El proyecto Apache Hadoop consiste en el desarrollo de software libre para computación distribuída escalable y segura.
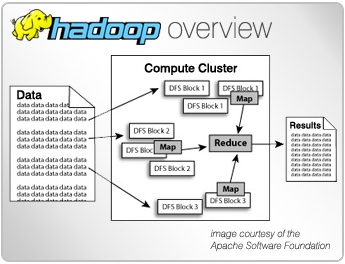 La librería de software de Hadoop es un framework que permite el procesamiento distribuído de juegos de datos de gran volumen utilizando clusters de ordenadores o servidores, utilizado modelos de programación sencilla.
La librería de software de Hadoop es un framework que permite el procesamiento distribuído de juegos de datos de gran volumen utilizando clusters de ordenadores o servidores, utilizado modelos de programación sencilla.
Hadoop está diseñado para escalar fácilmente desde sistemas de servidores únicos a miles de máquinas.
La librería detecta y gestiona errores en el nivel de aplicación para no tener que depender del hardware y proporcionar así alta disponibilidad con un cluster de servidores con un alto nivel de tolerancia a fallos en cada una de las máquinas que componen el cluster.
Módulos de Hadoop
El proyecto Hadoop está compuesto por cuatro módulos principales:
Hadoop Common es un conjunto de utilidades comunes para el resto de módulos.
HDFS, Hadoop Distributed Files System es el sistema de ficheros distribuídos que proporciona acceso de alto rendimiento a los datos de aplicaciones.
Hadoop YARN es un framework para programación de tareas y gestión de los recursos cluster.
Hadoop MapReduce es un sistema para el procesamiento en paralelo de grandes juegos de datos, basado en YARN.
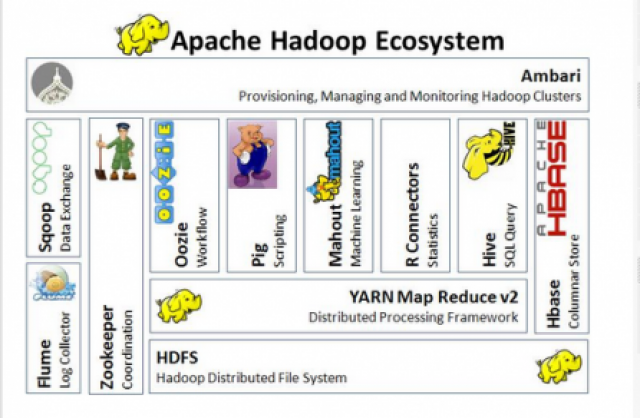
Ecosistema de Hadoop
Aparte de los módulos anteriores, la plataforma completa, o el ecosistema de Hadoop incluye otros proyectos relacionados como Apache Ambari, Apache Cassandra, Apache HBase, Apache Hive, Apache Mahout, Apache Pig o Apache Spark, entre otros.
Recursos sobre Apache Hadoop
Página principal del proyecto Apache Hadoop
Tutoriales y ayuda en el Wiki oficial de Apache Hadoop
Página de descarga de Apache Hadoop
Publicaciones sobre proyectos Apache en Dataprix
- Inicie sesión para enviar comentarios