Administración de SQL Server, Integration Services y Analysis Services
Administración de SQL Server, Integration Services y Analysis Services Dataprix 24 October, 2013 - 23:59 Este manual de SQL Server reune las mejores publicaciones sobre administración y desarrollo sobre bases de datos SQL Server, y las herramientas de integración de datos y business intelligence SQL Server Integration Services y SQL Server Analysis Services que incluye la base de datos de Microsoft.
Este manual de SQL Server reune las mejores publicaciones sobre administración y desarrollo sobre bases de datos SQL Server, y las herramientas de integración de datos y business intelligence SQL Server Integration Services y SQL Server Analysis Services que incluye la base de datos de Microsoft.
Administracion de bases de datos Microsoft SQL Server
Administracion de bases de datos Microsoft SQL Server Dataprix 23 May, 2014 - 19:20Este capítulo reúne publicaciones sobre optimización, rendimiento, tuning, resolución de problemas y, en definitiva, administración de bases de datos Microsoft SQL Server
Administración de Microsoft SQL Server 2008
Administración de Microsoft SQL Server 2008 Dataprix 23 May, 2014 - 19:27Acceder a MySql desde Sql Server 2008
Acceder a MySql desde Sql Server 2008 il_masacratore 30 December, 2009 - 12:55Se puede dar el caso que necesitemos acceder a MySql desde Sql Server 2008. Para hacerlo podemos crear un servidor vinculado que use una conexión odbc. Como hacerlo paso a paso:
1. Descargar el cliente ODBC de Mysql para la plataforma del sevidor sql. Lo podeis hacer aquí.
2. Instalarlo (siguiente, siguiente, siguiente) y configurar un DSN de sistema. Para ello en el Administrador de orígenes de datos ODBC, en la pestaña DSN de sistema pulsamos Agregar y seleccionamos MySQL ODBC 5.1 driver. Acepatemos y aparece un formulario como el siguiente. Lo rellenaremos y probaremos pulsando Test para comprobar que funciona.

3. Añadir el servidor vinculado en la base de datos. Para ello nos conectamos a la base de datos y en el árbol de objetos vamos a Objetos de servidor, pulsamos botón derecho en Servidores vinculados y clickamos en Nuevo Servidor Vinculado, rellenamos los datos y ya lo tenemos.

4. Al finalizar el paso anterior ya tendremos acceso al servidor. Podemos verlo en la lista de servidores vinculados y opdremos navegar para ver las tablas que hay en la base de datos que hemos vinculado. También podremos usarlo para hacer consultas mediante la función tsql openquery.
Sintaxis: select [campo,] from OPENQUERY([servidor vinculado], [select mysql]).
SQLServer 2008: Actualizar estadísticas de tabla de forma dinámica en toda una base de datos
SQL08: tabella delle statistiche aggiornamento dinamico per tutta la banca dati il_masacratore 4 March, 2010 - 12:24Come in Oracle vi è una tabella che elenca tutte le tabelle del database (dba_tables) e possiamo usarlo per effettuare interventi di manutenzione in modo dinamico in SQL Server può fare la stessa query la tabella [database].dbo.sysobjects.
Nell'esempio riportato di seguito (come in altri che ho appeso) aggiornare le statistiche per tutte le tabelle di un database, SQL Server in modo dinamico interrogando il dizionario dei dati. Questo potrebbe essere incapsulati in una stored procedure o in un lavoro di eseguire direttamente i SQL Server Agent per tenere le statistiche aggiornate su tutte le tabelle di un database automaticamente.
-- Dichiarazione di variabili
DECLARE @dbName sysname
DECLARE @sample int
DECLARE @SQL nvarchar(4000)
DECLARE @ID int
DECLARE @Tabella sysname
DECLARE @RowCnt int
-- Filtro per database e la percentuale per il ricalcolo delle statistiche
SET @dbName = 'AdventureWorks2008'
SET @sample = 100
--Temporary Table
CREATE TABLE ## Tabelle
(
TabelleID INT IDENTITY(1, 1) NOT NULL,
TableName SYSNAME NOT NULL
)
--We feed the tabella con l'elenco di tabelle
SET @SQL = ''
SET @SQL = @SQL + 'INSERT INTO ##Tabelle (TableName) '
SET @SQL = @SQL + 'SELECT [name] FROM ' + @dbName + '.dbo.sysobjects WHERE xtype = ''U'' AND [name] <> ''dtproperties'''
EXEC sp_executesql @statement = @SQL
SELECT TOP 1 @ID = TableID, @Tabella = TableName
FROM ##Tabelle
ORDER BY TableID
SET @RowCnt = @@ROWCOUNT
-- Per ogni tabella
WHILE @RowCnt <> 0
BEGIN
SET @SQL = 'UPDATE STATISTICS ' + @dbname + '.dbo.[' + @Tabella + '] WITH SAMPLE ' + CONVERT(varchar(3), @sample) + ' PERCENT'
EXEC sp_executesql @statement = @SQL
SELECT TOP 1 @ID = TableID, @Tabella = TableName
FROM ##Tabelle
WHERE TableID > @ID
ORDER BY TableID
SET @RowCnt = @@ROWCOUNT
END
--Eliminare la tabella
DROP TABLE ##Tabelle
Cambiar en SQLServer 2008 la columna clave de una tabla a una nueva del tipo integer que sea identidad usando OVER
Cambiar en SQLServer 2008 la columna clave de una tabla a una nueva del tipo integer que sea identidad usando OVER il_masacratore 28 October, 2013 - 13:37Puede ser que en algun momento pueda ser necesario cambiar el tipo de columna clave para nuestra tabla/s por un mal diseño o un cambio posterior x que nos obliga a ello. Si lo hacemos y la nueva tiene que ser una columna del tipo entero, quizás identity, podemos hacerlo con algun criterio para que quede ordenado (pk=indice clusterizado=order by en disco por ese campo). En este ejemplo para hacerlo más completo, lo hacemos en dos tablas Maestro-Detalle donde los campos claves son de tipo nchar (CABECERAS.ID_CABECERA y LINEAS.ID_LINEA). Pasos a seguir...
- Empezamos por elegir el tipo de columna y la añadimos a la tabla principal, CABECERAS. Seguimos con un update que parte de una join con una select sobre la misma tabla incluyendo la función ROW_NUMBER() para el contador de linea que nos servira como valor autoincremental (identity?).
- A coninuacións seguimos con el detalle, LINEAS, donde hacemos lo mismo que antes con su propia PK. Para mantener el mismo orden hacemos una join con la tabla CABECERAS y aprovechamos también para asignar también el valor de la nueva foreign key.
Ahora que ya tenemos los nuevos candidatos a campo clave, los marcaremos como NOT NULL, como campo clave y optaremos si es necesario por ponerlos como identity. También modificaremos la FOREIGN KEY o añadiremos una nueva. Una forma muy fácil de hacer lo anterior es hacerlo de forma visual, usando Management Studio, en la parte de Diagramas de Bases de datos (en el árbol del Explorador de objetos).

Por cierto, si finalmente hace falta que las nuevas claves sea identity deberemos recuperar antes el valor máximo del campo en las dos tablas para asignar el valor inicial de la identidad. Si queremos ser más puristas, debemos saber que desde SqlServer 2012 existen las secuencias y ya podríamos hacer lo mismo usándolas. Es interesante saber por una eventual migración de tipo de base de datos. A saber, Oracle también permite el uso de secuencias pero no existe equivalente a campos identity. MySql en cambio si tiene identity y es AUTO_INCREMENT.
Como deshabilitar el autocommit en SQL Server Management Studio
SQL08: Come disabilitare autocommit in SQL Server Management Studio il_masacratore 27 April, 2010 - 11:07
Hai siete mai chiesti come autocommit disattivare in SQL Server Management Studio? La risposta è rapida. Che cosa si può modificare il menu selezionare Strumenti> Opzioni> Esegui la query> SQL Server> Ansi> IMPLICIT_TRANSACTIONS SET.

Sembra piuttosto semplice ma, come mi è stato chiesto un paio di volte ...
Como recuperar la clave del usuario sa en Sql Server 2008
Como recuperar la clave del usuario sa en Sql Server 2008 il_masacratore 23 October, 2013 - 11:54Hay muchas maneras de liarla con nuestra base de datos SqlServer y una de ellas es olvidar o no tener a nuestra disposición la clave del usuario sa. Puede ser debido a que nunca la usemos, porque tenemos nuestro propio usuario administrador y realmente no iniciamos sesión con esa cuenta. Puede ser que hayamos heredado esa maravillosa base de datos y no tengamos ningún usuario ni de dominio que sea administrador. O peor aún, que incluso desde el mismo día de la instalación no sepamos esa clave y acabamos de eliminar el único login con los permisos adecuados... Para cualquiera de estas historias tristes puede haber una solución que no sea reinstalar.
Desde SqlServer 2005 (y hasta SqlServer 2012 que yo sepa) existe, como plan de recuperación para este tipo de desastre, la posibilidad de arrancar la base de datos SqlServer en modo "single-user" y poder acceder a ella con cualquier usuario de miembro del grupo de administradores del sistema. Arrancar la base de datos en single-user está pensado para realizar tareas de mantenimiento, como por ejemplo aplicar patches y realizar otras tareas. En nuestro caso, donde hemos perdido la clave del usuario sa, nos permitirá, una vez limitado el acceso, conectarnos por ejemplo via sqlcmd y agregar un usuario de la base de datos al rol sysadmin dentro de Sql Server. A continuación un resumen...
Pasos a seguir:
- Abrimos el Administrador de Configuración de SqlServer. Buscamos el Servicio de SqlServer y miramos las Propiedades, en la pestaña Opciones Avanzadas o Parámetros de inicio añadimos un -m al final de la linea. (puede variar segun la versión). Presionamos aceptar y reiniciamos el servicio.
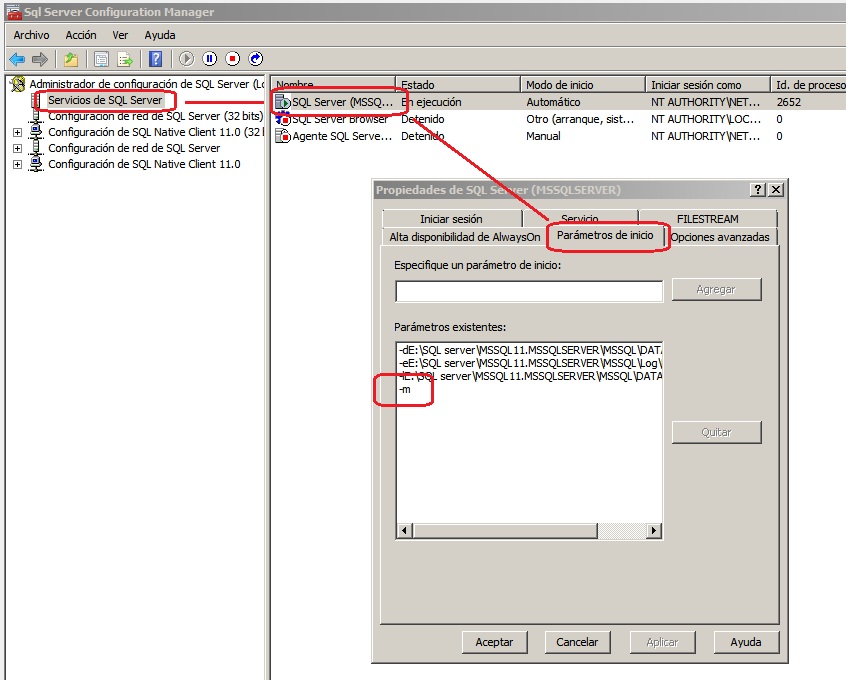
- Una vez reiniciado, abrimos la linea de comandos y el cliente sqlcmd. Ejecutamos lo siguiente:
sqlcmd -S localhost 1> EXEC sp_addsrvrolmember 'DOMINIO\Dba','sysadmin';
- Volvemos al Administrador de Configuración de SqlServer, quitamos el -m que hemos añadido en el primer punto y volvemos a reiniciar el servicio. Finalmente probamos de acceder con el usuario de dominio anterior y restauramos la clave del usuario sa (y la guardamos en lugar seguro). Misión cumplida.
Existe una variante sobre el uso del parámetro -m para arrancar la bbdd en modo usuario único, es -m"Nombre app" (En el nombre de la aplicación cliente se distinguen mayúsculas y minúsculas). Este uso del parámetro limita las conexiones a una aplicación cliente con el nombre especificado. Por ejemplo, -m"SQLCMD" limita las conexiones a una conexión única y esa conexión se debe identificar como el programa cliente SQLCMD. Se puede usar esta opción cuando estemos iniciando SQL Server en modo de usuario único y una aplicación cliente desconocida esté usando la única conexión disponible. Para limitarlo al Management Studio, usamos -m"Microsoft SQL Server Management Studio - Query".
Libros de SQL Server
¿Quieres profundizar más en Transact-SQL o en administración de bases de datos SQL? Puedes hacerlo consultando alguno de estos libros de SQL Server
Mejor revisa la lista completa de los últimos libros de SQL Server publicados en Amazon según lo que te interese aprender, pero estos son los que a mi me parecen más interesantes, teniendo en cuenta precio y temática:
- eBooks de SQL Server gratuítos para la versión Kindle, o muy baratos (menos de 4€):
- Libros recomendados de SQL Server
SQLServer 2008: Consulta uniendo datos de SSAS con los de una tabla de cualquier otra bbdd mediante openquery
SQLServer 2008: Consulta uniendo datos de SSAS con los de una tabla de cualquier otra bbdd mediante openquery il_masacratore 22 October, 2013 - 17:01En ocasiones podemos necesitar hacer un informe que debe contener datos de nuestro cubo de ventas (por ejemplo) y complementarlo con datos que nos faltan y que solo podemos encontrar en el esquema relacional del origen o directamente de otra fuente de datos.
Si la bbdd complementaria está en una instancia de sql server, una solución bastante comoda es crear un servidor vinculado. Eso nos permita hacer la consulta MDX desde la propia instancia de SQL Server y hacer una JOIN para conseguir los datos que no tenemos en el cubo. Si nos paramos a pensarlo, quizás no es lo más elegante e incluso puede ocultar alguna carencia de diseño, pero seguro que cosas peores hemos hecho.
A continuación los cuatro pasos a seguir para crear el servidor vinculado y la construcción de la query trivial para completar el total de ventas anual con el nombre del encargado de la tienda.
Primero preparamos la consulta MDX con los datos del cubo que podamos necesitar y un campo clave con el que luego podamos relacionar la otra tabla:
SELECT [Measures].[Sales amount] ON COLUMNS, [Business].[Store id].members ON ROWS FROM [Sales] WHERE [Time].[Year].&[2013]
Empezamos por ir al Explorador de objetos y buscamos en nuestra instancia el apartado Objetos del servidor>Servidores vinculados> Nuevo servidor vinculado. Complementamos con los datos de la instancia SSAS que corresponda.

Editamos la consulta sobre la instancia de Sql Server. Aquí encapsulamos la consulta MDX en una nueva consulta SQL con openquery. El tip aquí para facilitar la selección de campos es usar alias ya que por defecto el encabezado de la columna nos saldra con el formato mdx del atributo/medida. Luego simplemente hacemos la JOIN como queramos con la otra tabla y listos.
SELECT ssas.Store_id ,ssas.Sales_Amount ,store.manager FROM (SELECT "[Business].[Store id].[MEMBER_CAPTION]" as Store_id,"[Measures].[Sales amount]" AS Sales_Amount
FROM openquery( SSAS_INSTANCE, 'SELECT [Measures].[Sales amount] ON COLUMNS,
[Business].[Store id].members ON ROWS
FROM [Sales]
WHERE [Time].[Year].&[2013]')) ssas
LEFT JOIN [dbo].[Stores] store ON ssas.Store_id = store.Store_id
Create table condicionado usando el diccionario de datos de Sql Server 2008
Create table condicionado usando el diccionario de datos de Sql Server 2008 il_masacratore 13 May, 2011 - 14:54En ciertas ocasiones necesitamos comprobar la existencia de una tabla en un script o tarea programada para poder registrar eventos de erro, primeras ejecuciones etc... Pongamos un ejemplo, un paquete de integration services que solemos distribuir o ejecutar allà a donde vamos y que deja trazas en un tabla personalizada que no es la predefinida para los logs de carga. Podríamos incluir siempre una Tarea de ejecución sql o de script, que se ejecute bien o mal, sea la primera en ejecutarse en el paquete y luego continue. Siendo puristas esto solo no es del todo “prolijo”:
CREATE TABLE LogsEtl (Ejecucion int PRIMARY KEY, Paquete varchar(50), Fecha datetime); GO
En la primera ejecución la salida será correcta pero en posteriores fallará en la creación de la tabla. Esto lo podemos suplir consultando la vista sys.Objects, donde existe un registro por cada objeto de la base de datos, y comprobar la existencia de la tabla antes de crearla. La visibilidad de los metadatos se limita a los elementos protegibles y que son propiedad del usuario o sobre los que el usuario tiene algún permiso. La estructura de la vista es la siguiente:
name (sysname) object_id (int) principal_id (int) schema_id (int) parent_object_id (int) type (char(2)) type_desc (nvarchar(60)) create_date (datetime) modify_date (datetime) is_ms_shipped (bit) is_published (bit) is_schema_published (bit)
Si cambiamos la sentencia anterior por un create table condicionado por una consulta sobre la vista buscando por el nombre de la tabla como parámetro de object_id(función que devuelve el identificador único de un objeto por su nombre) tendremos algo así:
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[LogsEtl]') AND TYPE = N'U') CREATE TABLE LogsEtl (Ejecucion int PRIMARY KEY, Paquete varchar(50), Fecha datetime); GO
De esta manera lo estamos haciendo “prolijo” y la ejecución siempre será correcta (a no ser por la falta de permisos).
Realmente esto tiene otras aplicaciones porque podríamos hacer cualquier tipo de script condicionado por la existencia o no de objetos en la bbdd o modificación. Por ejemplo uno mismo podría hacer una consulta o script universal que actualizara/reconstruyera índices en base al tiempo que ha pasado desdela última modificación. Podríamos controlar a nivel de administración que esta “inventando” aquel usuario con permisos de más etc etc... en msdn hay algun ejemplo más.
Cómo solventar el error 'No se permite guardar los cambios' en SQL Server 2008
Cómo solventar el error 'No se permite guardar los cambios' en SQL Server 2008 il_masacratore 17 November, 2009 - 10:39Dado que es algo que se suele repetir y ya me lo han comentado más de una vez, creo oportuno crear un post donde se describa el problema y la solución en Sql server 2008 para newbies. Más que nada para que no perdaís tiempo buscando...
Problema:
Al modificar el tipo de campo en una tabla ya creada (pero vacía) o al añadir alguna clave foránea me aperece un mensaje como el siguiente:"No se permite guardar los cambios. Los cambios que ha realizado requieren que se quiten y se vuelvan a crear las tablas".
Ejemplo:

Solución:
Desmarcar la opción que impide hacer este tipo de cambios. Para ello debemos abrir la pantalla de opciones (Herramientas>Opciones), y en el apartado Designers>Diseñadores de tabla y base de datos desmarcar la opción Impedir guardar cambios que requieran volver a crear tablas. Captura:


Un tip muy útil
Pues sí, es algo muy tonto pero que si no lo sabes te deja bastante descolocado cuando empiezas con SQLServer
- Log in to post comments
Gracias ya lo había hecho
Gracias ya lo había hecho antes pero no recordaba.
- Log in to post comments
Nuevas bases de datos en nuestro servidor SQL Server 2008. Pensemos y evitemos valores por defecto
Nuevas bases de datos en nuestro servidor SQL Server 2008. Pensemos y evitemos valores por defecto il_masacratore 30 November, 2010 - 14:24
Con SQL Server podemos caer muy fácilmente en lo que se dice habitualmente sobre los productos Microsoft "Siguiente, siguiente y listo". No vamos a negarlo, Microsoft consigue hacer que gente sin mucha idea salga adelante y es todo un mérito. Pero vayamos al tema. Si se empieza una nueva aplicación y tenemos que crear la estructura de datos, no dejemos solos a los desarroladores y tampoco que usen el MS Management Studio. Normalmente, en lo que a la base de datos se refiere, cuando se crean se tienen en cuenta varias cosas:
- Ajuste adecuado de los tipos de datos para cada columna
- Foreign Keys e índices
- Tamaños por defecto en ficheros de log
- Fillfactor en los índices
Los dos primeros puntos son las buenas prácticas que se suelen comentar pero poca cosa podemos hacer como administradores de la base de datos, más que asegurarnos que tiene lugar y ayudar si es necesario. Además el tema índices es algo que se puede plantear más tarde. Pero de los dos últimos puntos somos los responsables. Deberíamos conocer el tipo de aplicación, el uso que tendrá(lect/escr) y estimar el volumen de crecimiento de los datos para poder aportar nuestro granito de arena.
Inicialmente podemos ajustar el tamaño de los archivos de la base de datos (propiedades de la base de datos). Si esperamos montar una base de datos que crecerá muy rápido incrementaremos el tamaño inicial si hace falta y ajustaremos el crecimiento de los archivos de Registro(.ldf) y de Datos de filas (.mdf). Si por el contrario es pequeña podríamos dejar los valores por defecto. Ajustando este valor evitaremos diseminar los datos por el disco (son las dos imágenes de abajo).
Otro tema a tener en cuenta y que también tiene impacto es jugar con los valores de fillfactor de los índices, en base también al porcentaje de lectura/escritura y el volumen de datos.

Archivos de la base de datos

Configuración del crecimiento automático.
Eso entre otras cosas de las que ya hablaré. También es interesante que si tenemos poco espacio en disco para datos y ya no vale solo con el SHRINKFILE para vaciar logs, ante una situación de crisis podemos jugar con las prioridades y poner límites en el crecimiento automático para ciertas bases de datos que crecen de forma desmesurada ...
Politíca de backup simple para SQL Server 2008. BACKUP y RESTORE
Politíca de backup simple para SQL Server 2008. BACKUP y RESTORE il_masacratore 1 February, 2010 - 13:37A continuación dejo un par de ejemplos de como funciona el backup simple de sqlserver 2008 y como hacer un restore. En el primer ejemplo hacemos un drop de la base de datos que en un entorno real puede significar la perdida de un datafile o disco etc etc. El segundo ejemplo es algo más rebuscado y lo que se hace es restaurar la copia de la base de datos para recuperar una tabla y extraer sus datos. En ambos ejemplos se trabaja con bases de datos de ejemplo descargables aquí.
Ejemplo 1. BACKUP Y RECUPERACION SIMPLE EN CASO DE PERDIDA DE LA BASE DE DATOS
En el siguiente ejemplo se hace una copia simple y una diferencial de la base de datos AdventureWorks2008. Una vez hecho se hace un drop de la base de datos para luego restaurar la base de datos al último estado antes de borrar la base de datos.
USE master;
--Modo de recuperació simple para la base de datos en cuestion
ALTER DATABASE AdventureWorks2008 SET RECOVERY SIMPLE;
GO
--Backup simple
BACKUP DATABASE AdventureWorks2008 TO DISK='F:\SQL08\BACKUPDATA\AW2008_Full.bak'
WITH FORMAT;
GO
--Backup diferencial
BACKUP DATABASE AdventureWorks2008 TO DISK='F:\SQL08\BACKUPDATA\AW2008_Diff.bak'
WITH DIFFERENTIAL;
GO
--Destrucción!!!!
DROP DATABASE AdventureWorks2008;
GO
--Restauración del último backup
RESTORE DATABASE AdventureWorks2008 FROM DISK='F:\SQL08\BACKUPDATA\AW2008_Full.bak'
WITH FILE=1, NORECOVERY;
--Restauración de los diferenciales
RESTORE DATABASE AdventureWorks2008 FROM DISK='F:\SQL08\BACKUPDATA\AW2008_Diff.bak'
WITH FILE=1, RECOVERY;
Para este ejemplo cabe destacar que cada vez que restauramos utilizamos la opción NORECOVERY hasta importar el último fichero. También es bueno saber que el parámetro WITH FILE=X indica que "fichero" se importa. En el caso de que estuvieramos añadiendo al primer fichero la copia diferencial en lugar de crear un nuevo fichero, en el momento de restaurar el segundo fichero deberíamos poner WITH FILE=2. Por último, WITH FORMAT elimina el contenido en lugar de añadir.
Ejemplo 2. BACKUP Y RECUPERACIÓN SIMPLE EN CASO DE PERDIDA DE UNA TABLA
Este es el típico caso en el que en una base de datos conviven distintas aplicaciones y hemos perdido alguna tabla o se han hecho modificaciones que requieren recuperar datos. En este caso es posible que por ello no podamos restaurar la base de datos actual con la copia. A continuación muestro como recuperar la base de datos en una nuevo con otro fichero y otro nombre para poder traspasar o comprobar datos:
Partimos de un caso como el anterior donde se tiene una copia full y diferenciales. Suponemos que sabemos cuando se ha producido el error.
USE master;
--Modo de recuperació simple para la base de datos en cuestion
ALTER DATABASE AdventureWorksDW2008 SET RECOVERY SIMPLE;
GO
--Backup simple
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008.bak'
WITH FORMAT;
GO
--Creación de tabla
CREATE TABLE AdventureWorksDW2008.dbo.Prueba
(
F1 char(2000),
F2 char(2000)
)
--Backup diferencial
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008_D1.bak'
WITH DIFFERENTIAL;
--Drop de la tabla
DROP TABLE AdventureWorksDW2008.dbo.Prueba;
--Segundo backup diferencial
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008_D2.bak'
WITH DIFFERENTIAL;
GO
--Restauración del último backup completo en otra base de datos
RESTORE DATABASE AdventureWorks2008DWTemp FROM DISK='F:\SQL08\BACKUPDATA\AWDW2008.bak'
WITH FILE=1,
MOVE N'AdventureWorksDW2008_Data' TO 'F:\SQL08\DATA\MSSQL10.TEST\MSSQL\DATA\AdventureWorksDW2008Temp_Data.mdf',
MOVE N'AdventureWorksDW2008_Log' TO 'F:\SQL08\DATA\MSSQL10.TEST\MSSQL\DATA\AdventureWorksDW2008Temp_Log.mdf',
NORECOVERY;
--Restauración de los diferenciales
RESTORE DATABASE AdventureWorks2008DWTemp FROM DISK='F:\SQL08\BACKUPDATA\AWDW2008_D1.bak'
WITH FILE=1,
RECOVERY;
Este segundo caso sería más sencillo en un entorno donde se incluyera copia de los ficheros de transacciones y pudieramos hacer una restauración point-in-time.
El código que aquí encontramos perfectamente se puede partir y podemos programar ya las copias (full y/o diferenciales) en jobs del agente de sql server. Por ejemplo podríamos hacer la copia full el domingo y de lunes a sabado seguir con los diferenciales, pero esto también se puede programar usando SQL Server Management Studio y hacerlo de forma visual (aunque saber hacerlo desde código no está de más)...
Sincronización de la base de datos de Microsoft Dynamics AX 2009 sobre Sql Server 2008
SQL08: Sincronizzazione dei database di Microsoft Dynamics AX 2009 su SQL Server 2008 il_masacratore 14 April, 2010 - 11:09Per coloro amministratori di database che hanno a che fare con una tale Dynamics AX 2009 ei suoi scagnozzi (sviluppatori, consulenti, ecc  Lascio qui un paio di cose che dovreste sapere (o dovrei dire) quando ci uniamo ax2009 e SQL Server 2008. A volte si può puntare al database come fonte del problema, ma non sempre. Alcuni requisiti di prendere in considerazione per l'installazione di Ax2009 sono che l'utente che si vuole accedere al sistema dovrebbe essere utente e il dominio nel ruolo di SQL Server deve essere un membro di dbcreator e securityadmin e creare il nuovo database di installazione Ax. Una volta installato (o durante il processo di installazione) il problema con il database che possiamo trovare sono:
Lascio qui un paio di cose che dovreste sapere (o dovrei dire) quando ci uniamo ax2009 e SQL Server 2008. A volte si può puntare al database come fonte del problema, ma non sempre. Alcuni requisiti di prendere in considerazione per l'installazione di Ax2009 sono che l'utente che si vuole accedere al sistema dovrebbe essere utente e il dominio nel ruolo di SQL Server deve essere un membro di dbcreator e securityadmin e creare il nuovo database di installazione Ax. Una volta installato (o durante il processo di installazione) il problema con il database che possiamo trovare sono:
Caso 1:
Un altro problema noto in sincronizzazione dei dati può essere causato dalla mancanza di autorizzazioni. Il messaggio è questo:
"Cannot execute a data definition language command on ().
The SQL database has issued an error.
Problems during SQL data dictionary synchronization.
The operation failed.
Synchronize failed on 1 table(s)"
Questo caso particolare è stato risolto dando i permessi db_ddladmin sul database in questione. Secondo il documento ufficiale di setup Dynamics Ax 2009 AOS utente deve avere la db_ddladmin, db_datareader, e db_datawriter sul tuo permesso di lavoro-database tutto correttamente.
Caso 2:
Ax2009 può essere che in aggiunta di un campo in una tabella non può trovare riscontro nel database, ma nel AOT
Axapta. Se si tratta di qualcosa che si verifica solo nel campo, o meglio con quel tipo di campo (Extended Data Type) database non ha nulla da fare. Il problema è probabilmente che la funzionalità di appendere questo tipo di campo è disabilitato. Questo di solito accade in un impianto nuovo, che non è stato attivato a tutti (Grazie Alessandro per l'aiuto!!  ).
).
In un altro post spero di discutere quali passi da seguire quando si sincronizza un Ax tabella.
Cómo montar dos entornos en un mismo servidor SQL Server 2008 sin que se "pisen"
SQL08: affinity_mask, io_affinity_maske come andare due su un singolo server ambienti senza essere "camminato" il_masacratore 19 April, 2010 - 11:32Ci siamo messi in posizione
Nel nostro ambiente si può avere bisogno di avere due repliche di uno/s database in ambienti diversi (l'esempio classico sarebbe di produzione e di test). Nel decidere come facciamo noi le domande più comuni che dobbiamo porci sono le seguenti:
- È questo nuovo ambiente sarà temporanea? Il vaste basi di dati in termini di volume e / o il carico a carico è elevato (anche di prova)?
- C'è SqlServer2008 versione di sviluppo? Ma questo da solo è a portata di mano se si ha un abbonamento MSDN ...
- C'è un server in più?
Sulla base di queste domande e tutto quello che può accadere si può optare per diverse soluzioni:
"Il modo più semplice e se il database di portare il peso sono di piccole dimensioni si può utilizzare il server stesso per tutti i database (creati sullo stesso server con nomi diversi (_test) e santa Pasqua ...). Per non disturbare l'altro possiamo usare Resource Governor.
"Il più" asettico ", se le risorse lo consentono e dove varrebbe la pena di montare su server diversi (se abbiamo la versione di sviluppo)
"Un'altra possibilità è una miscela di cui sopra. Montare i due ambienti sullo stesso server, ma istanze diverse.
-Ecc ...
1 n cpu server (n> 1) + 2 = 2 ambienti istanze
Una opzione che mi piace di quanto sopra è il terzo, dove abbiamo montato due istanze per separare i due ambienti e si imposta l'affinità del processore per il controllo della dedizione di ogni processore per ogni istanza. Dobbiamo inoltre controllare la memoria assegnata a ciascuna istanza (la memoria del server e la memoria massima del server).
Esempio:
In un-core server dedicato 6 2 dei quattro processori in servizio l'ambiente di test, mentre i restanti 6 sono stati premiati l'ambiente di produzione. Per farlo dobbiamo solo aprire il SSMS e le proprietà del server: XXXX, nella parte di processori ogni processore attivare manualmente (deselezionando l'assegnazione automatica). Visualizza immagine.

