Apache Hive, data warehouse infrastructure on Hadoop
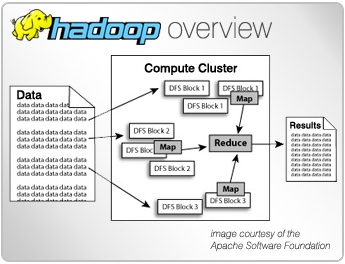
Hive is a software that works on Hadoop clusters creating a layer that allows the developer to abstract from the management of HDFS and MapReduce files through SQL-based data query operations, with the HiveQL language.
Hive can perform queries of not too much complexity, it does not allow transactional operations, and by providing a language similar to the SQL of relational databases to work with large amounts of data, this software is very suitable for data warehouse and analytics environments. For these reasons, Apache Hive is defined as a data warehouse infrastructure on top of Hadoop.
Hive was initially developed by Facebook, although it has evolved as an open source project of Apache, within the Hadoop ecosystem, and is currently used by large companies such as Netflix or Amazon in Amazon Elastic MapReduce or AWS.
Apache Hive is installed as a tool within a Hadoop installation and obviously needs Hadoop clusters to be running in order to be able to work on them.
Queries to Hive can be launched either directly from a command line environment or from applications via standard data connectors such as JDBC or ODBC. It should be noted that the abstraction layer provided by Hive, while it can greatly simplify the development of data-driven applications, is not as efficient as the direct use of MapReduce and HDFS file management, as the interpreter increases application latency considerably.
- Log in to post comments