
Hola Gente,
tengo algo armado hace un tiempo y a raíz de alguna pregunta en redopenbi lo publico aquí.
Se trata de leer un archivo XML y convertirlo en un archivo plano separado por comas utilizando Pentaho Data Integration (PDI) o Kettle.
Introducción
PDI siempre tratará de convertir las fuentes de entrada en filas y columnas, con este principio hay que partir siempre que uno intente hacer algo con este software.
El XML en un tipo de datos jerárquico, por ello habrá que transformarlo a dato tabular. Para manipular XML se utilizaXQuery y XPath como para manipular datos relacionales utilizamos SQL, cualquiera que quiera trabajar con este tipo de datos debe interiorizarse con estos conceptos.
Objetivo
Nuestro objetivo es leer el archivo entrada.txt, obtener los datos que deseamos y escribirlos en un archivo tabular separado por comas llamado salidaCSVFromXML.txt

El archivo entrada.xml contiene:
<?xml version="1.0" encoding="UTF-8"?><raiz><dato id="1">dato 1 <otroDato atributo="ab">otro dato 1</otroDato> </dato><dato id="2">dato 2 <otroDato atributo="abc">otro dato 2</otroDato> </dato><dato id="3">dato 3 <otroDato atributo="abcd">otro dato 3</otroDato> </dato><dato id="4">dato 4 <otroDato atributo="abcde">otro dato 4</otroDato> </dato></raiz>
El archivo salidaCSVFromXML.txt contendrá:
datoCol;idCol;otroDatoCol;atributoCol
dato 1; 1;otro dato 1;ab
dato 2; 2;otro dato 2;abc
dato 3; 3;otro dato 3;abcd
dato 4; 4;otro dato 4;abcde
El mapeo está claro y es:
Texto del nodo /raiz/dato a columna datoCol
Valor del atributo id del nodo /raiz/dato a columna idCol
Texto del nodo /raiz/dato/otroDato a columna otroDatoCol
Valor del atributo atributo del nodo /raiz/dato/otroDato a columna atributoCol
Manos a la obra
Abrimos Kettle utilizando el comando spoon.sh o spoon.bat según nuestro sistema operativo.
Creamos una nueva transformación y arrastramos al editor los pasos Entrada\"Obtener datos XML" y a la derechaSalida\"Salida Fichero de Texto", luego unimos ambos pasos y editamos la entrada XML haciendo doble click.
En la primera pestaña configuramos:
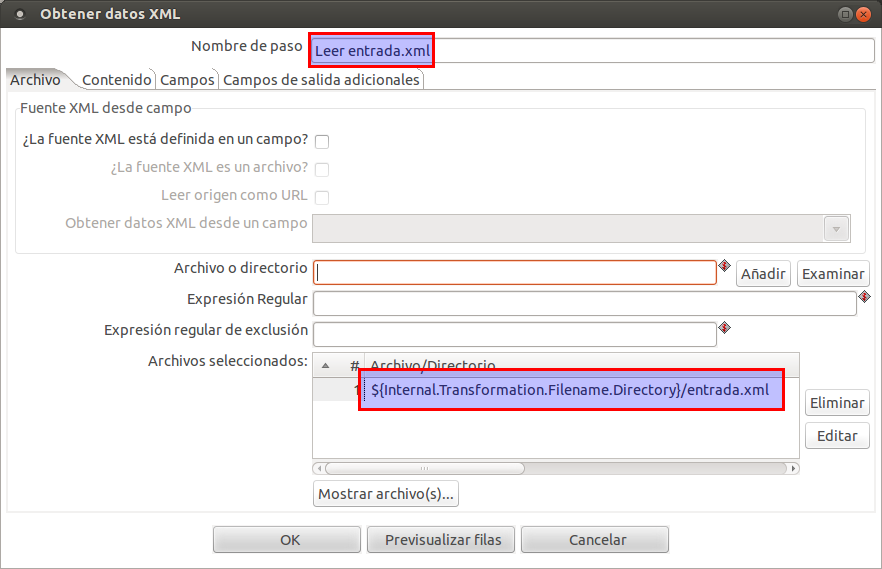
En la segunda pestaña debemos configurar cual será el nodo a ciclar, cada ciclo creará una nueva fila. En nuestro caso /raiz/nodo, en cada ciclo se asume que se trabaja a partir de este nodo. La cadena /raiz/nodo es una instrucción XPath.