E 'bene sapere anche che siamo in grado di allocare e rilasciare la convenienza in quanto è possibile variare dinamicamente per ogni istanza. Se necessario, cambiare fa bene, se la capacità di carico è sopra di noi. Ma non tutto è oro quello che luccica, e sappiamo che quando si gestisce due istanze sono già consumano di più che se gestionáramos uno solo.
Concetti: affinity mask, affinity io mask
Cómo habilitar conexiones remotas a un servidor SQL Server sobre Windows
Cómo habilitar conexiones remotas a un servidor SQL Server sobre Windows Carlos 4 March, 2020 - 20:23Tras la instalación de un servidor SQL Server en una máquina con Windows Server, el siguiente paso lógico es configurarlo para permitir conexiones remotas a la base de datos desde otros equipos.

Para ello hay que utilizar primero el Administrador de configuración de SQL Server para habilitar el protocolo TCP/IP sobre la dirección IP del server, y después abrir los puertos necesarios (el 1433 por defecto), desde el Firewall de Windows.
Estos son los pasos básicos que yo suelo seguir, probando a conectar desde una máquina cliente como mi PC o portátil al servidor.
Comprobar que hay conexión entre el cliente y el servidor (ip 192.168.1.116)
Nunca está de más comprobar con un simple ping que hay conectividad entre las dos máquinas abriendo una consola de comandos (cmd) desde el cliente:
C:\Users\Administrador>ping 192.168.1.116 Pinging 192.168.1.116 with 32 bytes of data: Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128
(Pruebo todo directamente con la IP para descartar posibles problemas de resolución de nombres de servidor)
Comprobar con telnet que no esté abierto ya el puerto
Telnet se utiliza también desde la linea de comandos. Si tienes windows 10 y no lo tienes activado consulta aqui cómo habilitarlo.
En este ejemplo utilizamos el puerto por defecto de SQL Server 1433, aunque para más seguridad es recomendable utilizar puertos diferentes, pero ese es otro tema..
C:\Users\Administrador>telnet 192.168.1.116 1433 Connecting To 192.168.1.116...Could not open connection to the host, on port 1433: Connect failed
Habilitar el protocolo TCP/IP sobre la dirección IP del server
Abrir en el servidor el programa Administrador de configuración de SQL Server (Sql Server Configuration Manager), desde el menú de aplicaciones de SQL Server, o buscando el programa en el buscador del server.

Una vez abierto, en el menú de la izquierda, en 'Configuración de red de SQL Server', Seleccionar 'Protocolos de [Nombre de la instancia]', y hacer doble click sobre el Nombre de protocolo TCP/IP para acceder a sus propiedades y seleccionar 'Si' en 'Habilitado', y en la pestaña de Direcciones IP, seleccionar también 'Si' en 'Habilitado' de la IP del server, este caso 192.168.1.116, y asegurarse de que el puerto es correcto (en este caso 1433 ya estaba bien porque es el puerto por defecto, pero si no hay que modificarlo)

Después de estas modificaciones hay que reiniciar el servicio principal de SQL Server desde la misma aplicación, en el menú 'Servicios de SQL Server'
Abrir el puerto TCP desde el Firewall de Windows Server
El siguiente paso es abrir la aplicación Firewall de Windows, desde el panel de control (Panel de control\Sistema y seguridad\Firewall de Windows), o buscando Firewall en el buscador de aplicaciones.
Una vez abierto, seleccionar 'Configuración avanzada' en el menú de la izquierda, y después, en el menú hacer click con el botón derecho sobre 'Reglas de entrada', y seleccionar 'Nueva Regla' (También se puede hacer desde la opción de menú 'Acción')

Seleccionar regla tipo 'Puerto', y después 'TCP', y escribir 1433 en la opción 'Puerto específico local'. Esta es la configuración más sencilla, y sirve si esta es la única instancia de SQL Server instalada en el Servidor Windows.

Si hubiera más instancias sería necesario abrir más puertos, activar el servicio SQL Server Browser, y abrir otro puerto UDP, y también crear una nueva regla personalizada en el firewall para el servicio.
Seleccionando las siguientes opciones (normalmente las que vienen por defecto ya van bien) se finaliza la creación de la regla del firewall, y el telnet por el puerto 1433 desde la máquina cliente ya debería responder:
C:\Users\Administrador>telnet 192.168.1.116 1433

Una vez que el telnet responde, ya se podrá conectar con SQL Server Management Studio u otra aplicación cliente, al menos por IP ;)
Administración de Microsoft SQL Server 2014
Administración de Microsoft SQL Server 2014 Dataprix 23 May, 2014 - 19:29Automatizando el backup y restore de una base de datos SQL Server 2014 usando PowerShell
Automatizando el backup y restore de una base de datos SQL Server 2014 usando PowerShell il_masacratore 14 November, 2013 - 10:38![]()
Igual que en servidores Linux donde tenemos bases de datos MySql y Oracle automatizamos tareas banales mediante scripts en bash, en los servidores donde tengamos Windows Server podemos apañarnos con Windows Power Shell. Como administradores de las bases de datos Sql server, puede interesar saber algo de scripting en este lenguaje para llegar más lejos que con el Agente de Sql Server y sus trabajos. También es cierto que podemos profundizar todo lo que queramos, empezando con Server Management Objects para interactuar con SQL Server (requiere conocimientos mínimos de .NET y POO) e incluso pudiendo combinarlo con WMI para consultar información relativa al sistema operativo.
En este ejemplo de script Power Shell (extensión .ps1) voy a hacer algo sencillo que será refrescar la base de datos del entorno de desarrollo desde una copia que haremos de la base de datos de producción. En mi caso, esto me tiene que permitir elegir si refrescar el entorno de desarrollo o el entorno de test. Lo bueno de PowerShell es que podemos incluir dentro del mismo script .ps1 comandos de la propia linea de comandos de dos.
Antes de empezar abriremos la consola de power shell. Para probar y poder ejecutar scripts desde la consola scripts seguramente hemos de permitirlo ya que por defecto la directiva deshabilita esta opción. Consultamos y modificamos el la restricción con los comandos Get-ExecutionPolicy y Set-ExecutionPolicy:

Este script está pensado para ejecutarlo desde el servidor de desarrollo. Para hacerlo más "universal", haré primero una consulta para saber los nombres de la bases de datos accesibles de producción, pidiendo previamente servidor al que conectarse, usuario y clave. Después permito introducir el nombre de la elegida.
*** $SQLServerOrigen = read-host "Nombre del servidor origen" $SQLUserOrigen = read-host "Usuario bbdd origen" $SQLClaveUserOrigen = read-host "Clave" $SqlQuery = "select name from master.dbo.sysdatabases order by 1 asc" $SqlConnection = New-Object System.Data.SqlClient.SqlConnection $SqlConnection.ConnectionString = "Server = $SQLServerOrigen; User id=$SQLUserOrigen; Password=$SQLClaveUserOrigen" $SqlCmd = New-Object System.Data.SqlClient.SqlCommand $SqlCmd.CommandText = $SqlQuery $SqlCmd.Connection = $SqlConnection $SqlAdapter = New-Object System.Data.SqlClient.SqlDataAdapter $SqlAdapter.SelectCommand = $SqlCmd $DataSet = New-Object System.Data.DataSet $SqlAdapter.Fill($DataSet) $SqlConnection.Close() clear $DataSet.Tables[0] echo "" $BBddOrigen = read-host "Base de datos de $SQLServerOrigen a copiar" ***Para hacer la copia, en esta primera versión uso el cliente sql de la linea de comandos (sqlcmd) y un sql a pelo montado de forma dinámica para hacer el backup de solo copia en una ruta fijada. Montaré una unidad de red temporal para hacer la copia, se copia, se desmonta la unidad y se lanza de nuevo desde sqlcmd el restore (mapeando y hardcodeando la nueva ruta por la distinta ubicación de los .mdf y .ldf). Finalmente elimino el fichero.
*** sqlcmd -S $SQLServerOrigen -U $SQLUserOrigen -P $SQLClaveUserOrigen -Q "BACKUP DATABASE [$BBddOrigen] TO DISK = N'F:\Backup\$BBddOrigen\$BBddOrigen.temp.bak' WITH COPY_ONLY" echo "\\$SQLServerOrigen\F$\Backup\$BBddOrigen\" Net Use T: \\$SQLServerOrigen\F$\Backup\$BBddOrigen Copy-Item T:\$BBddOrigen.temp.bak C:\$BBddOrigen.temp.bak Remove-Item T:\$BBddOrigen.temp.bak Net Use T: /delete $BBddDestino = read-host "Base de datos destino" SQLCMD -E -S localhost -Q "RESTORE DATABASE $BBddDestino FROM DISK='C:\$BBddOrigen.temp.bak' WITH FILE=1, MOVE N'$BBddOrigen' TO 'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\$BBddDestino.mdf', MOVE N'${BBddOrigen}_log' TO 'C:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\$BBddDestino.ldf' " #En la cadena de texto anterior, BBDDOrigen va entre {} para poder escapar el '_' acompañado del nombre de la variable y no interprete el _log como parte del nombre de la misma Remove-Item C:\$BBddOrigen.temp.bak ***En el script anterior, en lugar de usar sqlcmd para hacer el backup, podríamos haberlo hecho usando SMO (Server Management Objects). En este caso, el equivalente al sqlcmd sería algo parecido a lo siguiente:
[System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SMO") [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoExtended") [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.ConnectionInfo") [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoEnum") #Preparamos el servidor y cargamos tb el directorio de backup $server = New-Object ("Microsoft.SqlServer.Management.Smo.Server") "($SQLServerOrigen)" $backupDirectory = $server.Settings.BackupDirectory $db = $server.Databases[$dbToBackup] $dbName = $db.Name $timestamp = Get-Date -format yyyyMMddHHmmss $smoBackup = New-Object ("Microsoft.SqlServer.Management.Smo.Backup") $smoBackup.Action = "Database" $smoBackup.BackupSetDescription = "Full Backup of " + $dbName $smoBackup.BackupSetName = $dbName + " Backup" $smoBackup.Database = $dbName $smoBackup.MediaDescription = "Disk" $smoBackup.Devices.AddDevice($backupDirectory + "\" + $dbName + "_" + $timestamp + ".bak", "File") $smoBackup.SqlBackup($server) #Obtenenmos la lista de ficheros en el directorio de backup para luego filtrar y mostrar los .bak $directory = Get-ChildItem $backupDirectory $backupFilesList = $directory | where {$_.extension -eq ".bak"} $backupFilesList | Format-Table Name, LastWriteTimeLa gracia de usar los SMO es la complejidad. Seguramente segun el objeto podremos profundizar algo más y modificar parámetros y obtener información que no conseguiriamos de otra manera. Este trozo de código de arriba, a diferencia del sqlcmd está usando la ruta definida por defecto para los backups del propio sqlserver en lugar de hardcodearla. Ciertamete no es un avance pero ya vemos que la interacción es mejor. Si seguimos con SMO, el equivalente al restore con sqlcmd donde se permite elegir el nombre de la base de datos destino y se renombran los ficheros. Sería algo parecido a lo siguiente:
#Librerias... [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SMO") | Out-Null [System.Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoExtended") | Out-Null [Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.ConnectionInfo") | Out-Null [Reflection.Assembly]::LoadWithPartialName("Microsoft.SqlServer.SmoEnum") | Out-Null $backupFile = 'C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\Backup\test.bak' $server = New-Object ("Microsoft.SqlServer.Management.Smo.Server") "(local)" $backupDevice = New-Object("Microsoft.SqlServer.Management.Smo.BackupDeviceItem") ($backupFile, "File") $smoRestore = new-object("Microsoft.SqlServer.Management.Smo.Restore") #Propiedades de la restauracion $smoRestore.NoRecovery = $false; $smoRestore.ReplaceDatabase = $true; $smoRestore.Action = "Database" $smoRestorePercentCompleteNotification = 10; $smoRestore.Devices.Add($backupDevice) #Nombre de la nueva bbdd $BBddDestino = read-host "Base de datos destino" $smoRestore.Database =$BBddDestino #Nuevos ficheros... $smoRestoreFile = New-Object("Microsoft.SqlServer.Management.Smo.RelocateFile") $smoRestoreLog = New-Object("Microsoft.SqlServer.Management.Smo.RelocateFile") $smoRestoreFile.LogicalFileName = $BBddDestino $smoRestoreFile.PhysicalFileName = $server.Information.MasterDBPath + "\" + $BBddDestino + "_Data.mdf" $smoRestoreLog.LogicalFileName = $BBddDestino + "_Log" $smoRestoreLog.PhysicalFileName = $server.Information.MasterDBLogPath + "\" + $BBddDestino + "_Log.ldf" $smoRestore.RelocateFiles.Add($smoRestoreFile) $smoRestore.RelocateFiles.Add($smoRestoreLog) #Restauracion $smoRestore.SqlRestore($server)

En conclusión...
...invirtiendo un poco de tiempo la ganancia futura puede ser mayor. Podemos ahorrar mucho tiempo en tareas repetitivas o hacer verdaderas obras de arte que permitan hacer cosas más viriles. Por ejemplo algo como desactivar el reflejo del mirror en una base de datos reflejada para tenerla preparada en pocos segundos. Recrear el mismo reflejo de forma automática (o a un solo intro). Podemos reinventar la rueda y monitorizar nosotros determinados aspectos de nuestro propio servidor y tener nuestra propia versión de los hechos (sin contar la del departamento de sistemas...).
Como configurar el almacén de administración de datos y su recopilación en SQL Server 2014
Como configurar el almacén de administración de datos y su recopilación en SQL Server 2014 il_masacratore 30 December, 2013 - 10:44El recopilador de datos es una parte de MS Sql Server que permite recopilar diferentes tipos de datos y métricas sobre el rendimiento y desempeño de la base de datos. Se incluye desde la versión 2008 de SqlServer hasta la 2014 y esta formado por un conjunto de trabajos que se ejecutan mediante el agente de Sql Server periódicamente o de forma continua. Su configuración esta formada por dos sencillos pasos mediante asistente. Una vez finalizados ya podemos explotar su información mediante los informes incluidos.
Configurar el almacén de administración de datos
Para configurar el Almacén de Administración de Datos nos conectamos a SQL Server mediante Management Studio con un usuario administrador. En el árbol del Explorador de Objetos, iremos a Administración>Recopilación de datos y seleccionamos Configurar almacén de administración de datos. Esto iniciará un asistente del tipo Siguiente>Siguiente...

En el primer paso elegiremos la primera opción. Ésta configura la base de datos "almacén" donde se guardan los datos recogidos por los recopiladores (que configuramos en un paso posterior, seleccionando la segunda opción de este mismo punto del asistente).

Siguiendo con la primera opción (la de configurar el almacén), nos encontraremos primero con la elección del nombre para la nueva base de datos y el servidor donde estará. El servidor será el mismo servidor y no podemos cambiarlo, pero para la base datos podemos elegir una ya existente o podemos crear una nueva pulsando Nuevo. Elegir una existente podría tener sentido si ya tenemos una ya creada para este propósito o con temas relacionados de administración. Si creamos una nueva base de datos es interesante desactivar de por sí el seguimiento y dejarlo como simple. Hemos de pensar que dependiendo de la cantidad de datos a recopilar o la actividad sobre el servidor puede suponer más una molestia en el consumo de recursos que otra cosa.
El el siguiente paso debemos elegir que inicios de sesión pertenecen a cada rol propio de este compenente. Lo normal puede ser que usemos uno de sistema, el mismo del agente o directamente creemos uno nuevo con los permisos necesarios si nos interesa aislar la carga producida de forma rápida. El nuevo usuario lo creamos desde el botón del panel inferior. A continuación le asignamos los permisos sobre la base de datos.

Pulsamos siguiente y entonces nos aparecerá el resumen de la configuración que hemos hecho a modo de confirmación. Pulsamos de nuevo siguiente si estamos conformes y esperamos un resultado como este donde todo es correcto.

Configurar recopilación de datos
Ahora que ya tenemos la base de datos, nos falta configurar los recopiladores. Como he comentado antes, configuramos el recopilador de datos desde el mismo punto del explorador de objetos (Administración>Recopilador de datos> Configurar el almacén de administración de datos) pero esta vez seleccionamos en el segundo paso del asistente la opción inferior: Configurar recopilación de datos.
Una vez empezado el asistente, y ya en el tercer paso elegimos donde está hospedado el almacén de datos (la base de datos que hemos creado antes). Pulsamos de nuevo siguiente y nos aparece de nuevo el resumen de configuración y de los pasos a realizar. Estos incluyen habilitar la recopilación de datos y su inicio. Con todos estos pasos ya tenemos todo configurado y en marcha.

Recopiladores incluidos e informes incluidos
Por defecto, mediante los dos pasos anteriores conseguimos la creación de los tres recopiladores:
- Actividad del servidor: Cpu, memoria, etc...
- Estadísticas de consultas: Consultas, esperas, etc...
- Uso de disco: Evolución del espacio ocupado por cada bases de datos.
La parte más interesante son también los informes que se incluyen. Para poder acceder a ellos podemos hacerlo desde SQL Server Management Studio navegando por el árbol del Explorador de objetos, botón derecho en la base de datos almacén y seleccionamos informes del Almacén de Administración. Se abrirá una nueva pestaña y en el panel principal ya seleccionamos lo que queremos ver y el intervalo de fechas. Podemos consultar:
-
Resumen de uso de disco: Este informe muestra por cada base de datos el espacio que ocupan sus ficheros de datos y registro y la tendencia. Útil para ver comportamientos anómalos o hacer estimaciones sobre la necesidad de espacio en disco.
-
Historial de estadísticas de consultas: Del intervalo seleccionado muestra las consultas ordenadas de mayor a menor impacto por CPU, Duración etc... Lo vemos en un gráfico y en una tabla donde se muestra también el número de ejecuciones, duración, lecturas, escrituras.
-
Historial de actividad del servidor: Vista general del servidor donde podemos ver el uso de cpu, memoria, disco y red en la parte superior. en la parte media podemos ver otro gráfico con los tipos de esperas de SQL Server. En la parte inferior vemos un resumen de actividad con las conexiones, batch request etc. De estos dos últimos podemos ver más detalle haciendo clic sobre ellos.

De estos tres informes, del que podemos sacar mas jugo es el tercero porque nos da un estado general de la base de datos en el tiempo y nos permite indagar de manera superficial que se estaba ejecutando y durante cuanto tiempo. Por ejemplo, podemos detectar picos de actividad consultando el tercer gráfico. Observando el segundo podemos ver cual puede ser el origen de la lentitud según el mayor tipo de espera que veamos en el gráfico.
En resumen...
... este componente puede resultar útil por falta de alternativas dentro de la misma instalación de SqlServer y complementa los cuatro informes iniciales que pueden venir por defecto. Además, supone una alternativa auto-configurada para recopilar los mismos contadores que recoge el monitor de rendimiento del sistema. Es muy interesante la posibilidad de tener una foto del estado del servidor en un intervalo de tiempo anterior y verlo de forma gráfica.
Además, si queremos ir más allá podemos crear nuestros propios informes para explotar esta base de datos. Lo podríamos hacer con Report Builder o Business Intelligence Developer Studio y el punto de partida pueden ser las tablas snapshots.performance_counter_instances y snapshots.performance.counter_values. Ahí podemos ver los valores recogidos que podemos ver en cualquier momento consultando el monitor de rendimiento del sistema.
Buena información ya que
Buena información ya que cuando nos falten alternativas auto-configurada para recopilar los mismos contadores que recoge el monitor de rendimiento del sistema.
- Log in to post comments
Como instalar SQL Server 2014
Como instalar SQL Server 2014 il_masacratore 30 October, 2013 - 09:13… para empezar a probar las nuevas características que tenemos desde la versión 2008 de SqlServer.
Desde entonces ha llovido mucho, de hecho, la release date fue el 6 de agosto de 2008, y particularmente me interesa empezar a probar nuevas implementaciones ya sean novedad en la versión SQL Server 2014 o la anterior, la de 2012. Por ahora empiezo con esta serie de post sobre la nueva, primero con lo más básico que es como instalarlo para empezar a probar. Después en otros posts, comentaré seguramente pruebas de rendimiento con la nueva posibilidad de trabajar con tablas en memoria y cosas más bonitas o tangibles como el uso de Power View (ahora también contra ssas).
Este paso a paso resumido está hecho con la segunda versión preliminar de SQL Server 2014. Si queréis algo más completo tenéis algo más completo en la MSDN, pero quizás es más tedioso. Otras cosas podrán cambiar en la versión definitiva, pero el modo de instalación no lo creo. Así que vamos al lío. En mi caso la instalaré en una máquina virtual con Windows Server 2008 Enterprise, y por aquí abajo os comento cuatro sobre la marcha como instalarlo:
- Una vez cargada la ISO/CD lanzamos el instalador. Nosotros queremos una nueva instancia de bbdd. Nos vamos al apartado de Instalación y agregamos una nueva instancia (captura inferior). Pulsamos Siguiente y nos pide la clave, que introducimos si toca y pulsamos siguiente de nuevo.

- Seguimos con la licencia (que aceptamos, claro) y después seguimos con los validación de requisitos. Seguramente si probáis sobre una máquina virtual os falle la parte de “Actualización de .NET 2.0 y .NET 3,5 Service Pack 1 para...”. No pasa nada. Miramos el detalle del error y nos bajamos el paquete que nos especifica para nuestro sistema operativo. Más adelante también se comprueba si tentemos habilitado Windows PowerShell 2.0 y el NetFramework 3.5 Sp1. Lo instalamos todo y volvemos a empezar.
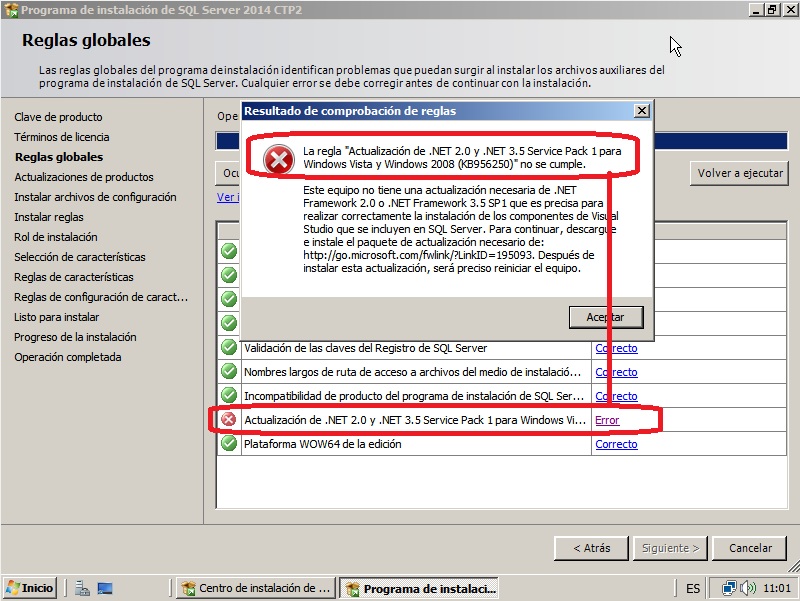
- Cuando lleguemos al mismo punto, se pone a buscar actualizaciones, lo dejamos si hace falta y pasamos al siguiente paso que es otra validación, en este caso de reglas (firewall etc..). Si está habilitado nos advertirá (captura inferior). Posteriormente podemos añadir los puertos de sql o deshabilitarlo si lo creyéramos preciso.

