 2017 - 16:36
Hola, una pregunta. Cuando intento correr el árbol interactivo en Miner me genera un error "no se puede abrir el árbol interactivo, intente actualizar los nodos anteriores" pero ya lo hice y me sigue generando el mismo error, te habrá ocurrido alguna vez??
Hola Omar, Para trabajar con
Subido por Juan_Vidal el 2 Junio, 2017 - 09:29
En respuesta a Hola, una pregunta. Cuando por Omar (no verificado)
Hola Omar,
Para trabajar con el arbol interactivo en Miner antes has tenido que generar un arbol automático, ¿es tu caso?
saludos,
Necesito hacer una
Subido por Anonimo (no verificado) el 1 Febrero, 2018 - 13:10
Necesito hacer una segmentación de datos con arboles de decisión (CHAID) en SAS GUIDE(BASE) puedo con estos pasos generarlo??
Comprueba que el algoritmo
Subido por Juan_Vidal el 12 Septiembre, 2018 - 09:15
En respuesta a Necesito hacer una por Anonimo (no verificado)
Comprueba que el algoritmo que vayas a utilizar este en proc hpsplit, sino tienes otras opciones en SAS Miner o SAS Visual Statistics