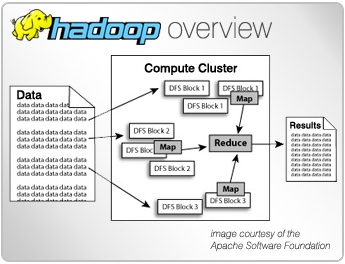
Spark is an open source framework from Apache Software Foundation for distributed processing of large amounts of data on clusters of computers, designed for use in Big Data environments, and created to enhance the capabilities of its predecessor MapReduce.
Spark inherits the scalability and fault tolerance capabilities of MapReduce, but far surpasses it in terms of processing speed, ease of use and analytical capabilities.
Apache Spark runs on a JVM (Java Virtual Machine) and supports several languages such as Java, Scala, Python, Clojure and R for the development of applications that can perform Map and Reduce operations by interacting with the Spark core through its API.
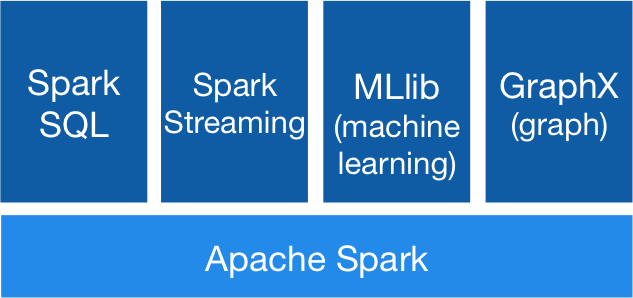
In addition to the Core API, at a higher level, the so-called Spark Ecosystem provides libraries that provide added Machine Learning and Analytics capabilities for Big Data.
The most important Spark libraries are:
- Spark Streaming: for real-time streaming data processing.
- Spark SQL + DataFrames: provides a layer for connecting to Spark data through a JDBC API, allowing SQL-style queries to be run on traditional BI and data visualisation tools.
- Spark MLlib: Machine Learning library, which allows the use of Machine Learning algorithms and utilities.
- Spark GraphX: an API for generating graphs and parallel graph computation.
- Log in to post comments