- Seguimos con el Rol de la instalación donde seleccionamos Instalación de características de SQL Server. Siguiente y ya podemos elegir lo que vamos a instalar (en mi caso para probar las tablas en memoria y Power View es lo que veis en pantalla: motores de base de datos y analisys services, conectividad de cliente y herramientas de administración).

- A continuación podemos configurar el nombre de la instancia (dejamos el valor por defecto si es la primera en este servidor). Después elegimos las cuentas de ejecución para cada servicio. Podemos dejar los cuentas por defecto o alguna otra cuenta, pero la gracia aquí es aplicar aquello de que la cuenta tenga los permisos justos y necesarios. Pulsamos siguiente.

- En la configuración de cada servicio (en mi caso el motor y analisys services) debemos recordar añadir algun usuario al grupo de administradores. Además debemos elegir si toca, el tipo de autentificación para los usuarios.

- Pulsamos siguiente y ya tenemos el resumen final de lo que vamos a instalar. Siguiente y a esperar. Cuando acabe reiniciamos y listos!
Ya tenemos nuestro SQL Server 2014 a punto para empezar a probar...
Monitorización de SQL Server 2014 mediante contadores de rendimiento
Monitorización de SQL Server 2014 mediante contadores de rendimiento il_masacratore 12 December, 2013 - 13:33
 Una de las tareas básicas en la administración de bases de datos es la monitorización de nuestro servidor y nuestra base de datos. Para servidores Windows con SQL Server una de las maneras más básicas (y gratuitas) es hacerlo mediante los contadores de rendimiento del sistema.
Una de las tareas básicas en la administración de bases de datos es la monitorización de nuestro servidor y nuestra base de datos. Para servidores Windows con SQL Server una de las maneras más básicas (y gratuitas) es hacerlo mediante los contadores de rendimiento del sistema.
Estos contadores de rendimiento del sistema se añaden en el Monitor de rendimiento de Windows (perfmon) y con ellos podemos visualizar valores de métricas relativas incluso a aplicaciones como Dynamics Ax que añaden sus propios contadores al instalarse en el servidor. De los contadores que elijamos, también podemos almacenar sus valores a lo largo del tiempo con la creación de conjuntos de recopiladores de datos e incluso podemos enviarnos alertas uniendo recopiladores e informes predefinidos.
Para monitorizar nuestro SQL Server, los principales contadores de rendimiento podrían ser (en el servidor actual y en el idioma que lo tengáis):
- Disco físico
Escrituras en disco/s
Lecturas de disco/s
Longitud actual de la cola de disco
Longitud promedio de cola de escritura de disco
Los dos primeros sirven para conocer la métrica y los valores medios por unidad o en total. El valor de la longitud promedio de cola de escritura de disco siempre debe tender a 0 en cada unidad y tampoco debería pasar de 2.
- Procesador
% de tiempo de procesador
¿Que decir? Es el uso de la cpu (de cada procesador o mejor el _Total para ver el promedio). Mejor evitar sobrepasar el 80%. Lo siguiente sería ver que es lo que está causando esa presión sobre el procesador.
- Memoria
Mbytes disponibles
Memoria sin asignar por el sistema. Debería ser mayor que 0 porque deberíamos contar con algo sobrante para otros procesos puntuales que puedan lanzarse en el servidor u otros servicios fijos como Analisys Services o Reporting Services.
- SQLServer: Acces Methods
Full Scans/sec
Index Searches/sec
Tipo de acceso. Un valor alto de Full scans a lo largo del tiempo indica la falta de indices. Si empezáramos a indizar en consecuencia deberíamos ver como compensamos con un incremento de Index Searches.
- SQLServer:Buffer Manager
Buffer cache hit ratio
Page life expectancy
El primer contador es el porcentaje de veces que el motor usa la caché frente al disco. Debe tender al 100%. Page Life expectancy es el tiempo en segundos que permanece una página en memoria sin tener ninguna referencia que la retenga allí. Cuanto más tiempo, mejor. Un valor bajo puede significar problemas de cache o incluso falta de memoria.
- SQLServer:General Statistics
Processes blocked
User connections
El primero indica los procesos bloqueados y el segundo el número de conexiones actual. Es bueno saberlos en todo momento para detectar anomalías e incluso alertarnos cuando los procesos bloqueados son mayores que 0.
- SQLServer:Memory Manager
Target Server Memory (KB)
Total server memory (KB)
Sirve para ver la asignación de memoria del sistema a Sqlserver por el sistema y el valor configurado dentro de Sqlserver. Un valor real menor al configurado indicaría falta de memoria.
- SQLServer:SQL Statistics
Batch Requests/sec
SQL Compilations/sec
SQL Re-Compilations/sec
Peticiones por segundo. Sirve también para detectar puntas de trabajo o procesos inusuales. El segundo y tercero permiten ver problemas de cache.
- SQLServer:Wait Statistics
Lock Waits
Log buffer waits
Log write waits
Memory grant queue waits
Network IO Waits
Page IO latch waits
Page latch waits
Eso son las esperas para las consultas. Con estos valores es fácil apuntar a una fuente de problemas para focalizar nuestra atención: problemas de red, de acceso a disco, de memoria. Existen otros tipos, pero sea cual sea debemos analizar en conjunto para cada contador las esperas en curso, las iniciadas por segundo y el tiempo medio de espera. Valores altos de forma continua deben llamar nuestra atención.
Además de todos los anteriores, podemos necesitar controlar otros más específicos a alguna característica o función de sql server. Por ejemplo, podemos monitorizar el tiempo de trasvase en un espejo asíncrono de cada transacción a la replica mirando el valor del contador SQLServer:Database Mirroring>Transaction Delay. Todos los contadores relativos al motor de SQL Server empiezan por SQLSERVER, los de Analisys Services empiezan por MSAS y los de Reporting Services con MSRS.
Para empezar a añadir nuestros propios contadores, abrimos el perfmon.exe, vamos al Monitor de rendimiento y seleccionamos la visualización tipo informe para trabajar más fácilmente.

A continuación, pulsamos el botón derecho del ratón sobre el área vacía del informe de color blanco y seleccionamos Agregar contadores. Ahí podemos buscar cualquiera de los anteriores para añadirlo o seleccionar el que queramos visualizar. La gracia también es que una vez seleccionados los que nos interesan podemos guardar la configuración (por ejemplo en el escritorio) para poder acceder en cualquier momento al Monitor de Rendimiento con nuestros contadores ya en la pantalla o poder elegir entre distintas configuraciones (una simple, una avanzada, etc etc).

Todos estos valores que hemos visto pueden irse recopilando a lo largo del día e incluso podemos definir valores "umbral" a partir de los cuales podemos realizar alguna acción e incluso enviarnos un correo electrónico para avisarnos del suceso. Esta es una forma de complementar o sustituir una motorización con herramientas tipo Nagios.
En resumen...
... es básico conocer como funciona el tema de los contadores de rendimiento, configurarlos y lo que podemos llegar a hacer con ellos. Además, casi igual de importante es conocer los valores de referencia estándares y con sus máximos y mínimos aceptados, como conocer los reales de funcionamiento de nuestro entorno. Creo que debemos saber y hasta donde tolerar, sin caer en la dejadez ni olvidarse, valores de ciertos contadores y separar lo que es normal y lo que no. Sabemos que siempre hay grandes o pequeñas aplicaciones que pueden hacer un mal uso o tener algún proceso mal planteado que a la práctica es imposible de modificar y tenemos que vivir con él.
También se debe saber que existen otras maneras de obtener esta información y tratarla. Desde el propio sql server podemos consultar la vista sys.dm_os_performance_counters que nos ofrece los valores actuales. Podemos filtrar por su columna object_name para elegir los mismos contadores por su nombre.
SELECT * FROM sys.dm_os_performance_counters WHERE OBJECT_NAME = 'SQLServer:Buffer Manager'

el problema que yo observo y
- Log in to post comments
Probando InMemory OLTP (Hekaton) en SQL Server 2014
Probando InMemory OLTP (Hekaton) en SQL Server 2014 il_masacratore 11 November, 2013 - 10:32En la versión 2014 de Sql Server introducirán un nuevo motor en la base de datos que permitirá trabajar con tablas en memoria (inmemory o hekaton, su nombre en clave). Podemos imaginar que eso puede suponer una mejora considerable en el rendimiento si sabemos elegir para este nuevo las tablas adecuadas. Su funcionamiento es lógico y es el que cabe esperar. Según la MSDN, las tablas y sus registros se mantienen principalmente en memoria y una segunda copia se mantiene en disco para disponer de los datos si reiniciásemos la instancia. Tenemos también la posibilidad de elegir el tiempo que tarda en trasladarse un cambio en los datos de la tabla en memoria a la tabla en disco. También existe la posibilidad de crear tablas on-the-fly (non-durable table) y que no se persistan en disco. En cualquier caso hemos de tener en cuenta que en caso de desastre o reinicio de servidor, cualquier dato no trasladado a disco seguro que lo perdemos. Vamos a hacer unas pruebas.
Primero de todo, para poder usar tablas en memoria tenemos crear un grupo de ficheros del tipo adecuado. En este caso, anticipándome al futuro, combinamos uno de cada tipo (el normal por que sí y luego añadimos uno para datos en memoria después):
CREATE DATABASE [InMemoryTest] CONTAINMENT = NONE ON PRIMARY ( NAME = N'InMemoryTest', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\InMemoryTest.mdf' , SIZE = 5120KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'InMemoryTest_log', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\InMemoryTest_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%) GO ALTER DATABASE InMemoryTest ADD FILEGROUP InMemoryTest_im CONTAINS MEMORY_OPTIMIZED_DATA ALTER DATABASE InMemoryTest ADD FILE (name='InMemoryTest_im1', filename='C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\InMemoryTest_im1') TO FILEGROUP InMemoryTest_im GO
--*** Si os aparece un error de que el procesador no es compatible usando VBox mirar al pie de página
A continuación vamos con nuestras tablas de ejemplo por cada tipo (la de toda la vida, DURABILITY = SCHEMA_ONLY y DURABILITY = SCHEMA_AND_DATA ):
-- Creación de la tabla normal (en el fg por defecto) use InMemoryTest CREATE TABLE Ventas ( IdVenta int identity PRIMARY KEY NOT NULL ,IdCliente int NOT NULL ,Total int NOT NULL ,FechaVenta date NOT NULL ,TipoVenta char(1) NOT NULL ,INDEX Ventas_FechaVenta NONCLUSTERED (FechaVenta) ) -- Creación de la tabla en memoria, solo con estructura en disco use InMemoryTest CREATE TABLE InMemoryVentas ( IdVenta int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000) ,IdCliente int NOT NULL ,Total int NOT NULL ,FechaVenta date NOT NULL ,TipoVenta char(1) NOT NULL ,INDEX InMemoryVentas_FechaVenta NONCLUSTERED HASH (FechaVenta) WITH (BUCKET_COUNT = 365) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_ONLY) -- Creación de la tabla en memoria con datos y estructura en disco (DURABLE) use InMemoryTest CREATE TABLE InMemoryDurableVentas ( IdVenta int NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000) ,IdCliente int NOT NULL ,Total int NOT NULL ,FechaVenta date NOT NULL ,TipoVenta char(1) NOT NULL ,INDEX InMemoryVentas_FechaVenta NONCLUSTERED HASH (FechaVenta) WITH (BUCKET_COUNT = 365) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA)
Seguiremos con la carga de datos. Añado el mensage de output para ver cuanto tarda en cada tabla. Cuidado porque en este caso, la segunda tabla no se persiste en disco (DURABILITY = SCHEMA_ONLY) Si reiniciamos la instancia perderemos los datos. La tercera sí la persistimos en disco pero trabajamos con la copia en memoria.
-- Carga de datos para las tres tablas SET NOCOUNT ON; USE InMemoryTest DECLARE @vCont int = 0; PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertando 1000000 en Ventas') WHILE @vCont < 1000000 BEGIN SET @vCont += 1; INSERT INTO Ventas VALUES (@vCont%11, 9999, DATEADD(DD,-@vCont%365,GETDATE()), @vCont%2) END PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertados 1000000 en Ventas') SET @vCont = 0; PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertando 1000000 en InMemoryDurableVentas') WHILE @vCont < 1000000 BEGIN SET @vCont += 1; INSERT INTO InMemoryDurableVentas VALUES (@vCont, @vCont%11, 9999, DATEADD(DD,-@vCont%365,GETDATE()), @vCont%2) END PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertados 1000000 en InMemoryDurableVentas') SET @vCont = 0; PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertando 1000000 en InMemoryVentas') WHILE @vCont < 1000000 BEGIN SET @vCont += 1; INSERT INTO InMemoryVentas VALUES (@vCont, @vCont%11, 9999, DATEADD(DD,-@vCont%365,GETDATE()), @vCont%2) END PRINT( CONVERT(varchar, GETDATE(), 114) + N' > Insertados 1000000 en InMemoryVentas')
En mi caso, la ejecución con de este último script de tabla me muestra que tarda cerca de 14 minutos en cargar la tabla en disco, cerca de 12 minutos la tabla en memoria persistida en disco al completo y apenas 1 solo minuto para la tabla de la que solo tenemos la estructura en disco (pero de la que al reiniciar la instancia perderemos sus datos). Esta prueba ya empieza a mostrar diferencias y sobretodo ventajas para trabajar con tablas en memoria...

Ahora vamos a probar y medir algunas consultas que haremos contra cada tipo de tabla. Para ello las ejecutamos previa limpieza de cache y buffers:
USE InMemoryTest; GO DBCC FREEPROCCACHE WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; SET NOCOUNT ON; SET STATISTICS IO ON; SET STATISTICS TIME ON; PRINT(N'Sobre Ventas...') SELECT DISTINCT IdCliente FROM Ventas WHERE FechaVenta = '01/01/2013'; PRINT(N'Sobre InMemoryDurableVentas...') SELECT DISTINCT IdCliente FROM InMemoryDurableVentas WHERE FechaVenta = '01/01/2013'; PRINT(N'Sobre InMemoryVentas...') SELECT DISTINCT IdCliente FROM InMemoryVentas WHERE FechaVenta = '01/01/2013';
Mi salida (que adjunto abajo) es la siguiente. No parece muy descriptiva pero ya vemos que el tiempo transcurrido es prometedor ya que pasamos de casi 400ms, a 1 y 0 milisegundos. Prometedor. Podéis probar de desordenar lo selects para modificar el orden si no os lo creéis y veréis que el resultado es muy similar. En mi opinión esto promete.
Sobre Ventas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Ventas'. Recuento de exámenes 3, lecturas lógicas 6302, lecturas físicas 1,
lecturas anticipadas 6225, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 250 ms, tiempo transcurrido = 397 ms.
Sobre InMemoryDurableVentas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 2 ms.
Sobre InMemoryVentas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 1 ms.
Aunque, en el ejemplo hay trampa, porque si miramos los planes de ejecución veremos que en el caso de la tabla de toda la vida tenemos un index scan mientras que en el caso de las tablas en memoria tenemos index seek (scan vs seek, gana seek) sobre el HASH INDEX. Eso es porque de forma inherente los indices de tablas en memoria ya son punteros directos a los datos de fila parecidos a los covering indexes. Es más, nos propone crearlo.
CREATE NONCLUSTERED INDEX Ventas_FechaVentaIncIdCliente ON [dbo].[Ventas] ([FechaVenta]) INCLUDE ([IdCliente])
Lo crearemos, volveremos a ejecutar la consulta y el resultado debe ser como el siguiente.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Ventas'. Recuento de exámenes 1, lecturas lógicas 15, lecturas físicas 0,
lecturas anticipadas 12, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 10 ms.
Como vemos sigue ganando la tabla en memoria... de momento. Ahora cambiamos el tipo de consulta a una sin igualdad, cambiaremos a una de rango.
USE InMemoryTest; GO DBCC FREEPROCCACHE WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; SET NOCOUNT ON; SET STATISTICS IO ON; SET STATISTICS TIME ON; PRINT(N'Sobre Ventas...') SELECT DISTINCT IdCliente FROM Ventas WHERE FechaVenta >= '01/01/2013' AND FechaVenta < '01/02/2013'; PRINT(N'Sobre InMemoryDurableVentas...') SELECT DISTINCT IdCliente FROM InMemoryDurableVentas WHERE FechaVenta >= '01/01/2013' AND FechaVenta < '01/02/2013'; PRINT(N'Sobre InMemoryVentas...') SELECT DISTINCT IdCliente FROM InMemoryVentas WHERE FechaVenta >= '01/01/2013' AND FechaVenta < '01/02/2013';
El resultado es este:
Sobre Ventas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Ventas'. Recuento de exámenes 1, lecturas lógicas 362, lecturas físicas 0,
lecturas anticipadas 125, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 78 ms, tiempo transcurrido = 71 ms.
Sobre InMemoryDurableVentas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 266 ms, tiempo transcurrido = 255 ms.
Sobre InMemoryVentas...
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 0 ms, tiempo transcurrido = 0 ms.
Tabla 'Worktable'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tabla 'Workfile'. Recuento de exámenes 0, lecturas lógicas 0, lecturas físicas 0,
lecturas anticipadas 0, lecturas lógicas de LOB 0, lecturas físicas de LOB 0, lecturas anticipadas de LOB 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU = 250 ms, tiempo transcurrido = 252 ms.
El resultado ya no mola tanto pero esto se soluciona añadiendole un nuevo indice de rango, más adecuado si esperamos hacerle consultas del tipo. Por desgracia la única manera de hacerlo es recrear la tabla.
Mis conclusiones...
...son que este tipo de tablas pueden ser muy útiles pero hay que saber cuando usarlas. Me vale que podamos mantener los dos tipos de grupos de fichero (normales y preparados para persistir en memoria). También creo que en rendimiento puro no hay mucha diferencia en las tablas que están en memoria, entre la que persiste en disco y de la que solo mantenemos la estructura. En todo caso, puede ser interesante investigar el tema de DELAYED_DURABILITY para posponer la propagación de los cambios a disco.

*** The model of the processor on the system does not support creating filegroups with MEMORY_OPTIMIZED_DATA. This error typically occurs with older processors.
Este error aparece al crear el tipo de filegroup con la clausula MEMORY_OPTIMIZED_DATA si estamos usando por lo menos la versión 4.1 de Oracle VirtualBox. Actualizando la versión podríamos tener suficiente para solventar el problema. Si no ejecutamos lo siguiente en el directorio de VirtualBox:
VBoxManage setextradata [nombre_maquina_virtual] VBoxInternal/CPUM/CMPXCHG16B 1
SQL Server 2014 DQS (Data Quality Services)
SQL Server 2014 DQS (Data Quality Services) il_masacratore 21 November, 2013 - 12:53Microsoft Sql Server Data Quality Services (DQS) es una herramienta, cliente-servidor, que se introdujo en Sql Server 2012 y que permite permite velar por la integridad de los datos basada en unos datos previos, la base de datos de conocimiento, que usamos para validar otros datos posteriores. Esta herramienta permite incluso limpiar datos entrantes en paquetes de SSIS. Su propósito es conseguir datos de calidad, construyendo primero una fuente de conocimiento sobre la calidad objetivo de nuestros datos, creando dominios (valores de referencia para asignar validez o no) y reglas para definir actuaciones.

Generalmente los datos incorrectos son un problema que se genera por usuarios o clientes en el momento de su introducción. Otras veces, los problemas pueden venir al unir diferentes orígenes de datos en un mismo almacén de datos destino. Con herramientas como DQS podemos, de alguna manera, validar nuestros datos o incluso corregirlos para obtener finalmente datos válidos y de mayor valor empresarial. En teoría, una de las ventajas que dice Microsoft sobre DQS es que permite a usuarios de distintos niveles (usuario final o profesional IT) el crear, ejecutar y mantener las operaciones de calidad de datos...
Antes empezar necesitaremos tener instalado en nuestro servidor lo necesario para empezar a probar. Lanzamos el instalador de SqlServer y añadimos a nuestra instancia de SqlServer Data Quality Services, bajo el motor de la base de datos y en el caso de probar con una máquina virtual también el cliente de calidad de datos.

Una vez completada la instalación activamos la parte del Servidor. Lo encontramos en el menú Inicio > Programas > Microsoft SQL Server 2014 CTP>Data Quality Server Installer

Además de los componentes de servidor, eso también copia una base de conocimento de ejemplo, DQS Data, que incluye algunos dominios predefinidos. Superado este paso ya podemos empezar con nuestro ejemplo. Para las pruebas tendremos dos tablas de empleados como esta que usaremos primero como base para crear las reglas para nuestra base de datos de conocimiento y una vez definidos dominios con sus reglas de validación, las usaremos para probar de corregir los datos y exportarlos a otra tabla de sqlserver.
--Script de carga para las tablas de ejemplo. CREATE TABLE [dbo].[EmpleadosA]( [Nombre] [varchar](20) NULL, [Genero] [varchar](10) NULL, [Edad] [tinyint] NULL ) ON [PRIMARY] INSERT INTO [dbo].[EmpleadosA] VALUES ('John','Male',18) INSERT INTO [dbo].[EmpleadosA] VALUES ('Mike', 'Hombre',18) INSERT INTO [dbo].[EmpleadosA] VALUES ('Rahul', 'Ind',NULL) INSERT INTO [dbo].[EmpleadosA] VALUES ('Sara','Mujer',23) INSERT INTO [dbo].[EmpleadosA] VALUES ('Alberto','H',48) INSERT INTO [dbo].[EmpleadosA] VALUES ('Carlos','Hombre',18) GO CREATE TABLE [dbo].[EmpleadosB]( [Nombre] [varchar](20) NULL, [Email] [varchar](40) NULL, [Titulo] [varchar](20) NULL ) ON [PRIMARY] INSERT INTO [dbo].[EmpleadosB] VALUES ('John','jhon@test.com',NULL) INSERT INTO [dbo].[EmpleadosB] VALUES ('Mike','Mike test.com','Bachillerato') INSERT INTO [dbo].[EmpleadosB] VALUES ('Rahul',' ','Primaria) INSERT INTO [dbo].[EmpleadosB] VALUES ('Sara','sara@test.com','PM') INSERT INTO [dbo].[EmpleadosB] VALUES ('Alberto','alberto@test','Secundaria') INSERT INTO [dbo].[EmpleadosB] VALUES ('Carlos','test@test.com','Licenciado') GO
A continuación ya podemos abrir el Cliente de Calidad de Datos (Microsoft SQL Server 2014>Data Quality Client) para empezar a trastear. Nada más clicar nos pide el nombre del servidor (pensemos en nuestra instancia de servidor SQLSERVER). Lo primero que debemos hacer es crear una Nueva base de Conocimiento.

Lo siguiente será crear una nueva. Le ponemos Nombre y pulsamos siguiente. Cerramos y volvemos al menú principal. A continuación Lo que haremos será elegir de nuestra base de datos la "Detección de conocimiento". Esta opción permite elegir una fuente de datos (excel, sqlserver) y definir dominios a partir de columnas de datos. En mi caso me conecto a la bbdd, elijo una de los tablas de ejemplo para empezar a definir para cada columna que me interese un dominio con parámetros específicos en cada columna que lo necesite... Particularmete interesante la opción de poder elegir, en el caso de una columna de texto, el idioma del mismo, pasarle el corrector ortográfico y también formatear la salida (MAY/MIN para abreviaturas?).

El paso siguiente es el "análisis de detección de datos en el origen seleccionado". Se escanea el origen y se determina por cada columna los valores únicos, los validos y los que infringen la integridad (valores null etc). Si hemos probado sobre EmpleadosA solo vemos un error de integridad debido a un NULL en la columna Edad. Pulsamos siguiente y podemos elegir que hacer con los nuevos valores que sean validos, así como ignorar los incorrectos marcándolos como error.
(
Ahora, antes de validar de nuevo, definiremos un dominio más complejo para los campos de email. En este caso será una regla de validación de formato. Primero vamos como a antes a la detección de dominios para definir sobre la segunda tabla el dominio sobre la columna email (como el los ejemplos anteriores). Una vez hemos creado el dominio para el campo email, la diferencia es que saldremos y entraremos en el Administrador de dominios sobre nuestra base de datos de conocimiento y modificaremos las Reglas de Dominio (fijaros también que aquí podemos explorar los Valores del Dominio que forman parte de él) para añadir una del tipo: "El valor coincide con la expresión regular": ^[_a-z0-9-]+(\.[a-z0-9-]+)*@[a-z0-9-]+(\.[a-z0-9-]+)*(\.[a-z]{2,4})$

Al final publicamos este último cambio de este dominio y ya estamos listos para continuar.
El último paso ya para acabar con esta prueba es validar una tabla real, corregir los datos y exportar a una nueva con los datos que no cumplan las reglas y decidamos corregir. Para hacerlo abrimos de nuevo el Data Quality Client y creamos un nuevo proyecto de calidad de datos. Le pondremos nombre, elegimos la base de conocimiento que hemos definido antes y elegimos limpieza. Los pasos a partir de aquí son parecidos a los anteriores cuando explorábamos la tabla. En el siguiente paso elegimos la tabla a limpiar y para cada columna, si es necesario, un dominio para aplicar sobre ella. Pulsamos siguiente y escaneamos los datos. Con los datos de ejemplo, detectara dos valores para email erróneos que podremos corregir (si han sido corregidos anteriormente los auto-corrige y aparecen como "Corregido"). Finalmente, en el siguiente paso podemos elegir donde exportar nuestros datos pulidos (por ejemplo a una nueva tabla).