Para darnos una idea de que implica esto, podemos utilizar uno de los tantos testers XPath online que existen, por ejemplo este https://www.mizar.dk/XPath/Default.aspx
Si colocamos:
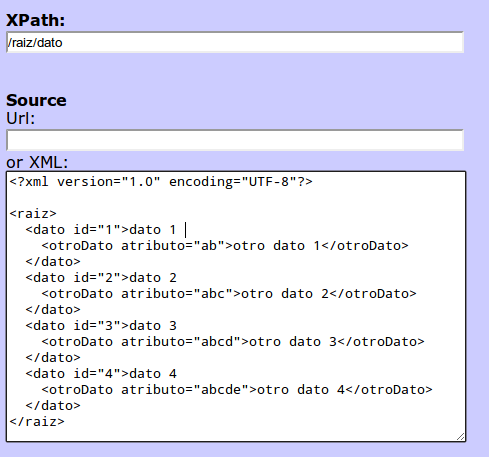
Y presionamos el botón "Test XPath", obtenemos el resultado con los nodos seleccionados por la expresión XPath en color:

Recomiendo utilizar estas herramientas siempre que haya que evaluar expresiones XPath.
Volvamos a Kettle y configuremos la pestaña "Campos" de la siguiente manera:

Notemos que lo que colocamos en la columna XPath es relativo a lo que definimos en la pestaña anterior, por ejemplo la tercera fila que define la columna otroDatoCol, tiene la expresión XPath otroDato/text(), pero la expresión completa es /raiz/dato/otroDato/text(), podemos ver la salida en el tester online con esta expresión completa:

Ahora podemos presionar el botón "Previsualizar filas" en Kettle y obtendremos:

Ahora cerramos el editor del paso presionando el botón "OK" y editamos el paso de salida de texto haciendo doble clic en el, en la primera pestaña configuramos lo siguiente:

Luego en la pestaña "Campos" presionamos el botón "Traer Campos" y quedará como sigue:

Cerramos este paso presionando el botón "OK" y listo, ya lo podemos ejecutar.
He subido a mi repo de github la trasnformación y el archivo de entrada de ejemplo: https://github.com/magm3333/material-osbi/tree/master/XML2CSV
Espero les sea de utilidad
Saludos
Mariano

Buenas, La verdad es que
Subido por JavierGomez el 5 Abril, 2013 - 09:23
Buenas,
La verdad es que cuando nunca has trabajado con XML, y te toca parsear uno...tienes que currartelo un poco.
En mi caso, me toco descargarme los ficheros XML de google analitics, que son bastante complejillos.
Pero poco a poco conseguí obtener los datos que necesitaba.
Javier.
Seguro que es una aplicación
Subido por Carlos el 5 Abril, 2013 - 19:08
En respuesta a Buenas, La verdad es que por JavierGomez
Si, hay un plugin
Subido por magm el 6 Abril, 2013 - 15:01
En respuesta a Seguro que es una aplicación por Carlos
Si existe un plugin, aquí puedes ver la info.
Saludos
Mariano
Hola, Ya conozco el
Subido por JavierGomez el 6 Abril, 2013 - 21:09
Hola,
Ya conozco el pluging, pero cuando realizas peticiones a google analytics de metricas, que devuelven más de 10 mil registros
es mejor crear una peticion http a google, y parsear el XML, ya que el pluging es lento. Realiza ciclos de lectura de 1000 registros.
Con la petición http, yo solicito de 10 mil en 10 mil. Además si el rango de fechas no es de un 1 dia, por ejemplo de 3 días o más
samplea la informacion.
Por tanto, lo que yo hago es obtener primero el maxresults de la peticion de google, una vez que lo tengo. configuro para los
dias que sean la misma peticion de 10 mil en 10 mil. Es decir, de 1 a 10.000, de 10.0001 a 20.000, etc...etc...
Voy parseando el XML, y los guardo en tabla.
De todas formas,
Gracias.
La verdad no se como funciona
Subido por magm el 7 Abril, 2013 - 16:23
En respuesta a Hola, Ya conozco el por JavierGomez
La verdad no se como funciona el plugin, no lo he utilizado, pero si ese es el trabajo que haces diariamente podrías pensar en automatizarlo. Ya tienes la lógica del parseo y descargar periódicamente un archivo mediante peticiones GET es sencillo, con Kettle lo podrías hacer. Por otro lado están los fuentes del plugin, en una de esas se podrían modificar para mejorar la eficiencia o bien proponerle al desarrollador esa característica.
Saludos
Mariano
Hola.... Ya está
Subido por JavierGomez el 8 Abril, 2013 - 10:35
Hola....
Ya está automatizado y va descargando esa información todos los días. Concretamente baja, hoy, ayer y antes de ayer.
Ya que hasta pasados 3 dias, los datos de google pueden ser actualizados.
Cuando hay peticiones puntuales, dependiendo de la metrica/dimension solicitada (por el volumen de datos), uso el pluging o configuro una extracción manual.
Gracias,
Javier.
Muchas gracias a los dos por
Subido por Carlos el 8 Abril, 2013 - 18:33
Muchas gracias a los dos por la info, muy interesante, me lo apunto en la lista de cosas pendientes para probar :)