En muchos casos, no se puede definir ningún atributo objetivo (etiqueta) y los datos deben ser agrupados automáticamente. Este procedimiento se denomina "Clustering". RapidMiner soporta un amplio rango de
esquemas de clustering que se pueden utilizar de la misma forma que cualquier otro esquema de aprendizaje. Esto incluye la combinación con todos los operadores de preprocesamiento.
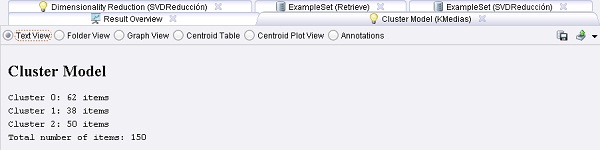
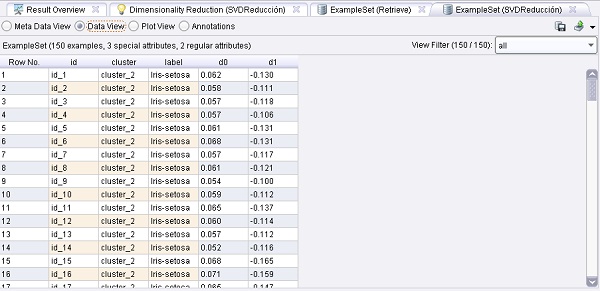
En este ejemplo, se carga el muy conocido conjunto de datos Iris (la etiqueta también se carga, pero sólo se utiliza para visualización y comparación y no para construir los clusters). Uno de los esquemas más simples de clustering, denominado KMeans, se aplica luego a este conjunto de datos. Después se realiza una reducción de dimensionalidad para que soporte mejor la visualización del conjunto de datos en 2
dimensiones.
Sólo realiza el proceso y compara el resultado del clustering con la etiqueta original (por ej., en la vista gráfica del conjunto de ejemplos). También se puede visualizar el modelo de cluster.
1. Agregar el operador Repository Access → Retrieve a la zona de trabajo y localizar el archivo //Samples/data/Iris con el navegador del parámetro repository entry.
2. Agregar el operador Modeling → Clustering and Segmentation → k-Means. Cambiar el nombre del mismo a “KMedias” y el parámetro k a 3. Conectar la salida del operador Retrieve a la entrada exa de este
operador y la salida clu (cluster model) de éste último al conector res del panel.
3. Agregar el operador Data Transformation → Attribute Set Reduction and Transformation → Transformation → Singular Value Decomposition. Cambiar el nombre del mismo a “SVDReducción”.
Conectar la salida clu (clustered set) del operador KMedias (k-Means) a la entrada exa de este operador y los 3 puertos de salida de éste último, exa (example set output), ori (original) y pre (preprocessing model), a conectores res del panel.
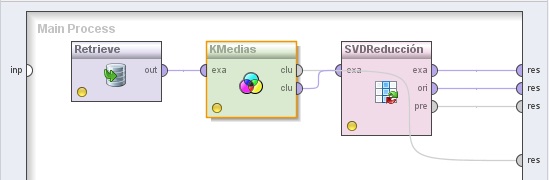
4. Ejecutar el proceso y observar el resultado.

 Esta obra está bajo una licencia de Creative Commons Reconocimiento-CompartirIgual | Servicios Publicidarios | Aviso legal
Esta obra está bajo una licencia de Creative Commons Reconocimiento-CompartirIgual | Servicios Publicidarios | Aviso legal