Mis conclusiones son...
... que esta es otra herramienta Microsoft bastante fácil de usar y puede que bastante útil para pulir datos maestros de cualquier base de datos o para incluir validaciones como paso intermedio en nuestras cargas para el dwh. Su sencillez (la misma prueba con el proyecto de calidad de datos) hace fácil compartir la carga de corrección manual de los datos con alguien que no sea técnico de bbdd ni programador, más bien una persona dentro de la organización con conocimiento de causa que coja los datos del origen, los interprete y los deje donde tu le digas para cargarlos en algún sitio.
Articulo muy interesante,
- Log in to post comments
SQL Sentry Plan Explorer de SQL Server 2014, herramienta complementaria a Management Studio
SQL Sentry Plan Explorer de SQL Server 2014, herramienta complementaria a Management Studio il_masacratore 16 January, 2014 - 13:22SentryOne dispone de diferentes aplicaciones para ayudarnos en la administración y el día a día con nuestra base de datos SQL Server, dwh o como desarrolladores. SentryOne Plan Explorer permite hacer un análisis más gráfico de una consulta que lanzamos sobre SQL Server y deforma interactiva profundizar en diferentes aspectos relacionados como coste de operaciones, peso sobre el lote, índices involucrados...
Plan Explorer tiene versión free y versión PRO. La versión free podemos descargarla directamente de SentryOne donde tenemos el instalador de la aplicación y adicionalmente un addon para SQL Server Management Studio. La instalación no tiene misterio y es del estilo siguiente siguiente.
A primera vista, como otras herramientas parecidas, muestra lo que nos da el propio Management Studio cuando vemos el plan de ejecución estimado/real de una consulta. Lo que es distinto es que de forma predeterminada ya focaliza nuestra atención a las áreas problemáticas que van con nuestra consulta. Por ejemplo, en la pestaña de Plan Diagram, ya nos marca las operaciones más costosas mediante colores. Otro ejemplo es la pestaña Plan Tree que muestra los datos más concretos donde también nos marca de otro color si existe una gran diferencia entre las filas estimadas con las filas reales (estadísticas desactualizadas!).
La forma de empezar a trabajar es bastante sencilla. Basta con hacer un Copy & Paste de la consulta en la pestaña que vemos por defecto en la pantalla inicial, Command Text. A continuación ya podemos pulsar ver el Plan Estimado o el Real, como en Management Studio. Es en ese momento cuando nos pide a que servidor y base de datos conectarse.


Una vez conectados y obtenido el plan estimado de ejecución ya vemos en la parte inferior su diagrama. En el ya nos marca en % relativos al coste total las operaciones y en colores remarcadas las más costosas. A diferencia de Management Studio, si falta un indice nos aparece el símbolo warning en el SELECT en lugar de la parrafada en el encabezado de la pestaña.

Los porcentajes que vemos, por defecto corresponde a la suma de I/O+CPU, pero también podemos elegir solo por I/O o CPU según nos convenga. También podemos hacer que varíe el grueso de las lineas de datos según su volumen (todo esto en el menú contextual del área del gráfico).

En la segunda pestaña del panel inferior, Plan Tree, vemos jerarquizadas las operaciones con los datos más relevantes por defecto (Coste estimado, Coste del subarbol, filas estimadas que pasan, etc...). Podemos añadirle según nuestras necesidades o gustos mas columnas.

En la tercera pestaña, Top Operations, podemos comparar directamente mediante una tabla costes de cpu y de I/O las diferentes operaciones dentro de la consulta. Como en la pestaña anterior, podemos añadir más columnas según nuestros gustos.

En la cuarta, Query Columns, vemos los índices que se usan en la consulta y que filtros aplican. También vemos el tipo de operación (Index Seek, Clustered Index Seek, Index Scan...). En la versión PRO de Plan Explorer desde aquí podemos ver las estadísticas de estos índices e incluso crear uno nuevo.

La quinta pestaña, Join Diagram, muestra de manera directa y muy simplificada las tablas involucradas solo con los campos que usamos en la relación entre ellas.

Parameters muestra los parámetros incluidos en la consulta, incluso los no declarados explícitamente. La pestaña Expressions muestra datos adicionales por cada expresión de agregado: SUM, MIN etc... Realmente no aporta demasiado pero tampoco molesta. Por último, la pestaña Table I/O muestra los datos relativos a entrada y salida de datos: cantidad de scans, lecturas físicas, lógicas.
Una de las diferencias entre trabajar con el plan estimado (Get Estimated PLan) y el real (Get Actual Plan) es que además de las estadísticas de I/O que se muestran en la pestaña Table I/O, también se comparan las filas estimadas con las reales, algo que puede indicar que las estadísticas están desactualizadas.
Otra de las opciones, como mínimo curiosas, es la opción de menú Anonymize. Esta lo que hace es abrir una nueva ventana donde nos ha reemplazado los nombres de nuestras bases de datos, los índices, nombres de usuario, alias, parámetros... con toda la info relativa a la query. La gracia es poder compartir esta información y pedir consejo si hiciera falta.
El addon de SentryOne Plan Explorar para SQL Server Management Studio es un simple vínculo que permite desde la visualización de cualquier plan de ejecución desde el menú contextual, haciendo clic derecho en el área "View with SQL Sentry Plan Explorer". Para instalarlo basta con descargarlo de aquí y reiniciar Management Studio para que podamos usarlo. Es un requisito haber instalado antes la propia aplicación Plan Explorer. El addon de momento funciona con Management Studio incluido en SQL Server 2005, SQL Server 2008, SQL Server 2008 R2 y SQL Server 2012.
En resumen...
... Me parece una herramienta útil pero no esencial. Ofrece alguna cosa más que el propio Management Studio y lo hace más bonito pero podemos vivir sin ella. Uno de los motivos por los quizás que me parece recomendable es para alguien que anda perdido y no sabe por donde empezar.
No es lo mismo enfrentarte con la ventana del plan de SSMS que con los colores y pestañas de SQLSentry Plan Explorer. Para el resto, mi conclusión es que lo que más aporta es facilidad de acceso a todos los aspectos relacionados con la query.
Consultas útiles de SQL Server para administración y desarrollo
Consultas útiles de SQL Server para administración y desarrollo Carlos 18 March, 2020 - 20:11Las herramientas como SQL Server Management Studio facilitan mucho la administración y el desarrollo con SQL Server con multitud de funciones, asistentes y exploradores que permiten realizar fácilmente muchas de las tareas del día a día de administradores y desarrolladores de SQLServer.
Aún así, siempre hay información y acciones que se pueden realizar de manera más rápida, o más personalizada, o que simplemente con la parte visual no se pueden obtener. Son comandos y/o con consultas SQL ejecutadas desde una hoja de consultas, por ejemplo.
Iré recogiendo en este post muchas de esas consultas que a mi en muchas ocasiones me han resultado útiles, o que vea que pueden ayudarme a mi o a los demás en el futuro.
La mayor parte de estas queries se realizan utilizando las DMV, o Dynamic Management Views, y las DMF, o Dynamic Management Functions de SQL Server, que proporcionan información sobre la base de datos, sesiones, conexiones, estado, almacenamiento, índices..
También incluyo llamadas a stored procedures de sistema sys.sp_[StoredProcedure] que proporcionan igualmente información o utilidades para actuar sobre la base de datos.
Para comenzar, nada mejor que una consulta para ver cuáles son las DMV's o DMF's que nos proporciona SQL Server:
-- Listar objetos DMO (DMV/DMF) de la base de datos SELECT name, type, type_desc FROM sys.system_objects WHERE name LIKE 'dm_%' ORDER BY type desc, name
Consultas para obtener información sobre conexiones y sesiones
-- Información sobre las conexiones actuales select * from sys.dm_exec_connections
-- Información sobre las sesiones actuales SELECT * FROM sys.dm_exec_sessions
-- Información combinada conexiones y sesiones select * FROM sys.dm_exec_sessions s INNER JOIN sys.dm_exec_connections c ON s.session_id = c.session_id -- WHERE s.is_user_process = 1
Aunque también hay otras maneras de obtener información sobre sesiones y procesos, y también bloqueos:
-- Información sobre sesiones/procesos actuales exec sp_who2
-- Deadlocks actuales en la base de datos
SELECT xdr.value('@timestamp', 'datetime') AS [Date], xdr.query('.') AS [Event_Data]
FROM (SELECT CAST([target_data] AS XML) AS Target_Data
FROM sys.dm_xe_session_targets AS xt
INNER JOIN sys.dm_xe_sessions AS xs ON xs.address = xt.event_session_address
WHERE xs.name = N'system_health' AND xt.target_name = N'ring_buffer'
) AS XML_Data
CROSS APPLY Target_Data.nodes('RingBufferTarget/event[@name="xml_deadlock_report"]') AS XEventData(xdr)
ORDER BY [Date] DESC
-- Espacio ocupado por la base de datos de la conexión EXEC sp_spaceused @updateusage = 'FALSE', @mode = 'ALL', @oneresultset = '1';
-- Espacio físico ocupado por una tabla EXEC sp_spaceused @objname = 'TABLE', @updateusage = 'FALSE', @mode = 'ALL', @oneresultset = '0'
Consultas SQL útiles para tratar y transformar cadenas y datos
-- Query que hace un split de los campos de un string en formato CSV o similar separados por ';'
DECLARE @cadenaCSV varchar(50)= 'Valor.Campo1; Valor.Campo2; Valor.Campo3'
SELECT REPLACE(REVERSE(PARSENAME(REPLACE(REVERSE(REPLACE(@cadenaCSV,'.','||')), ';', '.'), 1)),'||','.') AS Campo1
, REPLACE(REVERSE(PARSENAME(REPLACE(REVERSE(REPLACE(@cadenaCSV,'.','||')), ';', '.'), 2)),'||','.') AS Campo2
, REPLACE(REVERSE(PARSENAME(REPLACE(REVERSE(REPLACE(@cadenaCSV,'.','||')), ';', '.'), 3)),'||','.') AS Campo3
Seguiré ampliando esta recopilación de consultas útiles para tenerlas siempre 'a mano' cuando se necesiten.
Si quieres contribuir con alguna query de SQL Server que te sea de utilidad y pienses que también puede serlo a los demás puedes añadirla con un comentario de este mismo post.
Saludos!
Primeros pasos como administrador de SQL Server sobre un entorno heredado
Primeros pasos como administrador de SQL Server sobre un entorno heredado il_masacratore 18 March, 2014 - 13:14![]() Por el motivo que sea, un día puede que cambiamos de trabajo o de funciones dentro de nuestra empresa y de repente heredemos un entorno de base de datos Microsoft SQL Server con un servidor o clúster de bases de datos para que nos encarguemos de él. Antes de empezar a cambiar cosas, es totalmente necesario conocer el uso que se hace de la base de datos, la criticidad de las aplicaciones que la usan, las dependencias entre ellas etc... A continuación una lista de las primeras cuatro tareas que podríamos llevar a cabo para empezar a hacerlo nuestro.
Por el motivo que sea, un día puede que cambiamos de trabajo o de funciones dentro de nuestra empresa y de repente heredemos un entorno de base de datos Microsoft SQL Server con un servidor o clúster de bases de datos para que nos encarguemos de él. Antes de empezar a cambiar cosas, es totalmente necesario conocer el uso que se hace de la base de datos, la criticidad de las aplicaciones que la usan, las dependencias entre ellas etc... A continuación una lista de las primeras cuatro tareas que podríamos llevar a cabo para empezar a hacerlo nuestro.
Antes de empezar a hacer nada, lo obligatorio será conocer el tipo de entorno al que nos intentamos conectar. ¿Es el entorno de producción o el de desarrollo? Si es desarrollo podemos mirar sin temor, si sabemos que es producción cuidado no rompamos nada.
- El primer paso será disponer de un usuario con permisos de administración para cada instancia de la base de datos. Si no tenemos ninguno y no hay nadie que tenga acceso a nivel de base de datos, podemos recuperar la contraseña del usuario "sa" de SQL Server como comento en este otro post. Una vez tengamos el usuario Administrador ya podemos empezar a trastear con lo habitual y que es primordial en los primero días. Nos conectamos a la base de datos con Microsoft SQL Server Management Studio.
- El segundo paso puede ser listar las bases de datos: No tiene mucha más complicación que conectarnos a la base de datos con Management Studio y observar el listado de objetos dentro de Bases de datos. Si entramos en detalle nos puede interesar su tamaño, que podemos ver uno a uno en sus propiedades. otra manera es sacar un listado con la siguiente consulta que nos devuelve la ruta de los ficheros, el tamaño actual en Mb, el tipo y el nombre de la base de datos.
SELECT database_id, type_desc, name, physical_name, size*8/1024 AS mb_size FROM sys.master_files
- En el tercero lo que haría sería comprobar la política de copias de seguridad para cada una de las bases de datos. Primero debemos conocer el tipo de recovery model usado y el seguimiento (simple, full, bulk-logged). Como en el punto anterior, podemos ir mirando las propiedades de la base de datos una a una o sacarnos un listado a modo resumen con una consulta:
SELECT name, recovery_model_desc, state_desc FROM sys.databases
A continuación también debemos averiguar si se están haciendo copias y como. De forma rápida se me ocurren distintos lugares donde podemos comprobar si hay alguna:
1. Planes de mantenimiento: Los podemos consultar en el Explorador de Objetos, en Administración > Planes de mantenimiento
2. Tarea del agente: Es posible que haya algún script que se ejecuta periódicamente como Tarea del Agente de SQL Server. Cuidado porque los planes de mantenimiento (punto anterior) se traducen finalmente en tareas del agente.
3. Tareas del sistema operativo: Parecido al punto anterior, un script que se ejecuta desde una Tarea Programada en el Programador de Tareas. Es otra manera y es posible que esté así...
Con la información obtenida en los puntos anteriores ya tenemos un punto de partida con el que empezamos a conocer que tenemos entre manos: tenemos una lista con las bases de datos, sabemos si se hacen copias y ahora nos toca ver que aplicaciones utilizan cada una de las bases de datos.
- El cuarto paso sería obtener usuarios activos y saber que bases de datos se usan de forma automática durante un periodo de tiempo. Una manera de hacerlo sería crear un trigger de auditoria en la apertura de conexiones al servidor. Existe un trigger de server que se dispara una vez conectado (ver logon trigger) que se podría usar para hacer algo parecido a esto que hice con MySQL, Otra manera de hacerlo menos critica y más sencilla si no estamos seguro sería consultando de forma continua las sesiones activas y cargar los resultados en una tabla:
Primero creamos la tabla donde cargaremos los datos:
CREATE TABLE msdb.dbo.log_de_acceso ( id int IDENTITY(1,1) NOT NULL, dbname nvarchar(128) NULL, dbuser nvarchar(128) NULL, hostname nchar(128) NOT NULL, program_name nchar(128) NOT NULL, nt_domain nchar(128) NOT NULL, nt_username nchar(128) NOT NULL, net_address nchar(12) NOT NULL, logdate datetime NOT NULL CONSTRAINT DF_user_access_log_logdate DEFAULT (getdate()), CONSTRAINT PK_user_access_log PRIMARY KEY CLUSTERED (id ASC) ) )
Luego abrimos otra ventana de consulta donde ejecutamos el siguiente trozo de código. Podemos elegir cada cuanto ejecutamos la consulta modificando el DELAY. La auditoria funcionará mientras tengamos el código ejecutándose.
WHILE 1=1
BEGIN
WAITFOR DELAY '00:00:30';
INSERT INTO msdb.dbo.log_de_acceso (dbname,dbuser,hostname,program_name,nt_domain,nt_username,net_address )
SELECT distinct DB_NAME(dbid) as dbname,
SUSER_SNAME(sid) as dbuser,
hostname,
program_name,
nt_domain,
nt_username,
net_address
FROM master.dbo.sysprocesses a
WHERE spid>50
AND NOT EXISTS( SELECT 1
FROM msdb.dbo.log_de_acceso b
WHERE b.dbname = db_name(a.dbid)
AND NULLIF(b.dbuser,SUSER_SNAME(a.sid)) IS NULL
AND b.hostname = a.hostname
AND b.program_name = a.program_name
AND b.nt_domain = a.nt_domain
AND b.nt_username = a.nt_username
AND b.net_address = a.net_address )
END
Con la información obtenida hasta ahora ya tenemos una base suficiente para seguir hablar con los responsables de las aplicaciones que usan nuestra base de datos y conocer cual es su función. También es necesario saber de primera mano la criticidad de las mismas y dependencias entre los datos que usa. Más de una vez las aplicaciones usaran más de una tabla contenida en distintas bases de datos.
- Una vez tengamos esto podemos considerar que ya tenemos una visión global y debemos centrarnos más en aspectos técnicos. Yo seguiría por indagar más en nuestros servidores. Como paso final me centraría en obtener la información puramente técnica del entorno y documentar lo siguiente:
-La versión de SQL Server, su estado de actualización y estado de licencias.
-La edición (Enterprise, Standard,e tc...).
-Parcheado. Interesa saber si se ha aplicado algún parche, además del service pack.
-Las características de la instalación en uso. Según la versión de base de datos, puede que necesitemos saber si usamos solo el motor de base de datos o tenemos instancias de SQL Server Reporting Services (motor de informes) o SQL Server Analysis Services (cubos de información).
-Privilegios. Entrar en detalle y saber que otros usuarios activos tienen permisos de administración etc...
En conclusión...
... , la lista de cosas por hacer es larga y no todo está incluido en este post, pero por algo se empieza. Aunque no en en este orden, lo incluido lo veo esencial para poder entender que tenemos entre manos y cubrirnos bien las espaldas desde el primer dia en el que el "marron" es nuestro.
ApexSQL Refactor: Complemento para edición de código en MS SQL Server Management Studio
ApexSQL Refactor: Complemento para edición de código en MS SQL Server Management Studio il_masacratore 10 December, 2013 - 10:30ApexSQL Refactor es una herramienta potente de formateo de código sql para usuarios que trabajan a diario con él. Es un complemento para SQL Server Management Studio que puede ayudarte a generar, reutilizar el código o formatearlo (tabulaciones, mayúsculas, minúsculas, nomenclatura, palabras reservadas...) para hacerlo más legible para otros o incluso parsear el de otros para presentarlo a tu gusto.
Este refactor, es un complemento gratuito, aunque existe una versión más completa de pago y se puede descargar directamente de la página del fabricante. La pega, como suele ser habitual en estos casos es que requiere registrarse para poder bajarte el instalador.
Instalación de ApexSQL Refactor
Descargamos el complemento, una vez registrados y lanzamos el setup. Como se ve en la imagen, permite usarlo con diferentes versiones "actuales" de Visual Studio y MS.

Una vez finalizado el instalador confirmaremos que todo ha ido bien cuando abramos Management Studio y nos aparezca el nuevo menú:

Formateando el código
Lo ideal para empezar a usarlo es ponernos a editar las opciones para el formateador del código. Para ello nos vamos a ApexSQL > Apex SQLRefactor > Format SQL Code > Formatting Options. En este formulario podemos editar diferentes perfiles de formateo. Nosotros deberíamos crear uno nuevo e ir jugando con las diferentes opciones. Encontrareis una guía-resumen muy clara en este enlace.

Como guinda, para facilitar el uso y formateo de código que hemos editado, primero deberíamos establecerlo como predeterminado desde el formulario de Formatting Options, marcando la casilla Use as default. Por último, fijarnos en el atajo de teclado (Ctrl+May+Alt+F) o cambiarlo desde el menú ApexSQL>ApexSQL Refactor>Options.
Refactorizando
Además de la parte anterior, con este complemento tenemos la opción de automatizar la generación de partes de código. Si nos paramos a mirar, desde el mismo menú ya podemos ver algunas de las opciones que lanzan asistentes para "hacer la magia":
-
Copiar al portapapeles como otro lenguaje: Por ejemplo, en el caso de una select la copia entre comillas y nos la asigna a una variable de tipo cadena del lenguaje seleccionado con su declaración. El ejemplo select * from sys.databases lo transforma a c# así: string sql = "select * from sys.databases;";
-
Encapsular como: Envolver la consulta para regalo en forma de vista, procedimiento, función o función escalar. Si lo elegimos se lanza un asistente donde nos permite elegir nombre, parámetros y nos muestra el script que generará.
.jpg)
En resumen...
… és útil y además gratis, aunque seguro que existen otras herramientas que hacen lo mismo. Por cierto, una manera más rápida de formatear una SELECT dentro de Management Studio es seleccionarla entera (sola) y pulsar Ctrl+Shift+Q para que se abra el Diseñador de consultas. Pulsamos aceptar y ya está toda espaciada y tabulada de forma simple.
Bids Helper: Complemento para MS Business Intelligence Developement Studio
Bids Helper: Complemento para MS Business Intelligence Developement Studio il_masacratore 21 February, 2014 - 17:36![]() Bids Helper es un add-in con funcionalidades que complementa y añade nuevas funcionalidades para el desarrollo en SQL Server 2005, 2008, 2008 R2, 2012 usando BI Development Studio. Es un complemento de libre descarga que se mantiene vivo al que se le continúan añadiendo nuevas posibilidades. Su posibilidad de uso abarca desde proyectos de Analysis Services con funcionalidades básicas, proyectos de Integration Services y en menor medida algo de Reporting Services.
Bids Helper es un add-in con funcionalidades que complementa y añade nuevas funcionalidades para el desarrollo en SQL Server 2005, 2008, 2008 R2, 2012 usando BI Development Studio. Es un complemento de libre descarga que se mantiene vivo al que se le continúan añadiendo nuevas posibilidades. Su posibilidad de uso abarca desde proyectos de Analysis Services con funcionalidades básicas, proyectos de Integration Services y en menor medida algo de Reporting Services.
Para instalar Bids Helper basta con cerrar cualquier instancia de Microsoft Bussiness intelligence Developemt Studio, descargar el instalador de este enlace y pulsar siguiente, siguiente, siguiente...
En cuanto a las funcionalidades nos proporciona este add-in, la lista es larga. Por ejemplo con Analysis Services tenemos la posibilidad de chequear la salud de una dimensión y ver como se usa dentro del cubo en la que la hemos añadido. Podemos editar agregaciones y generar scripts sobre múltiples elementos OLAP. También tenemos otro tipo de funcionalidad como puede ser la generación de informes sobre el uso de dimensiones. De Integration Services también tenemos otras como pueden ser el editor más completo de expresiones que ofrece. A continuación detallo algunas de las funcionalidades agrupadas por servicio:
Analisys Services
- Column Usage Reports: Informe autogenerado con el uso que se hace de las columnas de la vista del origen de datos.
- Unused Columns Report: Al contrario que el anterior, genera un listado con los campos contenidos que no se usan.

- Deploy MDX Script: Permite hacer un deploy selectivo para solo incluir los scripts de cálculo mdx.
- Deploy Perspectives: Deploya solo las perspectivas del cubo. Borra las del servidor no incluidas en la solución.
- Deploy Aggregation Designs: Algo más complicada que las anteriores pero con la misma filosofía. Deploya solo los diseño de agregaciones aunque no cambia la asignación del diseño de cada partición.
- Dimension Data Type Discrepancy Check: Perfecto para detectar problemas de desconexión del origen de datos o cambios a medias. Me explico. Muestra las diferencias entre los tipos de datos definidos para la columna origen y la definida en el atributo. Lo podemos hacer haciendo clic derecho en la carpeta Dimensiones del proyecto en el Explorador de Soluciones.
- Dimension health check: Revisión de la integridad de la dimensión que hace diferentes comprobaciones. Entre otras cosas, comprueba para las claves su no repetición. Debería valer para detectar que clave nos genera el problema en el procesado del cubo.

- Measure Group Health: Al estilo del anterior, permite validar el grupo de medidas. De momento solo comprueba los tipos de datos para que no haya desbordamiento.
- Non-Default Report Properties: Genera un report con el valor de propiedades que han sido modificadas. Fantástico para tener una vista global del cubo y buscar cosas raras sobretodo si hemos heredado la administración de ese cubo. Podemos seleccionar antes de genera el informe que cosas queremos mostrar: agregaciones, tratamiento de duplicados, claves no encontradas...


- Roles report: Informe con los diferentes usuarios con sus roles asignados y los permisos sobre dimensiones de los mismos.
- Visualize Attribute Lattice: Genera un informe gráfico con la relación entre atributos de la dimensión seleccionada.

Tabular modeling (Analisys Services)
También incluye opciones similares a las anteriores para Tabular Modeling. Tabular Modeling está disponible desde la versión 2012 de SQL Server y son bases de datos en memoria de Analysis Services. Entre las funcionalidades disponibles tenemos Roles Report, Smart Diff, Unused Columns Report, Tabular Prebuild etc.
Integration Services
- Design Warning: Añade a la lista de errores y warnings las cosas que no cumplen los estándares de diseño en nuestros paquetes de SSIS.
- Expressions List: Muestra un panel algo más amigable que muestra todas las expresiones definidas en el paquete. Además incluye un editor con más opciones y resumen de expresiones etc. Por cada paquete por el que pasamos podemos verlas pulsando Regresh.


- Non default Properties Report: Al igual que en Analysis Services, genera un informe con el valor de propiedades que han sido modificadas y que no tiene su valor por defecto. Útil para ver las peculiaridades. Podemos seleccionar antes de generar el informe que queremos que se incluya: Modos de acceso, BypassPrepare...
- Reset GUID's: Regenera los IDS para todas las tareas, conectores, configuraciones etc del paquete seleccionado. Puede ir bien en el caso que hagamos un copiar y pegar de alguna tarea del paquete.
- SSIS Performance Visualization: Esta opción ejecuta el paquete y añade una nueva perspectiva para ver como se ejecuta el paquete. Aparece una pestaña Performance que nos muestra un Gantt vivo, con el progreso de la ejecución del paquete. Permite ver también un grid con las estadísticas de tiempo e incluso una comparación entre las sucesivas ejecuciones del mismo paquete.

Reporting Services
- Dataset Usage Reports: Genera un autoinforme con los datasets que se usan en cada informe permitiendo identificar los que no están usándose actualmente (obsoletos?).
- Smart Diff: Según el repositorio de código que usemos, mejora la generación y visibilidad de diferencias respecto a la última versión (sobretodo si aún usamos Visual Source Safe 2005).
En conclusión...
... me parece un add-in muy útil ya a bote pronto permite generar mucha documentación de forma automática en muy pocos pasos. Además, relacionada con esta, el resumen de propiedades modificadas que no tienen su valor original facilita muchas veces el trabajo en proyectos heredados y poder pedir explicaciones al antiguo responsable si aún estamos a tiempo. Del resto de funcionalidades cada uno podemos tener una opinión sobre ellas pero estas solo suman. No creo que ninguna de ellas se imprescindible pero de vez en cuando podemos dar gracias de que están allí.
De hecho, a parte del tema de la documentación, en una ocasión a mi me ayudo mucho y me ahorro tiempo la opción de poder hacer el Dimension Health Check. Hubo un cambio en los datos que tenia actualizado en la vista de origen de datos pero no en la dimensión (momentos distintos) y al procesar el cubo de nuevo me daba errores. Anteriormente me había pasado y tarde bastante en encontrar el problema pero esta vez solucionarlo fue una cosa muy rápida (aunque quizás ya sabía lo que buscar).
Como migrar de Oracle a SQL Server usando SQL Server Migration Assistant for Oracle
Como migrar de Oracle a SQL Server usando SQL Server Migration Assistant for Oracle il_masacratore 10 March, 2014 - 16:20El proceso de migración de un sistema gestor de bases de datos Oracle a otro con Microsoft Sql Server puede llegar a ser un trabajo muy tedioso si lo hacemos a mano. Tiempo atrás quizás no había más remedio que empezar migrando la estructura para hacer luego cargas manuales por tablas etc. Una manera de hacer podría ser haciendo un script PL-SQL de la estructura en Oracle para modificarlo y pasarlo a T-SQL para SQL Server. Con el paso del tiempo han ido in-crescendo aplicaciones de pago y gratuitas que ya hacen gran parte de nuestro trabajo. MS SQL Server Migration Assistant es una de ellas totalmente gratuita, creada por Microsoft que nos permite hacer gran parte del trabajo.
Microsoft SQL Server Migration Asistant for Oracle, además de migrar los datos propiamente dichos (estructura de tablas y su contenido), migra procedimientos almacenados, funciones, triggers, sinónimos y vistas. Aunque no lo migre todo, por ejemplo las secuencias, nos facilita la mayor parte del trabajo trivial. Una de las gracias también de esta herramienta es que funciona con proyectos, lo que permite probar y modificar las veces que queramos el traspaso de información al estilo prueba-error. Para el resto de cosas, lo básico sería generarnos un script y redefinirlo para SQL Server (sea lo que sea). Un buen complemento para centralizar el resto de la migración podría ser un paquete de SQL Server Integration Services.

