 Antes de comenzar la implementación del proceso ETL para la carga de la tabla de Hechos de Ventas, vamos a realizar alguna consideración sobre el particionado de tablas.
Antes de comenzar la implementación del proceso ETL para la carga de la tabla de Hechos de Ventas, vamos a realizar alguna consideración sobre el particionado de tablas.
Cuando estamos costruyendo un sistema de business intelligence con su correspondiente datawarehouse, uno de los objetivos (aparte de todas las ventajas de sistemas de este tipo: información homogenea, elaborada pensando en el analisis, dimensional, centralizada, estatica, historica, etc., etc.) es la velocidad a la hora de obtener información. Es decir, que las consultas se realicen con la suficiente rapidez y no tengamos los mismos problemas de rendimiento que suelen producirse en los sistemas operacionales (los informes incluso pueden tardar horas en elaborarse).
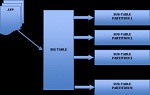
Para evitar este problema, hay diferentes técnicas que podemos aplicar a la hora de realizar el diseño fisico del DW. Una de las técnicas es el particionado.Pensar que estamos en un dw con millones de registros en una unica tabla y el gestor de la base de datos ha de mover toda la tabla. Ademas, seguramente habrá datos antiguos a los que ya no accederemos casi nunca (datos de varios años atras). Si somos capaces de tener la tabla “troceada” en segmentos mas pequeños seguramente aumentaremos el rendimiento y la velocidad del sistema.
El particionado nos permite distribuir porciones de una tabla individual en diferentes segmentos conforme a unas reglas establecidas por el usuario. Según quien realize la gestión del particionado, podemos distinguir dos tipos de particionado...

 ¿Alguna vez os habeis preguntado como deshabilitar el autocommit en el Management Studio de Sql Server? Pues la respuesta es rápida. Lo podeís cambiar activando en el menú Herramientas > Opciones > Ejecución de la consulta > SQL Server > Ansi > SET IMPLICIT_TRANSACTIONS...
¿Alguna vez os habeis preguntado como deshabilitar el autocommit en el Management Studio de Sql Server? Pues la respuesta es rápida. Lo podeís cambiar activando en el menú Herramientas > Opciones > Ejecución de la consulta > SQL Server > Ansi > SET IMPLICIT_TRANSACTIONS...