Aunque en este post me centro en la versión que permite hacer la migración de Oracle a SQL Server, existen las siguientes versiones que permiten hacer la migración desde otros tipos de bases de datos:
- Microsoft SQL Server Migration Assistant for MySQL v5.2: Permite hacer la migración desde versiones de MySQL 4.1 y superiores a MS SQL Server 2005 y superiores. Se puede descargar desde aquí.
- Microsoft SQL Server Migration Assistant for Sybase v5.2: Permite hacer la migración desde Sybase Adaptive Server Enterprise (ASE) 11.9 y superior a SQL Server 2005 y superior. Se puede descargar desde aquí.
- Microsoft SQL Server Migration Assistant for Access v5.2: Permite hacer la migración de Microsoft Acces 97 y superiores a SQL Server 2005 y superior. Se puede descargar desde aquí.
Como instalar Microsoft SQL Server Migration Assistant for Oracle v5.2
Para empezar con la instalación descargaremos de este enlace el instalador. Una vez descargado el fichero .zip lo descomprimimos y ejecutamos el fichero SSMA for Oracle 5.2.exe para realizar la primera parte.

La segunda parte de la instalación consiste en copiar el segundo instalador, SSMA for Oracle 5.2 Extension Pack en el servidor SQL Server destino y ejecutarlo para completar todo el proceso. Este último crea una base de datos para uso propio de la aplicación y copia algunas librerías en la instalación de SQL Server. Durante alguno de los pasos nos pedirá un usuario de la base de datos con permisos para crear base de datos.

En nuestra primera ejecución nos pedirá el fichero de licencia. Pese a ser una aplicación gratuita, Ms nos pide tener en una ubicación un fichero de licencia para la versión concreta de nuestra aplicación. En el caso de la versión 5.2, independientemente de la versión de la base de datos origen nos la podemos descargar de este enlace.

Empezando a usarlo
Para ejecutarlo basta con buscarlo en el menú inicio. Nada más abrirlo, seleccionaremos del Menú File > New Project, donde elegiremos la ruta donde guardar el proyecto y seleccionamos la versión de SQL Server destino.
Las primeras pruebas son interesantes para hacerlas con los entornos de test o desarrollo que estén a nuestra disposición y en el peor de los casos, si solo tenemos entornos de producción probaremos con esquemas pequeños.
- Primero nos conectaremos a Oracle, el origen de los datos. En el dialogo elegimos entre el cliente Oracle Client provider o el proveedor OleDb y luego desplegaremos el Mode para especificar de distintas maneras los datos del servidor origen ya sea mediante cadena de conexión, TNSNAMES o Standard (campo a campo).

Una vez lo hagamos, la aplicación se conecta y descarga los metadatos para mostrarnos los esquemas visibles. Por cuestión clara de permisos, según el usuario que especifiquemos en la conexión veremos más o menos. Si queremos hacer una migración de todo podemos necesitar al usuario system de Oracle.
- El siguiente paso puede ser conectarnos al servidor destino. Para hacerlo elegimos la opción Connect to SQL Server de debajo del menú.

Por cierto, es posible que por algún motivo nos despistemos y no hayamos instalado en el servidor el "Extension Pack". Lo instalamos y solucionado. El error que veremos será como el de la siguiente imagen:

- Una vez conectados al servidor origen y destino es momento de empezar a jugar. En la parte superior tenemos primero el Oracle Metadata Explorer y una pestaña a su derecha que nos muestra la información relativa al origen. En la parte inferior tenemos el SQL Server Metadata Explorer que muestra lo mismo para el servidor destino. El "Metadata Explorer" es el árbol de objetos de cada servidor. Es como un Explorador de objetos para las dos bases de datos. Lo único a tener en cuenta es que mientras en Oracle hablamos de diferentes esquemas para una misma base de datos, en MS SQL Server vemos las diferentes bases de datos y los esquemas de seguridad que contiene cada una de ellas.

Para empezar a jugar y mover cosas de un lado al otro basta saber que tenemos que seleccionar en el árbol superior lo que queremos como en la imagen superior y hacerle clic con el botón derecho para poder ver el menú que permite ver que operaciones hacer con el: migrar, generar su script, informe de migración...
En conclusión...
... esta herramienta puede ser muy útil para simplificar el trabajo en migraciones de Oracle a SQL Server y otros tipos parecidos mientras el destino sea SQL Server. Como se puede ver en el blog de la gente que la mantiene (incluso tiene un blog!), está actualizada y se mantiene al día con las nuevas versiones de cada tipo de base de datos.
Me parece muy útil.
Cómo generar sentencias SQL de administración para eliminar tablas y vistas
Cómo generar sentencias SQL de administración para eliminar tablas y vistas Carlos 13 February, 2021 - 20:05Construcción automatizada de sentencias SQL
Los metadatos que guardan las bases de datos sobre la estructura de sus objetos son muy útiles para realizar tareas que requieran hacer algo sobre todos los objetos de un esquema, de una base de datos, de un tipo determinado, con un patrón en el nombre del objeto, etc.
En SQL Server, con las vistas que la base de datos nos da sobre el catálogo podemos consultar, entre otras muchas cosas, los nombres de objetos de las bases de datos como tablas o vistas.
Si lo que queremos hacer es eliminar todas las tablas y vistas de un determinado esquema de una base de datos 'DBName', por ejemplo, conectados a DBName o incluyendo el nombre de la base de datos en la consulta, podemos consultar en las vistas de sistema de SYS.OBJECTS y SYS.SCHEMA de objetos y esquemas, respectivamente, para construir nuestras sentencias de DROP Table en un segundo.

Consulta de ejemplo para generar DROPS de las tablas y vistas de dos esquemas
select 'DROP '
+ CASE type WHEN 'U' THEN 'Table' WHEN 'V' THEN 'View' END
+ ' [' + sc.name + '].[' + ob.name + '];'
from DBName.sys.objects OB
join DBName.sys.schemas SC on OB.schema_id=SC.schema_id
where sc.name in ('dbo','USER')
and ob.type in ('U','V')
order by ob.type, ob.nameEsta sentencia nos devuelve montadas las consultas para todas las tablas y vistas que contengan los esquemas incluídos en el IN, en este caso 'dbo' y 'User', de la base de datos con mobre 'DBName'.
Después sólo es cuestión de copiar las queries generadas, revisarlas, sobretodo teniendo en cuenta que son DROPs, e incluirlas en nuestro script, o ejecutarlas directamente desde el SSMS, por ejemplo.
Tabla de codificación para tipos de objeto de SYS.OBJECTS
Como ayuda, esta es la codificación de los tipos de objetos que podemos encontrarnos en la vista sys.objects, en el campo 'type'. En nuestro caso hemos filtrado por 'Tablas de usuario' y 'Vistas' con 'U' y 'V'.
| Tipo de objeto:
AF = Función de agregado (CLR) Válido para : SQL Server 2012 (11.x) y versiones posteriores. Se aplica a: SQL Server 2016 (13.x) y versiones posteriores, Azure SQL Database , Azure Synapse Analytics (SQL Data Warehouse) , Almacenamiento de datos paralelos . |
Una alternativa, generar SQL con INFORMATION_SCHEMA
Utilizando las vistas de INFORMATION_SCHEMA se podría conseguir lo mismo y con una consulta más sencilla, pero mejor ir acostumbrándose a las vistas de sys, que son las más fiables, y las que parece que van a quedarse a la larga.
Ejemplo para crear DROP de tablas dinámico con INFORMATION_SCHEMA
SELECT
'DROP ' + right(table_type,5) + ' [' + TABLE_SCHEMA + '].[' + TABLE_NAME + '];'
FROM
DBName.INFORMATION_SCHEMA.TABLES
where table_schema not in ('dbo','USER')
order by table_schema, table_type, table_name
Las vistas del catálogo te pueden ahorrar mucho tiempo
Esta es una aplicación típica que pongo como ejemplo, pero utilizar las vistas del catálogo para generar consultas dinámicamente nos puede ahorrar un montón de tiempo y asegurarnos de que no nos dejamos nada en muchas tareas de administración de la base de datos que requieran consultar o realizar acciones sobre grupos de objetos.
Por último, en el post de Consultas Útiles para SQL Server hay otras consultas sobre el catálogo, que combinadas con esta manera de generar queries de administración pueden ahorrar mucho trabajo y facilitar la administración o el desarrollo con SQL Server.
Que tiene y como instalar SQL Server Express 2012
Que tiene y como instalar SQL Server Express 2012 il_masacratore 6 February, 2014 - 09:01 Para quién no lo sepa, SQL Server Express es una edición gratuita en miniatura de Sql Server. Esta versión está pensada para aplicaciones de escritorio y/o pequeñas aplicaciones web o de servidor. Esta base de datos se puede considerar la versión competidora a la versión gratuita de Oracle (Oracle XE). Ambas versiones están siempre al día y se han ido actualizando con el paso de los años y versiones. De hecho, el lanzamiento de la primera versión Express fue con la versión de SQL Server 2005.
Para quién no lo sepa, SQL Server Express es una edición gratuita en miniatura de Sql Server. Esta versión está pensada para aplicaciones de escritorio y/o pequeñas aplicaciones web o de servidor. Esta base de datos se puede considerar la versión competidora a la versión gratuita de Oracle (Oracle XE). Ambas versiones están siempre al día y se han ido actualizando con el paso de los años y versiones. De hecho, el lanzamiento de la primera versión Express fue con la versión de SQL Server 2005.
Si es gratis, ¿Donde está el truco en SQL Server Express?
Pues que básicamente solo contamos con el motor de base de datos y poco más. Generalizando, el truco está en que este tipo de versiones, tanto la de Oracle como la de SQLServer, cuentan con cierto tipo de limitaciones, la mayoría ligadas a la capacidad de procesamiento o otras más ligadas al mundo empresarial como podría ser Analisys Services. En el caso de SQL server Express 2012, las principales limitaciones son:
- El volumen máximo de la base de datos está limitado a 10Gb con la versión 2012
- Límite de 1 socket o 4 núcleos para el procesamiento de la base de datos.
- El máximo de memoria que usará la instancia será de 1gb.
A efectos prácticos, estas tres no son impeditivas y nos pueden permitir usar esta base de datos en pequeñas aplicaciones de escritorio como pueden ser puntos de venta etc. Luego existen otro tipos de limitaciones que está bien saberlas (para características compatibles, las que no tiene ni las menciono):
- Puede activarse como base de datos espejo (mirroring), aunque solo como testigo.
- Puede ser suscriptora en un servicio de replicación.
- Incluye también los servicios de Búsqueda de Texto (fulltext search).
- Permite almacenamiento FILESTREAM.
A partir de la versión 2008 de SQL Server Express, se ha complementado la propia base de datos con el servicio de informes de Reporting Services. Es la versión conocida como "SQL Server Express con Servicios Avanzados". Esta está muy bien. En el ejemplo anterior, el del punto de venta, podemos agilizar mucho el desarrollo e implantación de informes para la aplicación.
Por último, con la versión 2012 podemos usar la característica LocalDb. Esta es una nueva opción que permite simplificar mucho el despliegue y que se instala de realmente rápido. Incluso permite embeber la base de datos en la aplicación que la contiene y estar funcionando en el mismo proceso de la aplicación en lugar de como servicio.
Cómo instalar SQLServer Express 2012
Para empezar nos vamos a la página del producto y descargamos el instalador. Cuando hagamos click deberemos elegir el tipo de instalador (a elegir de entre cinco tipos distintos!):
- SQL Server Express con Herramientas (con LocalDb, incluye el motor de base de datos y SQL Server Management Studio Express)
- SQL Server Management Studio (solo herramientas)
- SQL Server Express LocalDb (instalador MSI)
- SQL Server Express con Servicios Avanzados
- SQL Server Express (solo motor de base de datos).
De los anteriores, que ya vienen con su propia descripción solo destacaría el paquete MSI de SQL Server Express LocalDb para el ejemplo del punto de venta. El paquete MSI es justo lo necesario para incrustar el instalador de la parte de la base de datos en el instalador de la aplicación que la va a usar. Como he comentado antes, la otra descarga destacable es SQL SERVER Express con Servicios Avanzados que es la que lleva Reporting Services.
El paso siguiente es lanzar el instalador par llegar al Centro de instalación de SQL Server.

Continuamos con un par de siguientes, siguiente para buscar actualizaciones. A continuación se copian los archivos del programa de instalación, se comprueban las reglas auxiliares y ya pasamos a elegir las características a instalar. Pulsamos siguiente y se empiezan a copiar los archivos.

Como requisitos previos, se necesita .NET Framework 3.5 Service Pack 1 y poder acceder al centro de descargas para poder actualizar con la versión 4.0. Esto podemos creer que lo podemos evitar desencargando de antemano y sobretodo tenemos que tener en cuenta que necesitaremos también el paquete redristibuible para una posible instalación de localdb(la versión embebida). Pero no es el caso. La comprobación siempre se hace aun con la versión 4.0 ya instalada.
El paso siguiente a la elección de las características es la configuración de la instancia. Debemos especificar el nombre y directorio raíz.

Seguimos con la configuración de las cuentas que ejecutaran los distintos servicios incluidos (el motor del sgbd, reporting services y sql server browser). Recordar que Sql Server Browser es como un "agente" que publica en la red la existencia de la instancia de SQL Server. Por defecto viene deshabilitado y si no es por causa mayor mejor dejarlo así.

El siguiente paso es elegir el modo de autenticación y los administradores de la base de datos. Generalmente nos conviene elegir mixto si esta base de datos se necesita usar en la red local o autenticación de windows si directamente es de uso local y no queremos complicarnos. A diferencia de una versión superior o completa del producto, como esta versión express suele acompañar a una aplicación y es de uso local, elegiremos modo de autenticación de windows y como administrador el usuario actual.

Uno de los últimos pasos será la configuración de Reporting Services. Para esta instalación simple basta con dejar la primera opción seleccionada, la que permite usarlo en modo nativo SIN integración con sharepoint services.

Un siguiente más para la privacidad y la notificación de errores a Microsoft y ya lo tenemos instalado. Esperamos una pantalla como la siguiente:

Finalmente reiniciamos y ya tenemos instalada la versión express de sqlserver 2012 con servicios avanzados. Si hiciera falta modificar en un futuro cualquier configuración podemos cambiar las opciones generales si vamos al Menú Inicio> SQL Server 2012>Herramientas de Configuración>Administración de configuración de SQL SERVER. En la misma carpeta del menú inicio también podemos cambiar cualquier cosa relativa a Reporting Services si elegimos Administración de configuración de Reporting Services.
Resumiendo...
Microsoft SQL Server express es una buena opción como base de datos embebida, más sencilla que su versión de Oracle equivalente y con más posibilidades en cuanto a uso. En contraposción, no hay quien gane en simplicidad a Mysql. En global SQL Server Express es una muy buena opción para desarrollos .net y pequeñas bases de datos que incluso puedan necesitar algún informe. Desde que le acompaña Reporting Services la hace más atractiva.
Como se agrega Analisis
Como se agrega Analisis services despues de Instalar la version Express
- Log in to post comments
Con la versión Express puedes
Con la versión Express puedes agregar y utilizar SQL Express Advanced Services, que te permite utilizar Reporting Services, pero con la versión Express no puedes instalar Analysis Services, es decir, que no hay un Analysis Services Express. Lo de 'Advanced' es fácil que se confunda con 'Analysis', pero no es lo mismo.
Lo que sí puede hacer un SQL Server Express es conectar con un Integration Services o un Analysis Services que tengas licenciado e instalado en otro servidor.
En este sitio lo explican bastante bien.
- Log in to post comments
cuando subo la base de datos
- Log in to post comments
SQL Server: Auditoría de datos personalizada mediante triggers
SQL Server: Auditoría de datos personalizada mediante triggers il_masacratore 31 March, 2014 - 13:08Los triggers o desencadenadores son disparadores que saltan cuando realizamos la acción o evento al que van asociados. En MS SQL Server, además de los triggers clásicos relacionados con acciones DML (insert, update, delete) que se ejecutan en su lugar (instead of) y después (after triggers), desde SQL Server 2008 (por lo menos) existe otro tipo que son los triggers asociados a acciones que se producen por consultas DDL. Este segundo tipo de trigger está más pensado para labores administrativas como la propia auditoria, para el control de cierto tipo de operaciones e incluso evitar esos cambios.
Con la combinación de ambos tipos de trigger podemos conseguir una auditoria bastante completa para saber quién se conecta, cuando lo hace, que objetos modifica e incluso que registros ha modificado y/o guardar una copia del registro anterior si hablamos de una tabla sensible.
Primero empezamos por hacer un seguimiento de los cambios básico a nivel de tabla. Para ello podemos usar los triggers que se lanzan a causa de consultas DML (insert, update) para hacer tracking de quien inserta o modifica cada registro. Luego elegiremos que tipo de trigger usaremos, el que se desencadena posteriormente al evento (AFTER, equivalente a FOR de versiones anteriores) o el que desencadena en lugar de la acción (INSTEAD OF). Tanto en un tipo de trigger como en el otro, podemos hacer referencia a los nuevos valores mediante una tabla inserted u otra tabla deleted para acceder a los registros anteriores a la modificación.
Vamos con un primer ejemplo donde queremos hacer tracking de usuarios de creación y el de la última modificación, además de fechas, en la misma tabla donde están los datos y queremos hacerlo de forma sencilla. Partimos de una tabla básica de empleados, a la que le añadimos los campos de auditoría:
-- Partimos de una tabla de empleados CREATE TABLE [dbo].[EmpTable]( [EmployeeID] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](100) NOT NULL, [JobDescription] [nvarchar](30) NULL, PRIMARY KEY (EmployeeID) ON [PRIMARY])
-- Añadimos los campos básicos de auditoría (RowCreator, RowCreationDate, RowModifier, RowModifiedDate) ALTER TABLE [dbo].[EmpTable] ADD RowCreator [nvarchar](20), RowCreationDate datetime, RowModifier [nvarchar](20), RowModifiedDate datetime
-- Creamos el trigger primero para alimentar los campos de auditoria en la inserción de nuevos registros. ALTER TRIGGER EmpTable_InstOfInsert ON [EmpTable] INSTEAD OF INSERT AS BEGIN SET NOCOUNT ON DECLARE @User nvarchar(30) SELECT @User = SUSER_NAME() INSERT INTO [EmpTable] (EmployeeID, Name, JobDescription, RowCreator, RowCreationDate, RowModififer, RowModifiedDate) SELECT i.EmployeeID, i.Name, i.JobDescription, @User, GETDATE(), @User, GETDATE() FROM inserted i END
Ahora creamos el trigger de actualización. A diferencia del trigger de inserción, al hacer UPDATE es posible qu estemos actualizando más de un registro a la vez de la misma tabla por una misma sentencia. Por ello deberemos usar un cursor para recorrer cada uno que se encuentre en la tabla "inserted" para ir alimentando los datos de auditoría en la tabla original.
-- Creamos el trigger para la actualización CREATE TRIGGER EmpTable_AfterUpdate ON EmpTable AFTER UPDATE AS BEGIN SET NOCOUNT ON DECLARE @User nvarchar(30) DECLARE @SysDate datetime DECLARE cInserted CURSOR FOR SELECT EmployeeID FROM inserted; DECLARE @ID int SELECT @SysDate = GETDATE() SELECT @User = SUSER_NAME() OPEN cInserted FETCH NEXT FROM cInserted INTO @ID WHILE @@FETCH_STATUS = 0 BEGIN UPDATE EmpTable SET RowModififer = @User, RowModifiedDate = @SysDate WHERE ID = @ID FETCH NEXT FROM cInserted INTO @ID END CLOSE cInserted DEALLOCATE cInserted END
En el ejemplo anterior, tanto para la actualización como para la inserción estamos capturando solo los últimos cambios y solo datos de auditoría. En otro ámbito o tipo de datos, además nos puede interesar guardar en otra tabla anexa los antiguos valores del registro modificado (Imaginaros una tabla sensible con datos de configuración de la que queremos guardar el historial de cambios). Lo podemos conseguir con un trigger similar al siguiente:
-- Esta sería una posible estructura de la tabla original de configuración CREATE TABLE [dbo].[ConfigurationTable]( [KeyID] [int] IDENTITY(1,1) NOT NULL, [ParameterCode] [nvarchar](30)NOT NULL, [ParameterDescription] [nvarchar](100) NULL, [ParameterValue] [nvarchar](30) NULL PRIMARY KEY (ParameterCode) ON [PRIMARY])
-- Nosotros querríamos saber el historial de cambios. Crearíamos otra tabla con una estrucutra similar... CREATE TABLE [dbo].[ConfigurationTable_OldValues]( [KeyID] [int] NOT NULL, [ParameterCode] [nvarchar](30)NOT NULL, [ParameterDescription] [nvarchar](100) NULL, [NewParameterValue] [nvarchar](30) NULL, [OldParameterValue] [nvarchar](30) NULL, [RowModifier] [nvarchar](20), [RowModifiedDate] datetime)
-- Creamos el trigger para controlar la actualización de la tabla original e insertar los datos en la tabla de valores históricos ([ConfigurationTable_OldValues]) CREATE TRIGGER ConfigurationTable_AfterUpdate ON ConfigurationTable AFTER UPDATE AS BEGIN SET NOCOUNT ON DECLARE @User nvarchar(30) DECLARE @SysDate datetime DECLARE cInserted CURSOR FOR SELECT [KeyID], [ParameterCode], [ParameterDescription], [ParameterValue] FROM inserted DECLARE @keyId int DECLARE @parametercode [nvarchar](30) DECLARE @parameterdescription [nvarchar](100) DECLARE @parametervalue [nvarchar](30) SELECT @SysDate = GETDATE() SELECT @User = SUSER_NAME() OPEN cInserted FETCH NEXT FROM cInserted INTO @keyId , @parametercode , @parameterdescription , @parametervalue WHILE @@FETCH_STATUS = 0 BEGIN INSERT INTO [ConfigurationTable_OldValues] ([KeyID], [ParameterCode], [ParameterDescription], [NewParameterValue], [OldParameterValue] , [RowModifier] , [RowModifiedDate] ) SELECT @keyId, @parametercode, @parameterdescription, @parametervalue, d.[ParameterValue] , @User, @sysdate FROM deleted d WHERE d.[ParameterCode] = @parametercode FETCH NEXT FROM cInserted INTO @keyId , @parametercode , @parameterdescription , @parametervalue END CLOSE cInserted DEALLOCATE cInserted END

-- Hacemos un insert de prueba y un update para ver los resultados
INSERT INTO [dbo].[ConfigurationTable]
([ParameterCode]
,[ParameterDescription]
,[ParameterValue])
VALUES
('Processes'
,'Numero de procesos'
,'10'
)
GO
UPDATE [dbo].[ConfigurationTable]
SET [ParameterValue] = '20'
WHERE [ParameterCode] = 'Processes'
GO

Si probamos todo el código anterior y consultamos la última tabla veremos el "tracking" del cambio de valor para el registro. Podríamos usar un trigger similar para guardar datos de registros borrados e insertarlos en otra tabla. Por último, un par de comentarios a tener en cuenta a nivel general cuando trabajamos con triggers:
- Se definen sobre una tabla especifica. Un trigger no sirve para dos o más tablas (aunque tengan el mismo código, debemos crear uno por cada una de las tablas...).
- El trigger se crea en la base de datos que de trabajo pero desde un trigger puedes hacer referencia a otras bases de datos.
- Un Trigger devuelve resultados al programa (ouput, mensaje de "filas afectadas") como lo puede hacer un procedure. Para impedir outputs no deseados utilizamos la sentencia SET NOCOUNT al principio del trigger.
En resumen...
... esta es una manera de hacer auditoría a medida para controlar los cambios en los datos de tabla. Nos puede ir bien hacerlo con las que contienen datos sensibles. Es posible que cuando queramos hacerlo, las tablas que queremos controlar sean de una aplicación de terceros y que la compatibilidad no sea al 100% ya que si añadimos campos provocaremos errores en sus sentencias SQL y eso nos impide modificar sus tablas. En ese caso la manera de hacerlo es la segunda, es decir, otra tabla donde guardamos cambios o solo ids. porque de alguna manera no altera la estructura, sino que informamos una tabla anexa a medida con los cambios que queremos guardar, ya sea solo auditoria o valores antiguos.
Muy interesante el articulo,
- Log in to post comments
El código tiene algunos
El código tiene algunos detalles, ya lo corregí
-- Partimos de una tabla de empleados
CREATE TABLE [dbo].[EmpTable]( [EmployeeID] [int] IDENTITY(1,1) NOT NULL, [Name] [nvarchar](100) NOT NULL, [JobDescription] [nvarchar](30) NULL, PRIMARY KEY (EmployeeID) ON [PRIMARY])
-- Añadimos los campos básicos de auditoría (RowCreator, RowCreationDate, RowModifier, RowModifiedDate)
ALTER TABLE [dbo].[EmpTable] ADD RowCreator [nvarchar](20), RowCreationDate datetime, RowModifier [nvarchar](20), RowModifiedDate datetime
-- Creamos el trigger primero para alimentar los campos de auditoria en la inserción de nuevos registros.
--
GO
CREATE TRIGGER EmpTable_InstOfInsert ON [EmpTable] INSTEAD OF INSERT AS BEGIN SET NOCOUNT ON DECLARE @User nvarchar(30)
SELECT @User = SUSER_NAME() INSERT INTO [EmpTable] (EmployeeID, Name, JobDescription, RowCreator, RowCreationDate, RowModifier, RowModifiedDate) SELECT i.EmployeeID, i.Name, i.JobDescription, @User, GETDATE(), @User, GETDATE()
FROM inserted i
END
--------------------------------------------------------------------------------------------------------------------------------
-- Esta sería una posible estructura de la tabla original de configuración
CREATE TABLE [dbo].[ConfigurationTable]( [KeyID] [int] IDENTITY(1,1) NOT NULL, [ParameterCode] [nvarchar](30)NOT NULL, [ParameterDescription] [nvarchar](100) NULL, [ParameterValue] [nvarchar](30) NULL PRIMARY KEY (ParameterCode) ON [PRIMARY])
-- Nosotros querríamos saber el historial de cambios. Crearíamos otra tabla con una estrucutra similar...
CREATE TABLE [dbo].[ConfigurationTable_OldValues]( [KeyID] [int] NOT NULL, [ParameterCode] [nvarchar](30)NOT NULL, [ParameterDescription] [nvarchar](100) NULL, [NewParameterValue] [nvarchar](30) NULL, [OldParameterValue] [nvarchar](30) NULL, [RowModifier] [nvarchar](20), [RowModifiedDate] datetime)
GO
-- Creamos el trigger para controlar la actualización de la tabla original e insertar los datos en la tabla de valores históricos ([ConfigurationTable_OldValues])
CREATE TRIGGER ConfigurationTable_AfterUpdate ON ConfigurationTable AFTER UPDATE AS
BEGIN SET NOCOUNT ON
DECLARE @User nvarchar(30)
DECLARE @SysDate datetime
DECLARE cInserted CURSOR FOR SELECT [KeyID], [ParameterCode], [ParameterDescription], [ParameterValue] FROM inserted
DECLARE @keyId int
DECLARE @parametercode [nvarchar](30)
DECLARE @parameterdescription [nvarchar](100)
DECLARE @parametervalue [nvarchar](30)
SELECT @SysDate = GETDATE()
SELECT @User = SUSER_NAME()
OPEN cInserted FETCH NEXT FROM cInserted INTO @keyId , @parametercode , @parameterdescription , @parametervalue WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO [ConfigurationTable_OldValues] ([KeyID], [ParameterCode], [ParameterDescription], [NewParameterValue], [OldParameterValue] , [RowModifier] , [RowModifiedDate] )
SELECT @keyId, @parametercode, @parameterdescription, @parametervalue, d.[ParameterValue] , @User, @sysdate
FROM deleted d WHERE d.[ParameterCode] = @parametercode
FETCH NEXT FROM cInserted INTO @keyId , @parametercode , @parameterdescription , @parametervalue
END
CLOSE cInserted DEALLOCATE cInserted
END
-- Hacemos un insert de prueba y un update para ver los resultados
INSERT INTO [dbo].[ConfigurationTable] ([ParameterCode] ,[ParameterDescription] ,[ParameterValue]) VALUES ('Processes' ,'Numero de procesos' ,'10' )
GO
UPDATE [dbo].[ConfigurationTable] SET [ParameterValue] = '20' WHERE [ParameterCode] = 'Processes'
GO- Log in to post comments
Agradezco el tiempo que se
Agradezco el tiempo que se toma para enseñar a otros y admito que solamente ojeé muy ligeramente el código aquí presentado, pero debo hacer notar que el uso de cursores en esos triggers es muy innecesario. Además parece no concordar con los nombres de campos. En una sentencia la clave primaria de la tabla es EmployeeID y en otra es ID. Update EmpTable Set RowModifier = SUSER_NAME() , RowModifiedDate = GETUTCDATE() From EmpTable As e Inner Join inserted As i On e.EmployeeID = i.EmployeeID ; Y listo. Todos en un único UPDATE. Cero cursores.
- Log in to post comments
SQL Server: Como examinar el registro de transacciones
SQL Server: Como examinar el registro de transacciones il_masacratore 27 February, 2014 - 10:25En un momento dado, alguien puede modificar los datos de una tabla sensible. En otra ocasión, algún despistado puede borrar una tabla o incluso unos registros de otra tabla que no debería. Si ese "alguien" se da cuenta y honestamente nos lo comenta no pasa nada, como dba seguro que tenemos alguna copia de respaldo para poder recuperar esos datos: ya sea desde el backup nocturno, al combinado del backup con alguna copia del registro de transacciones si es una tabla que cambia continuamente (intentamos hacer un restore a una hora concreta). El problema lo podemos tener con tablas que no se usan apenas o que alguien ha borrado y no ha confesado. Para poder empezar nuestra búsqueda necesitamos habilitado el seguimiento de cambios para la base de datos en cuestión. En este post veremos como examinar el contenido del log con una base de datos de prueba.
Es cierto que existen algunas herramientas que ya permiten explorar de forma más automatizada el registro de transacciones. Por ejemplo, si hablamos de Oracle, Toad ya tiene el LogMiner, una opción de menú que nos permite ver el detalle de cada archivelog (fichero del registro de transacciones). Para MS SQL Server tenemos por ejemplo ApexSql Discovery and Recovery Tool. Estas aplicaciones lo hacen más fácil, más bonito y más rápido pero tienen un coste de licencia y en los tiempos que corren ya se sabe... Volviendo al tema, estas dos como muchas otras herramientas, no hacen magia y lo que acaban haciendo podemos encontrar la manera de hacerlo nosotros directamente (aunque nos cueste más tiempo y esfuerzo). En MS SQL Server, el caso que nos ocupar, para desgranar el contenido del registro de transacciones usaremos la función no documentada fn_dblog. Como parámetros solo requiere un Log Sequence Number (LSN) inicial y un LSN final. Como parámetro por defecto tiene el valor NULL y nos devolverá el contenido de todo el registro de transacciones. Vamos a probar con una base de datos limpia del entorno de desarrollo:
-- Script creación de la base de datos USE [master]; GO CREATE DATABASE [Testdb]; GO -- Creación de una tabla USE [Testdb]; GO CREATE TABLE [Articulos] ( [IdArticulo] INT IDENTITY, [FechaCreacion] DATETIME DEFAULT GETDATE (), [Codigo] CHAR (5) NOT NULL, [Descripcion] CHAR(20) NULL);
Aquí ya es momento de probar. Ejecutamos la consulta con la función fn_dblog para explorar que tenemos hasta ahora (solo con la creación de la base de datos y una tabla).
-- Primero vemos la cantidad USE [Testdb] GO SELECT COUNT(*) FROM fn_dblog(NULL, NULL) -- Vemos el detalle SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Transaction SID], [SPID], [Begin Time] FROM fn_dblog(null,null)
Cuando observamos el resultado de la consulta para ver el detalle, podemos empezar por identificar los diferentes TransactionName. Ahora encontraremos "TestDb" para cuando empieza la creación de la base de datos y "CREATE TABLE" cuando empieza con la tabla. A partir de estos registros, si nos seguimos desplazando y comparando el Transaction ID vemos las operaciones internas que se incluyen en cada operación. En la foto inferior está el resultado. Si nos fijamos cada "transacción" empieza con un Operation del tipo LOP_BEGIN_XACT y se cierra con LOP_COMMIT_XACT (unos registros más abajo).

Lo siguiente será seguir investigando y ver que pasa con otro tipo de consultas DML como inserciones o actualizaciones.
-- Script con un INSERTy UPDATE
USE [Testdb];
GO
INSERT INTO [Articulos] (Codigo, Descripcion) VALUES ('00001','Scott Spark MTB')
GO
UPDATE [Articulos]
SET [Descripcion] = 'MTB Scott Spark 226'
WHERE [Codigo] = '00001'
GO
-- Vemos el detalle de nuevo
SELECT [Current LSN],
[Operation],
[Transaction Name],
[Transaction ID],
[Transaction SID],
[SPID],
[Begin Time]
FROM fn_dblog(null,null)Ahora miraremos de nuevo el resultado de la consulta y buscaremos el Transaction Name del tipo INSERT o UPDATE. Esta vez, miraremos en el resultado pero nos fijaremos los registros donde el SPID sea el mismo y no es nulo (en la imagen es 53). Si nos desplazamos veremos en que se traduce internamente el INSERT: primero el registro, la obtención de una página de datos donde insertar y la actualización de estadísticas (TransactionName=AutoCreateQPStats) de la tabla. El caso del update ya es más simple y se traduce solo en una Operation Name UPDATE y a nivel más bajo en vemos el BEGIN_XACT, LOP_MODIFY_ROW y LOP_COMMIT_XACT.

A continuació algunas consultas útiles sobre el resultado de la ejecución de fn_dblog:
- Consulta filtrada para ver a un nivel más alto las operaciones que tienen lugar, incluidas las de sistema:
SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Transaction SID], [SPID], [Begin Time] FROM fn_dblog(null,null) WHERE [Transaction Name] IS NOT NULL
- Consulta para ver los principales tipos de consulta DML (INSERT, UPDATE, DELETE). Destacar el campo AllocUnitName que permite ver la tabla afectada y BeginTime con la fecha inicio:
SELECT
[Current LSN],
[Transaction ID],
[Operation],
[Transaction Name],
[CONTEXT],
[AllocUnitName],
[Page ID],
[Slot ID],
[Begin Time],
[End Time],
[Number of Locks],
[Lock Information]
FROM sys.fn_dblog(NULL,NULL)
WHERE Operation IN
('LOP_INSERT_ROWS','LOP_MODIFY_ROW', 'LOP_DELETE_ROWS','LOP_BEGIN_XACT','LOP_COMMIT_XACT')- Consulta para ver la frecuencia con la que ocurren los "Page Splits". Estos ocurren cuando los cambios de la fila no caben en la página de datos que tocaría y se mueven a una nueva (que tengan lugar son malos si hablamos en términos de rendimiento!):
SELECT [Current LSN], [Transaction ID], [Operation], [Transaction Name], [CONTEXT], [AllocUnitName], [Page ID], [Slot ID], [Begin Time], [End Time], [Number of Locks], [Lock Information] FROM sys.fn_dblog(NULL,NULL) WHERE [Transaction Name]='SplitPage' GO
En conclusión...
..., saber que podemos explorar los cambios realizados recientemente y que mantenemos en el registro de transacciones puede ser útil en determinadas circunstancias, como algunas que comentamos arriba. Va bien incluso saber que se guarda el SPID ya que si mantenemos algún registro de las conexiones a la base de datos (mediante triggers de servidor por ejemplo) podemos enlazar una cosa con la otra: saber que cambio y quién lo hizo. En otro post ya comentaré el caso de los registros eliminados y como restablecerlos. Por cierto, si llegamos a probar esto en el entorno de producción porque podemos consumir bastantes recursos en la operación.
Libros de SQL Server
¿Quieres profundizar más en Transact-SQL o en administración de bases de datos SQL? Puedes hacerlo consultando alguno de estos libros de SQL Server
Mejor revisa la lista completa de los últimos libros de SQL Server publicados en Amazon según lo que te interese aprender, pero estos son los que a mi me parecen más interesantes, teniendo en cuenta precio y temática:
- eBooks de SQL Server gratuítos para la versión Kindle, o muy baratos (menos de 4€):
- Libros recomendados de SQL Server
Carlos, excelente el aporte.
Carlos, excelente el aporte. Para tener presente en más de un caso.
Saludos
- Log in to post comments
Hola, yo necesito algo
Hola, yo necesito algo parecido, pero para saber qué hace un Stored Procedure en concreto. Es decir, lanzo el Stored Procedure y necesito saber qué consulta o modificación hace hasta que termine.
¿Se puede hacer?
Supongo que es algo muy parecido a "Consulta para ver los principales tipos de consulta DML (INSERT, UPDATE, DELETE)"
Saludos y gracias.
- Log in to post comments
con esta consulta te arroja
con esta consulta te arroja la info
SELECT
[Current LSN],
[Transaction ID],
[Operation],
[Transaction Name],
[CONTEXT],
[AllocUnitName],
[Page ID],
[Slot ID],
[Begin Time],
[End Time],
[Number of Locks],
[Lock Information]
FROM sys.fn_dblog(NULL,NULL)
WHERE Operation IN
('LOP_INSERT_ROWS','LOP_MODIFY_ROW', 'LOP_DELETE_ROWS','LOP_BEGIN_XACT','LOP_COMMIT_XACT')
- Log in to post comments
Una pregunta... como puedo
Una pregunta... como puedo saber en que fecha se ingreso un registro a una tabla sin tener un campo fecha en esa tabla ???
saludos
- Log in to post comments
hola tengo una pregunta como
- Log in to post comments
Estimado, como puedo saber
- Log in to post comments
Buen Día como hago para
- Log in to post comments
Hola buenas tardes, por que
Hola buenas tardes, por que el tipo de Operacion = LOP_DELETE_RWO no tiene asociado el SPID. Como puedo ver el SPID asciado a ese tipo de OPERACION Saludos.
- Log in to post comments
Como puedo restaurar o
Como puedo restaurar o adjuntar una base de datos master de un servidor a otro diferente? usando Transact-SQL y/o Management Studio.
- Log in to post comments
Buenas y gracias por tu gran
Buenas y gracias por tu gran aporte muy bueno. como puedo hacer que me arroje los cambios de una tabla, y me indique que usuario fue quien gereno ese cambio en la tabla o en la base de datos, por favor estoy parado para optener este resultado te lo agradeceria. gracias.
- Log in to post comments
SQL Server Profiler: Cómo capturar consultas SQL y el detalle de su plan de ejecución
SQL Server Profiler: Cómo capturar consultas SQL y el detalle de su plan de ejecución il_masacratore 23 January, 2014 - 18:49 Casi siempre nos enteramos de que alguna query va lenta por alguna queja de usuario. Ahora se queja que hace tiempo aquella cosa que hacía tardaba tanto y hoy cuando lo ha hecho un par de veces la cosa ha sido más lenta de normal. Realmente puede estar pasando de todo, pero entre las causas comunes podemos encontrarnos de todo un poco: fragmentación en la misma tabla, estadísticas que no están al dia, carga fuera de lo habitual en el servidor en ese mismo momento, incremento del volumen en las tablas implicadas, cambios en la aplicación...
Casi siempre nos enteramos de que alguna query va lenta por alguna queja de usuario. Ahora se queja que hace tiempo aquella cosa que hacía tardaba tanto y hoy cuando lo ha hecho un par de veces la cosa ha sido más lenta de normal. Realmente puede estar pasando de todo, pero entre las causas comunes podemos encontrarnos de todo un poco: fragmentación en la misma tabla, estadísticas que no están al dia, carga fuera de lo habitual en el servidor en ese mismo momento, incremento del volumen en las tablas implicadas, cambios en la aplicación...
Focalizándonos solo en problemas relacionados exclusivamente con la base de datos y si el origen de la queja nos lleva a un informe, nuestro trabajo será mas fácil. Siempre partimos de una query concreta que seguramente podemos extraer rápidamente y lanzarla nosotros desde Management Studio para reproducir el caso.
Si gozamos de los permisos suficientes, en el propio Management Studio podemos ver el plan de ejecución estimado e incluso el real desde Management Studio de forma interactiva. También podemos hacer lo mismo con otras herramientas complementarias como SQLSentry Plan Explorer. Hasta aquí todo bien.
En cambio, si el problema de lentitud lo tenemos en una operativa de una aplicación como puede ser el ERP empresarial. Si no tenemos algún desarrollador o técnico a mano que nos pueda ayudar a extraer la consulta o alguna opción que nos permita hacer un seguimiento sobre el SQL que lanza, acabaremos usando Microsoft SQL Server Profiler para capturar esa actividad e investigar el problema.
SQL Server Profiler
Para el que no lo conozca o no lo sepa, SQL Server Profiler es "una interfaz enriquecida para crear y administrar seguimientos y analizar y reproducir resultados de seguimiento.". Vamos, que sirve para registrar la actividad sobre la base de datos e incluso si fuera necesario recrearla en otro entorno o condiciones.
Para poder ejecutar SQL Server Profiler debemos tener permiso ALTER TRACE sobre el servidor. Para ver planes de ejecución podemos necesitar también el permiso SHOWPLAN.
En nuestro caso, lo que queremos hacer es capturar el plan de ejecución para obtener el plan que nos proporciona realmente la base de datos y poder dar fe de ello. En algún caso me he encontrado que la misma consulta lanzada por una aplicación y Management Studio no estaban usando el mismo plan. La única manera de detectar el problema y dar fe de ello ha sido capturar la información real.
Al tema. Para ejecutar el seguimiento iniciaremos SQL Server Profiler. Podemos hacerlo desde el menú inicio>Programas o lanzarlo desde Management Studio si lo tenemos abierto. Herramientas > SQL Server Profiler. Una vez lo iniciamos lo primero es conectarse al servidor de base de datos implicado.

El siguiente paso consiste en configurar lo que será nuestro seguimiento eligiendo qué y como queremos capturar. Debemos seleccionar primero los tipos de evento queremos capturar y luego que detalles incluir sobre ellos. Para hacer correctamente la selección, primero debemos elegir una de las plantillas ya predefinidas que nos facilitan parte del trabajo y luego cambiarlas añadiendo y quitando eventos y/o columnas si hace falta a nuestro gusto.
Nosotros elegiremos por ejemplo la plantilla "Tunning" que contendrá la información mínima que podemos necesitar. A continuación hacemos clic en Mostrar Todos los eventos" y luego en "Mostrar todas las columnas". Buscaremos en la columna Events PERFORMANCE, lo desplegamos y activamos ShowPlan Text y/o ShowPlan Xml.
Elegimos la plantilla:

Añadimos lo que nos falte relativo al plan de ejecución:

Una vez hecho esto ya podemos iniciar la captura. Le damos al Play de la barra de botones que está debajo del menú y ya empezamos a registrar. Muestro un ejemplo de como nos queda todo con lo que hemos hecho hasta ahora, de un evento Showplan XML. La imagen infeiror nos muestra un ejemplo:

De las columnas que pueden aparecer para los diferentes tipos de evento, las básicas para un seguimiento pueden ser:
- EventClass: nos da el tipo de evento del registro seleccionado
- TextData: Texto plano. Por ejemplo la SQL ejecutada.
- Duration: Duración en mili segundos para Eventos del tipoo RPC o Stmt Completed.
- SPID: Identificador para la sesión de base de datos que provoca el evento.
- DatabaseName: Base de datos sobre la que ocurre el evento.
- TimeStart: La fecha/hora para ubicar el evento.
Una vez visto esto ya estamos listos para cualquier incidencia...
Otras cosillas a comentar sobre SQL Server Profiler:
-
Podemos ejecutar más de un seguimiento y les podemos poner nombre cambiando el Título, en las propiedades del seguimiento.
-
Cada dato innecesario suma. Si nos podemos ahorrar alguna columna mejor sacarla porque en un seguimiento de horas podemos tener cientos de miles de registros. Esto se traduce en espacio consumido innecesariamente.
-
Si hacemos el seguimiento en un entorno de producción donde conviven otras aplicaciones debemos aislar la información que nos puede dar Profiler añadiendo filtros. Para poder hacerlo, con el seguimiento detenido, debemos ir a la pestaña Selección de Eventos y hacer clic en Filtros de Columna. En este caso podemos intentar filtrar por aplicación si somos sus únicos usuarios o si sabemos alguna tabla implicada también podemos filtrar por el campo TextData. Existen diferentes combinaciones y se trata de encontrar la combinación de filtros más selectiva.

-
Para ir aprendiendo más sobre los eventos, si pasamos el ratón sobre su nombre en la columna Events, en el groupbox de la parte inferior aparece una breve descrición del mismo.
-
Si nos olvidamos el Profiler encendido y registrando actividad en el servidor, se pausa de forma "prudencial" cuando se coma todo el espacio en disco.
-
Podemos guardar la información de un seguimiento. Podemos hacerlo a fichero o podemos hacerlo en una tabla. Puede ser recomendable hacerlo en ambos pero para tratar los resultados puede ser más fácil la tabla.
-
Podemos crear plantillas a nuestro gusto. cuando ya tenemos la plantilla en ejecución podemos hacerlo desde el menú Archivo>Guardar como>Plantilla de seguimiento.
Que excelente articulo, me
Que excelente articulo, me encanto, me gustaria aprender mas para sacarle el jugo a la herramienta, si me recomendas algo de lectura te agradeceria, saludos.
- Log in to post comments
Estructura de la Dimensión Tiempo y script de carga para SQLServer
Estructura de la Dimensión Tiempo y script de carga para SQLServer il_masacratore 29 July, 2009 - 11:36En un data warehouse hay una serie de dimensiones comunes como son la geografica y la de tiempo. Para quién le pueda servir de ayuda dejo aquí el script de creación de la dimensión tiempo y un procedimiento para hacer la carga entre fechas de la tabla:
/*Base de datos destino*/
use PAnalisys
/*Creación de la tabla*/
create table DIM_TIEMPO
(
FechaSK int not null,
Fecha date not null,
Año smallint not null,
Trimestre smallint not null,
Mes smallint not null,
Semana smallint not null,
Dia smallint not null,
DiaSemana smallint not null,
NTrimestre char(7) not null,
NMes char(15) not null,
NMes3L char(3) not null,
NSemana char(10) not null,
NDia char(6) not null,
NDiaSemana char(10) not null
constraint PK_DIM_TIEMPO PRIMARY KEY CLUSTERED
(
Fecha asc
)
)
/*Script de carga*/
DECLARE @FechaDesde as smalldatetime, @FechaHasta as smalldatetime
DECLARE @FechaAAAAMMDD int
DECLARE @Año as smallint, @Trimestre char(2), @Mes smallint
DECLARE @Semana smallint, @Dia smallint, @DiaSemana smallint
DECLARE @NTrimestre char(7), @NMes char(15)
DECLARE @NMes3l char(3)
DECLARE @NSemana char(10), @NDia char(6), @NDiaSemana char(10)
--Set inicial por si no coincide con los del servidor
SET DATEFORMAT dmy
SET DATEFIRST 1
BEGIN TRANSACTION
--Borrar datos actuales, si fuese necesario
--TRUNCATE TABLE FROM DI_TIEMPO
--RAngo de fechas a generar: del 01/01/2006 al 31/12/Año actual+2
SELECT @FechaDesde = CAST('20060101' AS smalldatetime)
SELECT @FechaHasta = CAST(CAST(YEAR(GETDATE())+2 AS CHAR(4)) + '1231' AS smalldatetime)
WHILE (@FechaDesde <= @FechaHasta) BEGIN
SELECT @FechaAAAAMMDD = YEAR(@FechaDesde)*10000+
MONTH(@FechaDesde)*100+
DATEPART(dd, @FechaDesde)
SELECT @Año = DATEPART(yy, @FechaDesde)
SELECT @Trimestre = DATEPART(qq, @FechaDesde)
SELECT @Mes = DATEPART(m, @FechaDesde)
SELECT @Semana = DATEPART(wk, @FechaDesde)
SELECT @Dia = RIGHT('0' + DATEPART(dd, @FechaDesde),2)
SELECT @DiaSemana = DATEPART(DW, @FechaDesde)
SELECT @NMes = DATENAME(mm, @FechaDesde)
SELECT @NMes3l = LEFT(@NMes, 3)
SELECT @NTrimestre = 'T' + CAST(@Trimestre as CHAR(1)) + '/' + RIGHT(@Año, 2)
SELECT @NSemana = 'Sem ' +CAST(@Semana AS CHAR(2)) + '/' + RIGHT(RTRIM(CAST(@Año as CHAR(4))),2)
SELECT @NDia = CAST(@Dia as CHAR(2)) + ' ' + RTRIM(@NMes)
SELECT @NDiaSemana = DATENAME(dw, @FechaDesde)
INSERT INTO PAnalisys.dbo.DIM_TIEMPO
(
FechaSK,
Fecha,
Año,
Trimestre,
Mes,
Semana,
Dia,
DiaSemana,
NTrimestre,
NMes,
NMes3L,
NSemana,
NDia,
NDiaSemana
) VALUES
(
@FechaAAAAMMDD,
@FechaDesde,
@Año,
@Trimestre,
@Mes,
@Semana,
@Dia,
@DiaSemana,
@NTrimestre,
@NMes,
@NMes3l,
@NSemana,
@NDia,
@NDiaSemana
)
--Incremento del bucle
SELECT @FechaDesde = DATEADD(DAY, 1, @FechaDesde)
END
COMMIT TRANSACTION
A partir de aquí cada uno puede modificarla a su gusto añadiendo o quitando atributos
MySQL
Excelente aporte!
Hacia rato que tenía ganas de mostrar un ejemplo de la estructura de la dimensión tiempo y cómo realizar la carga de la misma, así que aproveché tu post para crear una entrada en mi blog, en donde básicamente traduje lo que tú has hecho en MySQL.
Gracias por compartir. Saludos!
- Log in to post comments
Lo mismo digo
Lo mismo digo bernabeu_dario!!
- Log in to post comments
Muchas gracias por tu
- Log in to post comments
Hola, estoy intentando hacer
- Log in to post comments
Una pregunta corta, he ido a
- Log in to post comments
Cuál es la sentencia que te
- Log in to post comments
ya me funcionó! El ejemplo de
- Log in to post comments
Bueno el ejemplo. Pero veo
Bueno el ejemplo. Pero veo que el primer dia de la semana es Monday.¿Que tengo que hacer para que el primer dia de la semana sea Sunday?
Saludos,
Javier Vega.
- Log in to post comments
Buenas Javier, cómo estás?
Buenas Javier, cómo estás?
En MySQL puedes hacer algo como:
dayofweek('2015-02-16')-1
Sino podrías emplear un CASE.
Saludos
- Log in to post comments
SQL Server: Cómo saber cuándo se han borrado datos y recuperarlos usando el registro de transacciones
SQL Server: Cómo saber cuándo se han borrado datos y recuperarlos usando el registro de transacciones il_masacratore 5 March, 2014 - 17:45En el post anterior explicaba como examinar el registro de transacciones de una base de datos para ver poder ver el detalle de los cambios realizados en la misma, ya sean consultas DML como DDL. En este post se explica como usar la misma herramienta en otro caso práctico para poder detectar en que momento se han borrado unos datos y como recuperarlos haciendo una restauración point-in_time de la base de datos para poder copiarlos de nuevo.
Recuperando lo visto en este post, en MS SQL Server podemos consultar el contenido del log de transacciones usando la función no documentada fn_dblog. Esta opción, podemos ejecutarla con los valores por defecto (NULL, NULL) para que nos devuelva TODO el contenido del log o podemos filtrar por LSN (LSN inicial, LSN final). Eso sí, como requisito, es imprescindible que la base de datos esté usando la opción de seguimiento de cambios "completa" (full recovery model):
SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Transaction SID], [SPID], [Begin Time] FROM fn_dblog(null,null)
Antes de empezar, para el ejemplo crearemos primero una base de datos de prueba:
-- Script creación de la base de datos
USE [master];
GO
CREATE DATABASE [Testdb];
GO
-- Creación de una tabla
USE [Testdb];
GO
CREATE TABLE [Articulos] (
[IdArticulo] INT IDENTITY,
[FechaCreacion] DATETIME DEFAULT GETDATE (),
[Codigo] CHAR (5) NOT NULL,
[Descripcion] CHAR(20) NULL);
-- Carga de datos
INSERT INTO [Articulos] (Codigo, Descripcion) VALUES ('00S00','Scott Spark MTB')
GO
INSERT INTO [Articulos] (Codigo, Descripcion) VALUES ('00G10','Scott Genius 10 MTB')
GO
INSERT INTO [Articulos] (Codigo, Descripcion) VALUES ('00G20','Scott Genius 20 MTB')
GO
INSERT INTO [Articulos] (Codigo, Descripcion) VALUES ('00G30','Scott Genius 30 MTB')
GO
-- A continuació haremos un DELETE y un nuevo insert.
USE [Testdb];
GO
DELETE FROM [Articulos]
GO
INSERT INTO [Articulos] (Codigo, Descripcion) VALUES ('00G40','Scott Genius 40MTB')
GOEl caso práctico es que alguien ha borrado el contenido de una tabla y no sabemos cuando lo ha hecho. Por suerte, sabemos que tenemos activado el seguimiento completo para la base de datos y una copia de seguridad completa de la madrugada anterior. Para poder recuperar los datos que hemos perdido, investigaremos cuando se han borrado los datos en el registro de transacciones, recuperaremos el último LSN, haremos un backup del registro de transacciones en su estado actual y haremos una restauración "point-in-time" en otra base de datos para conseguir los datos como estaban justo antes de ser eliminados. Pasos a seguir:
- Buscar quién y cuando han borrado los datos: Primero ejecutamos fn_dblog para consultar en todo el registro para buscar operaciones del tipo LOP_DELETE_ROWS. También podríamos filtrar por AllocUnitName y buscar el nombre completo de la tabla (dbo.Articulos).
USE [Testdb]; GO SELECT [Current LSN], [Transaction ID], [Operation], [Context], [AllocUnitName] FROM fn_dblog(NULL, NULL) WHERE Operation = 'LOP_DELETE_ROWS'

Mirando la imagen vemos el Id de transacción que ha ejecutado el DELETE. Cuidado porque aunque un bloque SQL con más de una SQL esté en una misma transacción, el LSN es totalmente independiente en cada una de ellas. Por ello, ahora buscaremos el inicio de la transacción (LOP_BEGIN_XACT) para poder coger su LSN y ver de paso cuando se ha eliminado:
SELECT [Current LSN], [Transaction ID], [Operation], [Context], [AllocUnitName] FROM fn_dblog(NULL, NULL) WHERE [Transaction ID] = '0000:000002ee' AND [Operation] = 'LOP_BEGIN_XACT'

- Calcular el parámetro para indicar el momento al que restaurar. Ahora que ya tenemos el momento del delete y su LSN, ya podemos hacer la restauración de la copia de la base de datos. Para ello usaremos la opción STOPBEFOREMARK del comando RESTORE. La única pega es que debemos convertir el LSN a formato decimal. Eso lo hacemos partiendo en tres el LSN, convirtiendo cada miembro a decimal y formateándolo:
- El primer miembro (00000021) se pasa a decimal y se formatea sin ceros a la izquierda, quedando como 33.
- El segundo miembro (0000006c) se pasa a decimal y se formatea con 0 a la izquierda hasta que tenga longitud 10, quedando como 0000000108.
- El tercer miembro (0003) se pasa a decimal y se formatea con 0 a la izquierda hasta que tenga longitud 5, quedando como 00003.
- Unimos las tres cadenas, nos queda 33000000010800003.
- Hacer el backup del log de transacciones actual. Solo necesitamos hacer el backup del log transacciones si no se ha hecho ninguno anterior al momento presente y posterior al DELETE.

- Restaurar al momento clave en otra base de datos. Restauramos primero el Backup total con NORECOVERY y luego el del log hasta el momento anterior al DELETE (especificando el LSN en formato decimal):
--Restore del backup completo. RESTORE DATABASE TestDb_Copia FROM DISK = 'C:\TestDb_Copia_full.bak' WITH MOVE 'TestDb' TO 'C:\TestDb.mdf', MOVE 'TestDb_log' TO 'C:\TestDb_log.ldf', REPLACE, NORECOVERY; GO --Restore del log de transacciones. RESTORE LOG TestDb_Copia FROM DISK = N'C:\TestDb.trn' WITH STOPBEFOREMARK = 'lsn:33000000010800003'
- Finalmente comprobar y copiar lo que nos haga falta. Comprobamos que datos tiene la restauración de la base de datos temporal y copiamos los datos que nos haga falta de la temporal a la original.
Para poder aplicar todo este mismo proceso para cuando alguien ha BORRADO UNA TABLA lo que tenemos que hacer es buscar el LSN filtrando [Transaction Name]='DROPOBJ' en lugar de Operation = 'LOP_DELETE_ROWS'. El resto es lo mismo (backup log, restore backup, restore log stopbeforemark).
En conclusión...
... esta bien saber que el log de transacciones está ahí por algo más. Como en el otro post, saber que podemos explorarlo y buscar qué pasó en momentos clave de nuestra base de datos o cuando paso algo concreto. Esta bien poder recuperar la tabla pero también tenemos que pensar en cada caso si algo así nos vale porque puede ser que necesitemos hacer "matching" de los datos. En el caso de tablas del ERP pueden intervenir secuencias, tablas relacionadas etc etc. Puede que recuperar la tabla antes de ser borrada no valga para volcarla directamente pero al menos sea útil para consulta y volver a generar los datos a mano o desde el ERP. Igualmente está bien saber que tenemos esta posibilidad y probarlo en un entorno de test para saber como funciona el día que nos haga falta.
Libros de SQL Server
¿Quieres profundizar más en Transact-SQL o en administración de bases de datos SQL? Puedes hacerlo consultando alguno de estos libros de SQL Server
Mejor revisa la lista completa de los últimos libros de SQL Server publicados en Amazon según lo que te interese aprender, pero estos son los que a mi me parecen más interesantes, teniendo en cuenta precio y temática:
- eBooks de SQL Server gratuítos para la versión Kindle, o muy baratos (menos de 4€):
- Libros recomendados de SQL Server
Por favor, podrían compartir
Por favor, podrían compartir todos los links referentes a este tema
- Log in to post comments
Buen aporte. Muchas gracias
Buen aporte. Muchas gracias por compartir.
- Log in to post comments
SQL Server: Vistas indizadas y el porqué de usarlas para cargas de dwh
SQL Server: Vistas indizadas y el porqué de usarlas para cargas de dwh il_masacratore 11 February, 2014 - 12:17 Las vistas pueden ser una herramienta perfecta para simplificar consultas que unen distintas tablas, permiten abstenerse de la estructura origen y simplificar si hace falta la estructura saliente. También nos pueden servir como un mecanismo de seguridad que limitará el acceso de los usuarios a datos no deseados de las tablas base. Con MS SQL Server, Microsoft ha ido un paso más allá y permite crear un nuevo tipo de vistas llamado vista indizada.
Las vistas pueden ser una herramienta perfecta para simplificar consultas que unen distintas tablas, permiten abstenerse de la estructura origen y simplificar si hace falta la estructura saliente. También nos pueden servir como un mecanismo de seguridad que limitará el acceso de los usuarios a datos no deseados de las tablas base. Con MS SQL Server, Microsoft ha ido un paso más allá y permite crear un nuevo tipo de vistas llamado vista indizada.
Que son las vistas indizadas?
Las vistas de toda la vida, las podemos ver como si fueran una tabla pero realmente no existe. Una vista estandar no está almacenada en la base de datos, en lugar de eso los datos que se devuelven se recuperan de forma dinámica en el momento de la petición (la consulta SQL sobre la vista). Una vista indizada se diferencia de una normal basicamente en que sobre la primera creamos un índice (el primero clusterizado). En el momento en que lo hacemos estamos persistiendo en la base de datos una referencia que abre la veda a posibles optimizaciones que no se pueden hacer con una vista simple. También es cierto que si nos hace falta y realmente nos aporta algo también es posible es crear más de un indice ( a partir del segundo ya no pueden ser clústerizados, crear uno clústerizado es obligado).
Una de los beneficios que también da la vista indizada es que aporta una nueva perspectiva en el momento del cálculo para el plan de ejecución de una SELECT sobre las tablas que implica. El optimizador de consultas puede seleccionar la vista si determina que ésta puede sustituirse por parte o por toda la consulta del plan de consultas si es de un coste menor. En el segundo caso, la vista indizada se utiliza en lugar de las tablas subyacentes y sus índices. No es necesario hacer referencia a la vista en la consulta para que el optimizador de consultas la utilice durante la ejecución. Esto incluso permite que las aplicaciones existentes se beneficien de las vistas indizadas recién creadas sin cambiar directamente código en dichas aplicaciones.
Donde usarlas y como crearlas
Las vistas indizadas aportan un beneficio aunque también un coste. Puede tener el mismo “defecto” que puede producir la indexación masiva de una tabla transaccional con inserciones/modificaciones masivas. Debemos evaluar siempre el beneficio en base al coste que suponga. Realmente con las vistas indizadas (clusterizada o no) seguro que notaremos una mejora si las usamos en datawarehouses, data marts, bases de datos OLAP, en procesos de minería de datos y similares. En estos escenarios son candidatas las consultas gigantes sobre diferentes tablas, con particiones verticales u horizontales, agregaciones y sin pensarlo demasiado, las particiones de tablas de hechos. Un ejemplo que se me ocurre es el del diagrama en estrella del datamarts de ventas donde podemos tener cabeceras de venta en una tabla y el detalle en otra. Seria normal en casos como estos haber creado particiones en el grupo de medidas y hacer la separación por las fechas de venta que estan en la cabecera.
Una de los requisitos para poder indizar una vista es que tenemos que crear la vista con la opción WITH SCHEMABINDING. Esta opción tiene su lado positivo, si el propietario de cualquiera de las tablas incluidas en la select intenta hacer un cambio en la estructura no podrá. Esto es fantástico porque nos protege de cualquier cambio a traición de las tablas.
Pongo aquí un ejemplo básico. Creamos primero la tabla y la vista con la selección de los campos que nos interesan.
CREATE TABLE Articulos ( IdArticulo INT PRIMARY KEY, Descripcion VARCHAR(20), Stock INT) GO
CREATE VIEW ArticulosView WITH SCHEMABINDING AS SELECT IdArticulo, Stock FROM dbo.Articulos WHERE Stock > 0 GO CREATE UNIQUE CLUSTERED INDEX idx_ArticulosView ON ArticulosView(Stock)
Una vez hemos creado el índice, los datos de la vista están almacenados en la base de datos como cualquier otro índice clusterizado sobre una tabla. Cualquier consulta sobre la vista ya puede usar el índice para el cálculo del plan de ejecución. Consultas que tengan un predicado similar ya podran beneficiarse del indice por rango. Por ejemplo:
SELECT IdArticulo, Stock FROM Articulos WHERE Stock > 0
Incluso en este caso y aunque no hagamos la consulta sobre la vista, el optimizador de consultas puede tener en cuenta el indice clusterizado de la vista para obtener los datos con un mejor rendimiento que si lo hiciera con los indices de la tabla base.
Otro ejemplo con más sentido donde se usa el indice clusterizado de la vista en lugar del de la tabla. Nos imaginamos que queremos hacer una partición vertical de una tabla con mucho campos (wide_tbl) que podría ser la tabla de cabeceras o lineas de venta de nuestro erp desde el que sacamos directamente la información que nos interesa de la parte de ventas:
– Creación de la tabla base CREATE TABLE wide_tbl( a int PRIMARY KEY, b int, c int, d int, e int, f int, g int, h int, i int, j int, k int, l int, m int, n int, o int, p int, q int, r int,s int,t int, u int, v int, w int, z int) GO – Vista sobre la tabla base donde hacemos partición vertical (nos quedamos solo con lo que nos interesa) CREATE VIEW v_abc WITH SCHEMABINDING AS SELECT a, b, c FROM dbo.wide_tbl WHERE a BETWEEN 0 AND 1000 GO CREATE UNIQUE CLUSTERED INDEX i_abc ON v_abc(a) GO
La select es la siguiente. Si miramos el plan de ejecución estimado ya vemos que está usando efectivamente el índice de la vista aunque seleccionemos datos de la tabla.
SELECT b, count_big(*), SUM(c) FROM wide_tbl WHERE a BETWEEN 0 AND 1000 GROUP BY b

A tener en cuenta cuando creamos indices sobre vistas
Ademas de incluirse la clausula WITH SCHEMABINDING que nos prohibe la modificación de la estructura o eliminación de las tablas bases incluidas en la vista, debemos pensar o tener en cuenta que:
- La vista debe ser determinista. Es decir, siempre debe devolver el mismo resultado para el mismo input. No se pueden incluir por ejemplo funciones como GETDATE que devuelven valores distintos para diferentes llamadas con el mismo argumento.
- WITH SCHEMABINDING, con sus cosas buenas y sus cosas malas.
- En la definición de la vista se debe hacer referencia a nombre completo la tabla (schema.tabla). Lo mismo con las funciones de usuario.
- Espacio en disco. Debemos recordar que los indices que creemos ocuparan el mismo espacio en disco que cualquier otro sobre una tabla.
- A diferencia de Oracle, donde un equivalente podría ser una vista materializada, no se necesita ningún permiso concreto para este tipo de vista. Basta con tener permisos CREATE VIEW y ALTER en el schema donde se crea la vista.
En Conclusión...
... las vistas indizadas pueden ofrecer grandes mejoras de rendimiento pero siempre en los entornos adecuados. Debemos evitarlas en entornos transaccionales con mucha carga transaccional y dejarlas más para otros entornos más de consulta/actualización como puede ser las tablas sobres las que procesamos nuestros cubos del datawarehouse. También es cierto que una alternativa funcional a una vista indizada es un COVER INDEX que incluya las columnas que nos interesen.
Gracias, desde Chile!
Gracias, desde Chile!
- Log in to post comments
SSAS: Microsoft SQL Server Analysis Services
SSAS: Microsoft SQL Server Analysis Services Dataprix 23 May, 2014 - 19:35SSAS: Como monitorizar el procesamiento de cubos en Analysis Services
SSAS: Como monitorizar el procesamiento de cubos en Analysis Services il_masacratore 17 February, 2014 - 18:23Existen algunos tips que permiten mejorar el rendimiento y reducir el tiempo de procesado en nuestras bases de datos de Analysis Services. Hay unas cuantas páginas dedicadas a ello y resúmenes por ahí que marcan unas líneas a seguir (y otras que no!). En este post nombro un ejemplo y de que manera podemos medir esa posible mejora de forma objetiva basándonos en el uso de los contadores de rendimiento del sistema y de Sql Server Profiler.
Ejemplo de mejora: Evitar tablas de hechos con demasiados campos.
Imaginaros la tabla de hechos con las cabeceras de venta. Si esta tabla tiene 100 campos y solo necesitamos 10, el número de registros contenidos en cada página de 8k de datos será mucho menor que si solo se almacenaran los campos sensibles. ¿Como podemos mejorar este aspecto?
- Partición vertical de la tabla en dos diferentes. Si tenemos la posibilidad estaría bien poder hacer una partición vertical y aislar esos 10 campos que necesitamos para dejar el resto en una tabla adicional. Sin tener en cuenta el tamaño de los campos, podríamos reducir el número de páginas de datos a recorrer en un 10%. Aunque esto es lo ideal, no siempre es posible.
- Tabla derivada. En la linea de lo anterior, podríamos mantener una tabla derivada sobre la que procesar los hechos.
- Crear una Vista indizada. Con la vista hacemos la partición pero restringimos de alguna manera la tabla original e incluso podríamos ralentizar un poco la inserción de datos si es una tabla transaccional muy concurrida. No es mala opción pero hay que medir las ventajas y los inconvenientes.
Medir el procesamiento con los contadores de rendimiento de Windows Server
La idea es trabajar sobre una linea base, una foto inicial de como está todo y después de cada cambio realizar otra monitorización para comparar las diferencias y poder medir bien que hemos cambiado y donde está la mejora o el empeoramiento. Al igual que con el motor de base de datos de Microsoft SQL Server, para monitorizar el procesado de cubos podemos usar el monitor de rendimiento del sistema para consultar los contadores de rendimiento propios de Analysis Services. En este otro post explico como se hace para la base de datos. Para la parte de Analysis Services, algunos contadores que podemos usar los siguientes:
- MSOLAP: Processing
Rows read/sec:
Registros que se leen por segundo en el procesado.
- MSOLAP: Proc Aggregations
Temp File Bytes Writes/sec: Ratio por segundo de escrituras en los ficheros temporales. Esto ocurre cuando se excede el límite de memoria. Cuanto más tienda a cero mejor.
Rows created/Sec : Ratio por segundo de creación por segundo. Cuanto más elevado mejor.
Current Partitions : Particiones procesadas actualmente. No sirve más que para controlar que estamos procesando y que los contadores no estén "contaminados" (por ejemplo si es mayor que 1 y no queremos procesado paralelo).
- MSOLAP: Threads
Processing pool idle threads : Puede variar según la versión, en la 2012 se separan los hilos de procesado de los de E/S. Sirve para monitorizar el paralelismo de tareas.
Processing pool job queue length : Puede variar según la versión, en la 2012 se separan los hilos de procesado de los de E/S. Sirve para monitorizar el paralelismo de tareas.
Processing pool busy threads : Puede variar según la versión, en la 2012 se separan los hilos de procesado de los de E/S. Sirve para monitorizar el paralelismo de tareas.
- MSSQL: Memory Manager
Total Server Memory : Total de memoria que está usando actualmente el motor relacional de la base de datos.
Target Server Memory : Total de memoria CONFIGURADO que debería usar el motor de base datos. Si el contador anterior es inferior a este hay algún problema y alguien se está comiendo memoria que teóricamente hemos asignado a la base de datos.
- Logical Disk
Avg. Disk sec/Transfer – All Instances - Processor:
% Processor Time – Total : % CPU consumida actualmente.
- System:
Context Switches / sec : Cambios de tarea en la cola de la cpu. Un valor bajo que tiende a 0 puede significar que algo está monopolizando el 100% de la cpu.
Controlar el uso del motor de base de datos relacional
Como complemento a lo que comento en el apartado anterior, también deberíamos analizar como van las consultas SQL que tiramos sobre la base de datos relacional. Podemos complementar lo anterior con la captura de actividad desde Sql Server Profiler. Como plantilla podemos usar la de Tunning y le añadimos estos dos eventos:
- Performance/Showplan XML Statistics Profile
- TSQL/SQL:BatchCompleted
De ellos necesitamos las columnas TextData, Reads, DatabaseName, SPID y Duration. Con ellos podemos detectar cuales son las consultas que más se demoran, podemos ver su plan de ejecución y mirar los índices que pueden mejorar los tiempos en la recuperación de los datos.
En cuanto a la captura con SQL Server Profiler, es bueno saber que podemos filtrar eventos para solo mostrar lo imprescindible. En este otro post explico como funciona la captura y como filtrar para afinar la captura.
En conclusión...
... creo que conocer la manera de monitorizar el procesado de nuestros cubos nos permite ver que podemos mejorar, ya sea algo del diseño o maneras de hacer las cosas. Como comento arriba para poder empezar deberíamos comenzar con una captura inicial y tras cada posible mejora deberíamos volver a monitorizar para cuantificar la mejora. Pienso que la mayoría de contadores pueden ser evolutivos (los comparamos con anteriores) y creo que no hay un rango definido. Simplemente sabiendo lo que miden y con un poco de lógica sabremos cuando va a mejor o a peor (el contador). El único problema que podemos tener en todo esto es que podamos hacerlo de forma proactiva, el lugar de forma reactiva cuando se nos solape con otros procesos... y entonces tengamos un problema.
SSAS: Como quitarle al usuario administrador de sistema el acceso como administrador a nuestra instancia de analysis services
SSAS: Como quitarle al usuario administrador de sistema el acceso como administrador a nuestra instancia de analysis services il_masacratore 4 October, 2010 - 11:23
La seguridad en Analysis Services está basada en la seguridad propia de Windows. Los usuarios se autentican usando sus cuentas de Windows locales (del servidor) o de dominio y pueden tener derechos segun los roles a los que pertenecen. ¿Que quiere decir esto? Que por decreto y si no hacemos cambios en la configuración de nuestra instancia de SSAS los usuarios que pertenecen al rol de Administradores del SO pueden entrar como Administradores también en la instancia. Para cambiar este comportamiento y limitar la administración de SSAS a los usuarios que hemos marcado como tales debemos cambiar el valor de la propiedad Security\BuiltinAdminsAreServerAdmins y ponerlo a false. Pero cuidado al hacer esto, no vayamos a quedarnos sin administradores, previamente debemos asegurarnos de que tenemos otra cuenta en la lista de administradores de SSAS.
Para acceder a las propiedades de la instancia nos conectamos como administradores y hacemos click con el boton derecho en el nombre de la misma. En general la vemos y cambiamos allí el valor.

Para ver la lista de administradores actuales de la instancia que han sido añadidos explicitamente en el mismo sitio, pero en el apartado seguridad podemos consultarlo.

Tener a los administradores de sistema ahí metidos por defecto en segun que entornos puede suponer un agujero de seguridad. A mi particularmente no me gusta...
Yo creo que el agujero de
Yo creo que el agujero de seguridad suele estar más bien en la 'alegría' con la que se utilizan los usuarios administradores de Windows, si el usuario administrador se utiliza correctamente lo normal sería que también tuviera acceso para administrar SSAS, no?
- Log in to post comments
SSAS: Permitir el acceso de usuarios a los cubos
SSAS: Permitir el acceso de usuarios a los cubos il_masacratore 25 November, 2009 - 00:24Desde el punto de vista del desarrollador de bi es muy satisfactorio finalizar el diseño y la implementación de un cubo, comprobar datos y deployarlo y que todo funcione bien, al menos para tu usuario. El problema te lo puedes encontrar al desconocer como permitir el acceso a los usuarios finales a tus cubos implentados en Sql Server 2008 Analisys Services.
Adjunto una pequeña guía para obtener la satisfacción plena
permitiendo el acceso al cubo:
Para conceder permisos de lectura, procesamiento a un cubo de forma parcial, por dimensiones o medidas debemos crear una nueva Funcion dentro de nuestra base de datos ssas. Cita de los libros en pantalla de microsoft:
Las funciones se usan en Microsoft SQL Server Analysis Services para administrar la seguridad de los objetos y datos de Analysis Services.En términos simples, una función asocia los identificadores de seguridad (SID) de usuarios y grupos de Microsoft Windows que tienen derechos y permisos de acceso específicos a los objetos administrados por una instancia de Analysis Services. En Analysis Services se incluyen dos tipos de funciones:
- La función del servidor, que es una función fija que proporciona acceso de administrador a una instancia de Analysis Services.
- Las funciones de base de datos, que son funciones definidas por los administradores para controlar el acceso a los objetos y datos de los usuarios que no son administradores.
Vista la definción adjunto la localización dentro de la jerarquía del Management Studio:

Para añadir una nueva hacemos botón derecho sobre la carpeta funciones, pulsamos nueva función y un formulario como el de la siguiente imagen. Como mínimo debemos cumplimentar:
- General. Nombre de la función y descripción. Debemos seleccionar también los permisos sobre los permisos de base de datos (mínimo leer).
- Pertenencia. Añadiremos aquí los usarios de dominios de confianza para los que queremos habilitar estos permisos.
- Orígenes de datos. Permiso de acceso al origen de datos del cubo.
- Cubos. Tipos de permiso sobre los diferentes cubos.
Los cuatro pasos anteriores son lo mínimo y cubren los permisos a nivel general, pero puede que necesitemos algo más. Conviene saber que con los apartados de Datos de Celda, Dimesiones y Datos de dimensiones podemos ocultar información sensible para ciertos usuarios.
Una vez añadida la función, editados permisos y mapeado usuarios ya nos podemos ir a tomar el café...
Cuidado!!! Esto solo vale
Cuidado!!!
Esto solo vale para cubos ya implementados y que no van a ser reprocesados desde otro sitio(management studio). Para los cubos que estan en desarrollo o que aún se procesan desde el bi development studio es mejor definirlo dentro del proyecto, ya que si no es así desapareceran las creadas desde management studio
- Log in to post comments
SSIS: Microsoft SQL Server Integration Services
SSIS: Microsoft SQL Server Integration Services Dataprix 23 May, 2014 - 19:39SSIS: Problemas para acceder a Oracle 10g desde entorno de 64 bits mediante Oledb
SSIS: Problemas para acceder a Oracle 10g desde entorno de 64 bits mediante Oledb il_masacratore 19 November, 2009 - 09:49Si estamos intendo crear una tarea de flujo de datos que acceda a Oracle usando versiones de cliente igual o inferior a la 10g en entornos de 64bits nos podemos encontrar que al añadir las conexiones aparace un mensaje como el siguiente:
"Test connection failed because of an error in initializing provider. ORA-06413: Connection not open"
La causa del problema reside en que las herramientos de cliente (management studio) de sqlserver se instalan por defecto en la carpeta de archivos de programa con "(x86)" y la mayoria de componentes de management studio estan compilado para 32 bits. A esto falta sumarle un bug de oracle con el tratamiento de esta ruta con parentesis y ya tenemos algo que no funciona...
Soluciones o workarounds para este problema hay varios, que van desde usar directamente el cliente de oracle 11g hasta copiar/pegar los ficheros de la instalación y modificar las claves de registro relativas a SSIS y las rutas de DTExec.exe (ejecutable para paquetes ssis). También debemos cambiar la plataforma en las propiedades del proyecto por una de 32 bits y tener instalada la versión de cliente correspondiente. Aquí encontrareis algunas propuestas.
Por favor, antes de decidir que hacer hay que pensarselo dos veces y analizar si el problema lo podemos esquivar por la parte de la plataforma; si disponemos otra instalación de sqlserveradicional de 32 bits donde poder deployar nuestros paquetes ssis nos ahorraremos dolores de cabeza y perder el tiempo haciendo estas modificaciones. Recuerdo haber leído también que existen parches para Oracle que lo solución, o se puede optar directamente por instalar el cliente de la 11g etc...
Buena suerte
SSIS: Solución a dos errores sin motivo aparente cuando insertamos datos en MySql
SSIS: Soluzione a due errori per nessun motivo apparente, quando inserisce i dati in MySql il_masacratore 13 September, 2010 - 10:44
Per qualunque motivo si può avere per sviluppare un pacchetto di Microsoft Integration Services che spostare i dati da qualsiasi fonte a una tabella che si trova in un database MySQL.
La prima intenzione lo farà tramite un provider ADO.NET destinazione e MySQL per la connessione. Se facciamo bene di inserire i dati direttamente, creando la destinazione, selezionare la connessione, quindi selezionare la tabella appare un errore come il seguente tutto verificare con l'anteprima o cercare di fare le assegnazioni.


Questo errore è dovuto alla modalità di compatibilità di ANSI SQL database mysql dove si cerca di caricare i dati. Per risolvere questo problema bisogna connettersi al server MySQL e cambiare la compatibilità del database SQL ANSI *:
|
TOCA:~# mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 77 Server version: 5.0.51a-24+lenny3-log (Debian)
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql> select @@global.sql_mode; +-------------------+ | @@global.sql_mode | +-------------------+ | | +-------------------+ 1 row in set (0.00 sec)
mysql> set global sql_mode='ANSI'; Query OK, 0 rows affected (0.00 sec)
mysql> select @@global.sql_mode; +-------------------------------------------------------------+ | @@global.sql_mode | +-------------------------------------------------------------+ | REAL_AS_FLOAT,PIPES_AS_CONCAT,ANSI_QUOTES,IGNORE_SPACE,ANSI | +-------------------------------------------------------------+ 1 row in set (0.00 sec)
mysql> exit |
Se riusciamo a ripetere il test ed ottenere una anteprima del tavolo o modificare il mapping tra le colonne, ma troviamo un altro errore quando si esegue il pacchetto:
[ADO NET destinazione [843]] Errore: eccezione quando si inseriscono i dati. Il provider ha restituito messaggio è: Unknown column 'P1' a 'Elenco campi' "
Il conducente ha un problema e non lasciare che lavoriamo bene con parametri (che è come hanno costruito gli inserimenti di record del destination), so che abbiamo a che fare un'altra soluzione per risolvere questo problem working con ADO.NET destinazione su arrival but con un sorgente ODBC nella connessione. Questa accoppiata con il tema della modifica della destinazione sql_mode MySQL ci permettono di caricare correttamente.

* Si prega di notare che il sostegno che possiamo cambiare il mondo e per la sessione o solo livello (con cui si dovrebbe aggiungere un esecuzione dei comandi in prima istanza per modificare il valore di @ @ SESSION.sql_mode). Maggiori informazioni qui.
SSRS: Microsoft SQL Server Reporting Services
SSRS: Microsoft SQL Server Reporting Services Dataprix 23 May, 2014 - 19:42SSRS: Como usar una consulta SQL Server openquery parametrizada
SSRS: Como usar una consulta SQL Server openquery parametrizada il_masacratore 2 December, 2013 - 12:53Parametrizar una consulta en la que usamos un servidor vinculado de SQL Server mediante openquery puede ser necesario en diferentes escenarios. Por ejemplo podemos necesitarlo para cargar una tabla intermedia con los datos de venta que sacamos de MySql a través de un servidor vinculado en SQLServer. También en un informe de SQL Server Reporting Services.
[[ad]] Vamos con un ejemplo donde consultamos una tabla de Mysql directamente:
SELECT * FROM Ventas.CABECERAS WHERE date_format(FECHA, '%Y-%m-%d') >= '2012-12-01'
Esta misma consulta, lanzada desde SQL Server usando openquery y un servidor vinculado llamado 'MY' para acceder sería:
SELECT * FROM openquery(MY, 'SELECT * FROM Ventas.CABECERAS WHERE date_format(FECHA, ''%Y-%m-%d'') >= '''2012-12-01''')
** En otro este post explico como crear el servidor vinculado

[[ad]] Si quisiéramos parametrizarla, se nos ocurre primero añadirle un parámetro fecha, o segundo, construir la cadena de texto con las fechas usando variables tipo varchar (usare esta segunda forma para luego concatenar el resultado con el de otra query). Pero nada de esto funciona, ni aun pasando la consulta que pasa por openquery por variable:
DECLARE @fecha varchar; SET @fecha = '2012-12-01' SELECT * FROM openquery(MY, 'SELECT * FROM Ventas.CABECERAS WHERE date_format(FECHA, ''%Y-%m-%d'') >= ''' + @fecha + '''') GO
DECLARE @fecha VARCHAR DECLARE @consulta VARCHAR(8000) SET @fecha = '2012-12-01' SET @consulta = 'SELECT * FROM Ventas.CABECERAS WHERE date_format(FECHA, ''%Y-%m-%d'') >= ''' + @fecha + '''' SELECT * FROM openquery(MY, @consulta) GO
La única manera de que funcione y lo interprete es meter la consulta y el openquery en la variable @sql para llamarlo con EXEC como si fuera un procedimiento almacenado:
DECLARE @fecha VARCHAR DECLARE @consulta VARCHAR(8000) SET @fecha = '2012-12-01' SET @consulta = 'SELECT * FROM openquery(MY, ''SELECT * FROM Ventas.CABECERAS WHERE date_format(FECHA, ''%Y-%m-%d'') >= ''' + @fecha + ''')' exec (@consulta) GO
Un ejemplo como este puede suponer un problema si queremos llamarlo desde un informe de SSRS. Report builder no nos dejara declarar variables que realmente no son parámetros a fijar del dataset. Para poder usarlo como origen de datos de un informe lo que debemos hacer es meterlo dentro de un procedimiento almacenado para evitar el problema con la variable @sql (que es de uso interno) y permitir usar la fecha como filtro:
/* --- Creación del procedure en Sqlserver --- */ CREATE PROCEDURE [dbo].[procVentasMy] @fecha datetime AS SET NOCOUNT ON BEGIN DECLARE @consulta VARCHAR(8000) SET @consulta = 'SELECT * FROM openquery(MY, ''SELECT * FROM Ventas.CABECERAS WHERE date_format(FECHA, ''%Y-%m-%d'') >= ''' + @fecha + ''')' exec (@consulta) END
/* --- Uso del mismo en Report Builder ---*/ EXEC [dbo].[procVentasMy] @fechaMinima
[[ad]] Este ejemplo va relacionado con este otro post sobre SQL Server donde se explica cómo concatenar en SQL Server resultados de dos origenes de datos distintos mediante openquery. En ese caso también puede ser necesario parametrizar la consulta y podemos hacerlo exactamente igual.
SSRS: Consejos y how-to sobre Report builder
SSRS: Consejos y how-to sobre Report builder il_masacratore 4 November, 2013 - 18:37Antes de maravillarme con lo bonito que pueda ser Power View y Sql Server 2014 dejo unas cosillas útiles que se deben saber sobre Report Builder 2.0. La mayoria son para el diseño de informes y otras son sobre el funcionamiento en el dia a dia y alguna cosa que nos podemos encontrar y en la que no sabemos por donde empezar.
Ahí van estos 10 tips o recomendaciones sobre Microsoft Report Builder:
Mantener todos los elementos en la misma página.
Para mantener todos los elementos en la misma página en el momento de la presentación en html del informe basta con añadir todos los elementos dentro de un rectángulo y en él establecer la propiedad KeepTogether a True.
Formato condicional de una propiedad
Para cambiar el formato de una celda, ya sea el color de fondo, color de la fuente etc... basta con editar la fórmula de la casilla y normalmente establecer un switch en base a un valor o una condición determinada. Por ejemplo, para cambiar el color de la fuente a rojo o verde según el valor de un porcentaje (sea negativo o positivo) ponemos en Color una fórmula como la siguiente (en base a un campo Margen).

Navegación entre reportes
Es posible que queramos en alguno de nuestros reportes, permitir la posibilidad de navegar entre informes para ver información más detallada y no saturar la vista poniendo todos los datos en una megatabla etc etc. Esto lo podemos hacer insertando un Cuadro de Texto con el título que queramos y luego estableciendo la Acción al pulsar el botón sobre el. Es útil saber que podemos definir el informe que abriremos y los parámetros que queramos pasarle.
No está de más saber que ese nuevo informe se abre en el mismo visor de informes y oculta el informe actual. También, cuando abrimos el nuevo, si pulsamos Atrás volvemos al informe donde hemos clicado sin hacer la carga de información de nuevo.
Yo particularmente suelo marcar a nivel visual estos elementos tipo Enlace subrayando la fuente y cambiándole el color.

Parámetros tipo Fecha en un informe y como transformarlos a MDX
Si construimos un informe sobre nuestro cubo, y uno de los parámetros visibles que puede cambiar el usuario es de tipo fecha, nos encontraremos que el diseñador nos construye por defecto un desplegable del tipo lista tabulada.

Si queremos facilitarle la vida al usuario hemos de modificar el tipo de datos del parámetro a Fecha y Hora para que nos aparezca el calendario en lugar de la lista tabulada, además de no permitir más de un valor ni valores en blanco. Debemos quitar también los valores disponibles (que se sacan de un dataset auto generado en el momento de marcar el parámetro como visible y que podemos eliminar) y si hace falta los valores predeterminados (en todo caso podemos setear a la fecha de hoy). A continuación debemos ir al Dataset filtrado por este parámetro y modificar el valor del parámetro para construir dinámicamente el valor equivalente en MDX desde el valor de la fecha del calendario. Algo así:

Reutilizar Datasets dentro de un mismo informe para mostrar datos filtrados en lugar de usar Datasets duplicados casi idénticos
Puede darse el caso que en la construcción artesanal de un cuadro de mando pongamos dos indicadores con gráficos muy bonitos que muestran una métrica idéntica, por ejemplo el % de beneficio para dos canales de venta distintos. Aquí nos podríamos ver obligados a repetir conjunto de datos para cada tipo con un valor parametrizado del canal o lo que es mejor, ponemos un solo dataset filtrando los datos por canal en cada gráfico. Esto es extensible a tablas, kpi, etc. Siempre lo podremos cambiar en el dialogo de Propiedades del elemento.
Mostrar el top X de una tabla filtrando y ordenando por algún campo de valor.
Parece obvio y puede que nos enfrasquemos en la propia consulta para no recuperar más datos de los necesarios pero es posible que en un mismo informe debamos mostrar los por ejemplo los 5 mejores. Una manera de hacerlo es usar la opción de Filtros en el dialogo de Propiedades y filtrar usando el operador Superior N.
Mostrar los valores de la barra/segmento etc en gráficos y Kpi.
Para mostrar los valores de, por ejemplo, la barra de un gráfico al pasar el cursor por encima debemos establecer la propiedad “Información sobre Herramientas” en el dialogo de Propiedades de la Serie y poner #VALY{N2}.

Alinear en una misma tabla valores de distintos orígenes de datos.
En resumen, podría ser un caso donde tenemos que completar métricas de nuestro cubo con datos de fuera, por ejemplo del ERP etc... La mejor manera que se me ocurre si tenemos una instancia de SqlServer de por medio es la que explico en este post.
Depurar ejecuciones de informes basadas en quejas de usuario
Para validar una queja de usuario, saber EXACTAMENTE lo que ha tardado en ejecutarse el informe en questión y los parámetros que ha seleccionado el usuario podemos hacer la siguiente consulta en la base de datos configurada para Reporting Services.
SELECT UserName, l.TimeStart,
(l.TimeDataRetrieval)MS_SUMDATARETRIEVAL,
(l.TimeProcessing)MS_SUMPROCESSING,
(l.TimeRendering)MS_SUMRENDERING,
(DATEDIFF(ms, l.TimeStart, l.TimeEnd))AS MS_SUMTOTAL,
l.ReportPath,
l.Parameters
FROM ReportServer.dbo.ExecutionLog2 l
WHERE UserName = 'DOMAIN\ReportUser'
ORDER BY TimeStart desc
En este otro post encontraréis otras consultas de utilidad sobre las tablas de esta base de datos que permiten ver algunas estadísticas interesantes.
Acceder directamente a un informe con el visor de informes maximizado en un entorno integrado con Sharepoint Services.
Puede ser necesario presentar para algún usuario un informe al estilo cuadro de mando. La forma más sencilla, si trabajamos en modo integrado con Sharepoint Services y con bibliotecas de documentos es añadirle a Favoritos de su navegador la url con un enlace de este estilo:
https://miservidor/ReportServer?http%3a%2f%2fmiservidor%2fBiblioteca%2fInforme.rdl&rs%3aParameterLanguage=es-ES
Otra forma de no equivocarse o darle acceso rápido es cada día enviar un correo marcando necesariamente en la suscripción, en Opciones de entrega la opción Incluir vínculo.
Esta opción también soluciona, por decirlo de alguna manera, el problema que tiene Mozilla Firefox con los visores de Informes y el área de datos. Lo que sucede es que al abrir el informe sin maximizar veremos que el Visor tiene el tamaño correcto pero dentro solo veremos un mini area de datos con barra de desplazamiento.
En este enlace la segunda
En este enlace la segunda parte, con la aportación de más cosas sobre report builder y como hacerlas.
- Log in to post comments
SSRS: Consejos y how-to sobre Report builder (segunda parte)
SSRS: Consejos y how-to sobre Report builder (segunda parte) il_masacratore 9 January, 2014 - 18:08Siguiendo la línea del anterior post sobre Report Builder 2,0, dejo quizás una última lista de cosas a tener en cuenta y como satisfacer otras necesidades que me he ido encontrado con el tiempo. Cualquier aporte en los comentarios será bienvenido porque yo doy por cerrado mi aportación a este tema.
Como rellenar el fondo de una fila del mismo color sin los temidos espacios en blanco
Una manera muy sencilla y seguramente a la que llegamos todos la primera vez que queremos usar un formato condicional para el fondo de una fila es escribir una fórmula como la siguiente en la propiedad BackgroundColor de cada celda de la misma fila en cuestión:
=Switch(Sum(Fields!Margen.Value) > 0.00, "SeaGreen", Sum(Fields!Margen.Value) < 0.00, "Red")
El problema viene cuando lo intentamos hacer en una matriz y en una de las celdas no tenemos ningún valor. Esa celda por defecto se mostrará en blanco. Para subsanarlo debemos trabajar con variables. Generalmente trabajaremos con grupos, y bastará crear una variable en el grupo, asignándole ahí el valor con la fórmula anterior. Luego, en cada celda de la misma fila ponemos el valor de la variable.
La expresión para la Variable del grupo de filas (BACKCOLOR) sería:
=Switch(Sum(Fields!Margen.Value) > 0.00, "SeaGreen", Sum(Fields!Margen.Value) < 0.00, "Red")
El valor para la propiedad BackgroudColor de cada celda
=Variables!BACKCOLOR.Value

Como presentar matrices y gráficas unidas de forma visual usando los mismos colores de fondo por grupo/serie
El título es un poco rebuscado pero lo dice todo. Puede darse el caso que queramos presentar una matriz de resultados de ventas por tipos de cliente y queramos incorporar un gráfico al pie para ver la misma información de manera más intuitiva, de por ejemplo, la cuota de cada grupo sobre el total. Para hacerlo podemos hacerlo añadiendo un nuevo miembro calculado en el dataset y en la fórmula podemos a manija el color para cada serie.
En el dataset creamos el nuevo miembro con esta expresión como valor:
=Switch( Fields!GrupoCliente.Value="Cliente web","LightSteelBlue", Fields!DS_GRUPO1_ART_COM.Value="Cliente tienda","LightSteelBlue" )
En el gráfico, en la propiedad Color, del Relleno de la Serie asignamos el valor del nuevo campo:
=Fields!NUEVO_COLOR.Value
Graficos circulares 3D con etiqueta de porcentaje
Si no te lo dicen no se te ocurre ya que tampoco aparece en el asistente para añadir un nuevo gráfico. Para hacer el gráfico circular en 3D, podemos habilitarlo en las propiedades del área del gráfico. Podremos establecer el ángulo de giro y la inclinación. Podemos cambiar otras opciones 3D desde fuera, seleccionando el elemento, en el panel de Propiedades>Area3DStyle.
Las etiquetas las habilitamos haciendo clic con el botón derecho en la serie y seleccionando "Mostrar etiquetas de datos". Lo interesante es también que desde las propiedades de la serie podemos elegir que mostrar como etiqueta: el valor, % sobre el total, etc...

Grupos, subgrupos, clasificaciones y muchos puntos de vista diferentes
En un entorno complicado pueden llegar a convivir diferentes maneras de clasificar un grupo de ítems: habrá quien lo haga con dos niveles, otros con tres, el resto con cinco. Luego alguien importante en la organización con una variación de la primera clasificación de dos niveles, poniéndole nombre a su gusto a lo que ya existe.
Si hemos implementado un dwh puede que hayamos conseguido aunar criterios, pero si no es el caso podemos trampear en dos puntos distintos. Primero en la carga diaria de dimensiones usando una tabla de traducción a una clasificación totalmente distinta a la original. El segundo, en el caso de reports, podemos trampear para informes pequeños, con miembros calculados. No es algo de lo que estar orgulloso pero puede salvarnos el cuello en algún momento dado. Basta con incluir en el dataset los datos originales y luego implementar el nuevo grupo en un miembro calculado. Según el tamaño de la corrección usaremos un Iif o Switch. Solo nos faltará agrupar por el nuevo campo en la matriz, si es el caso, para agregar campos como ventas, etc...
Agregar posibilidad de cambiar ordenación de forma interactiva (en formato web)
En informes diseñados para su uso intercativo nos puede interesar añadir la posibilidad al usuario para que ordene (o cambie la ordenación asc/desc) de una matriz. Podemos habilitarle esa posibilidad cambiando las propiedad Ordenación Interactiva en la celda de la cabecera de la columna. Seleccionaremos Habilitar la ordenación interactiva de este cuadro de texto. Si no estamos trabajando con grupos, en la parte inferior seleccionaremos Filas de detalles. En ordenar por la expresión (normalmente el campo valor para la columna). Si trabajamos con grupos, en lugar de Detalles, seleccionamos Grupos y especificamos el nombre del grupo a ordenar.
Log de errores
Igual que los otros servicios incluidos con la propia base datos, ya sea Analisys Services o Reporting Services, tenemos un fichero plano a modo de log. Se encuentra en el directorio de la instancia, concretamente en la carpeta de Reporting Services>LogFiles. Ahí encontraremos un fichero que rota diariamente que contiene el log de ejecución y de errores. Es útil para sacar errores de suscripciones de informes o problemas que hayan podido afectar al servicio sin ser un problema propiamente del informe. Si queremos consultar el log actual (del día en curso), debemos provocar su volcado. Lo podemos hacer con un copiar y pegar del propio fichero (aunque veamos que ocupa 0KB).
Copia de seguridad de "urgencia" (en modo integrado con Sharepoint services)
Ante la necesidad de un cambio de "urgencia" que pueda no salir bien, si trabajamos con la instancia de SSRS integrada con Sharepoint podemos hacer una copia rápida con un copiar/pegar. Basta con abrir la página y en la carpeta de contenido utilizamos si está habilitada la opción Acciones > Abrir en Windows Explorer. Eso abrirá el explorador del sistema y veremos el contenido a modo de ficheros y carpetas del sitio de Sharepoint. Con ello podremos hacernos un backup o deploy de urgencia...

Añadir una descripción de nuestros informes (en modo integrado con Sharepoint Services)
Si trabajamos con Sharepoint y permitimos al usuario que se sirva de un portal donde puede ver un listado con los informes disponibles, y partiendo de la base que estan en "Bibliotecas de Documentos", crearemos en la vista de la misma una columna "Descripción". Para hacerlo debemos editar la configuración de la biblioteca y en el apartado Columnas añadirle una nueva del tipo "Linea de texto". Luego, para cada item de la biblioteca podremos editar su "Descripción" haciendo clic en su Propiedades>Editar Propiedades.

Muy buen articulo!!! Estuve
Muy buen articulo!!! Estuve semanas buscando porque no me coloreaba una columna entera y solo las celdas en las que tenia valores. Apliqué tu ejemplo a la columna y funcionó lo mas bien. Te estaré eternamente agradecido!
- Log in to post comments
Buen dia, Me gustaria saber
Buen dia,
Me gustaria saber como hacer para enviar los reportes al correo, estuve leyendo y mire donde ingresar la informacion como tal en la configuracion, pero quisiera saber en que opcion le tengo q dar para q envie el reporte.
- Log in to post comments
Me gustaria saber que ajustes
Me gustaria saber que ajustes se tienen que realizar en firefox al visualizar un reportr en report builder ya que al ejecutarlo se pierden los parametros pero en otros navegadores si funciona bien.
- Log in to post comments
SSRS: Estadísticas de uso, rendimiento de la ejecución de informes y log de errores de reporting services
SSRS: Estadísticas de uso, rendimiento de la ejecución de informes y log de errores de reporting services il_masacratore 23 February, 2012 - 17:15Por defecto cuando pensamos en el rendimiento de la ejecución de informes en reporting services lo primero que nos viene a la cabeza es el último informe que hemos creado. Se supone que antes de subirlo al portal de informes se supone que hemos probado en el entorno de test, con un volumen de datos similar y lo hemos validado a nivel lógico de datos. En términos de rendimiento es obligatorio, al menos para mi, controlar la ejecución de la consulta y optimizarla mirando que falla en el plan de ejecución y si hace falta donde está el cuello de botella usando el Profiler.
La cuestión es que cada día no podemos mirar ni controlar todo lo que se hace en la base de datos ni que sucede con aquel informe 'básico' implementado hace un año que coge los datos del ERP. Puede suceder que las tablas que usa hayan crecido de forma exponencial etc etc. Aunque podemos monitorizar también con los contadores de rendimiento desde el sistema operativo, cosas como esta suceden y si empezamos a recibir alertas o un usuario se percata de cierta lentitud lo suyo es tener alguna herramienta y saber cual es la carga de trabajo media y que de forma puntual nos permita analizar anomalías o picos de trabajo no habituales. Para eso podemos consultar las tablas de la base de datos que usa repoting services.
Para empezar debemos saber como se llama. Nos vamos a la Administrador de Configuración de Reporting Services, nos conectamos a la instancia que toque y miramos la pestaña Base de Datos.
Toda la información que podamos sacar casi siempre parte de las vistas ExecutionLog, ExecutionLog2 y ExecutionLog3 (SqlServer 08 R2). Estas contienen el registro de ejecución de cada informe. Otras tablas de uso obligado son Catalog y Subscriptions que contienen el detalle de informes y las suscripciones existentes respectivament.
A continuación algunas consultas útiles (suponemos que bbdd es ReportServer):
-- Informes mas usados
SELECT Name Informe, b.path Ruta,
COUNT(*) AS Ejecuciones
FROM ReportServer.dbo.ExecutionLog EL
JOIN FTXReportServer.dbo.CATALOG b
ON EL.reportid = b.itemid
GROUP BY Name,b.path
ORDER BY COUNT(*)DESC;
-- Principales consumidores (usuarios)
SELECT UserName Usuario, COUNT(*) AS Ejecuciones,
SUM(l.TimeDataRetrieval) MS_SUMDATARETRIEVAL,
SUM(l.TimeProcessing)MS_SUMPROCESSING,
SUM(l.TimeRendering)MS_SUMRENDERING,
SUM(DATEDIFF(ms, l.TimeStart, l.TimeEnd)) AS MS_SUMTOTAL
FROM ReportServer.dbo.ExecutionLog2 l
GROUP BY UserName ORDER BY MS_SUMTOTAL DESC;
-- Reports más lentos
SELECT TOP 10 Name Informe, b.path Ruta, Parameters Parametros,
FORMAT Formato,TimeStart Inicio, TimeEnd Fin, ByteCount,
(TimedataRetrieval+Timeprocessing+TimeRendering)/1000 AS Seg_TiempoTotal
FROM
FTXReportServer.dbo.ExecutionLog EL
JOIN FTXReportServer.dbo.CATALOG b
ON EL.reportid = b.itemid
ORDER BY TimedataRetrieval+Timeprocessing+TimeRendering DESC;
-- Control de suscripciones que se entregan via mail
SELECT c.Name AS INFORME, s.LastRunTime AS ULTIMA_EJECUCION,
CONVERT(char(60), s.LastStatus) AS RESULTADO
FROM ReportServer.dbo.Subscriptions s
INNER JOIN ReportServer.dbo.Catalog c
ON c.ItemID = s.Report_OID
WHERE DeliveryExtension LIKE '%Email%'
ORDER BY ULTIMA_EJECUCION DESC;
Log de errores
Para el que no lo sepa el log de errores en ejecución de informes de reporting services es un fichero que podemos encontrar en la capeta definida para la instancia de RS, carpeta ReportingServices\LogFiles. Esto es útil saberlo porque por ejemplo en modo de ejecución integrada con Sharepoint Services, si se produce un error en la ejecución de un informe el mensaje que aparece es bastante escueto y da poca información...
Hola, en reporting services
- Log in to post comments
SSRS: Suscripciones controladas por datos en modo integrado con Sharepoint Services
SSRS: Suscripciones controladas por datos en modo integrado con Sharepoint Services il_masacratore 23 February, 2012 - 15:50Suele necesitarse en entornos empresariales la entrega de informes que se generen de forma automática y que se tengan que entregar por correo o ubicarse en directorios compartidos. Reporting Services lo permite por ejemplo en el modo integrado con Sharepoint Services 3.0.Actualmente existen dos tipos de suscripción: la normal y la controlada por datos:
- Suscripción normal: Por decirlo de alguna manera es una suscripción estática. En esta elegimos el modo y tipo de entrega, formato de presentación y el evento que lanza la suscripción (fecha, periodicidad etc).
- Suscripción controlada por datos: Es algo más completa que la anterior y permite pasar parámetros al informe en cuestión desde una consulta contra una base de datos y conseguir valores como destinatarios, parámetros de fecha etc de forma dinámica.
Howto:
Nos ponemos en situación. Empresa retail dedicada a la venta al público donde cada agente necesita un reporte diario con el estado de ventas comparados con el año anterior y los objetivos. En este caso lo más normal es que vaya con su blackberry y solo pueda leer correos, eso nos obliga por ejemplo a elegir la entrega por correo del informe con la hoja de datos en formato excel por si quiere hacer sus cálculos...
Empezamos ya con el informe ya diseñado, con sus parámetros nos vamos a Administrar suscripciones y en la nueva página elegimos 'Agregar suscripción controlada por datos'.

Paso 1
Nos aparece un primer formulario donde indicamos descripción y la parte de datos. Primero debemos saber contra que base de datos hacer la consulta para sacar en nuestro ejemplo el listado de comerciales con sus correos y una columna con el valor para cada parámetro. También podemos generar valores en la consulta como el asunto del correo.
También es cierto que en reportes de estado de venta puede no ser necesario sobrescribir valores por defecto como por ejemplo la fecha actual que la podemos poner como Default value en el report. En este ejemplo usamos algo así:
-
Descripción: Report diario entregado por correo.
-
Tipo de conexión: Origen de datos personalizado
-
Tipo de origen de datos: Elegimos Microsoft SQL Server
-
Cadena de conexión: Data source=servidor; Initial catalog=comercial;
-
Consulta: SELECT ds_comercial p_comercial, ds_email p_email, GETDATE() p_hasta_fecha, 'Estado de ventas hasta ' + CONVERT(varchar, GETDATE() ) as p_asunto FROM dbo.Comerciales
Validamos y vamos al siguiente paso.
Paso 2:
Cuando hayamos terminado con esta parte saltamos a la parte de parámetros. Aquí debemos elegir entre asignar los valores con un valor estático o el generado por la consulta anterior.
Paso 3:
Tipo de entrega. Si elegimos por correo debemos elegir el Para, CC, CCO, Asunto. El resto son cosas como el tipo de presentación (elegimos excel).
-
Tipo de entrega: Correo electronico
-
Para: Elegir del despleglable Seleccionar un valor de la base de datos el valor p_email
-
Incluir informe: True
-
Formato de presentación: Excel
-
Asunto: p_asunto
-
Comentarios: Aqui podemos ponerle un texto al correo.
Paso 4:
Programación. Fecha y hora de la ejecución y entrega. Elegimos enviarlo de forma diaria:

Le damos a finalizar y listos!
El proceso en si es bastante simple pero para el usuario es la mar de cómodo que cada mañana pueda ver el estado de sus ventas mientras se toma el café al inicio de su jornada...