4. Arquitectura de los SGBD
4. Arquitectura de los SGBD Dataprix 4 Diciembre, 2009 - 10:264.1. Esquemas y niveles
4.1. Esquemas y niveles Dataprix 4 Diciembre, 2009 - 10:46Para trabajar con nuestras BD, los SGBD necesitan conocer su estructura (qué entidades tipo habrá, qué atributos tendrán, etc.).
Los SGBD necesitan que les demos una descripción o definición de la
BD. Esta descripción recibe el nombre de esquema de la BD, y los SGBD
la tendrán continuamente a su alcance.El esquema de la BD es un elemento fundamental de la arquitectura de un SGBD que permite independizar el SGBD de la BD; de este modo, se puede cambiar el diseño de la BD (su esquema) sin tener que hacer ningún cambio en el SGBD.
Anteriormente, ya hemos hablado de la distinción entre dos niveles de representación informática: el nivel lógico y el físico.
El nivel lógico nos oculta los detalles de cómo se almacenan los datos, cómo se mantienen y cómo se accede físicamente a ellos. En este nivel sólo se habla de entidades, atributos y reglas de integridad.
Por cuestiones de rendimiento, nos podrá interesar describir elementos de nivel físico como, por ejemplo, qué índices tendremos y qué características presentarán, cómo y dónde (en qué espacio físico) queremos que se agrupen físicamente los registros, de qué tamaño deben ser las páginas, etc.
| * De hecho, en el año 1971, el comité CODASYL ya había propuesto los tres niveles de esquemas. |
En el periodo 1975-1982, ANSI intentaba establecer las bases para crear estándares en el campo de las BD. El comité conocido como ANSI/SPARC recomendó que la arquitectura de los SGBD previese tres niveles de descripción de la BD, no sólo dos*.
De acuerdo con la arquitectura ANSI/SPARC, debía haber tres niveles de
esquemas (tres niveles de abstracción). La idea básica de ANSI/SPARC consistía en descomponer el nivel lógico en dos: el nivel externo y el nivel conceptual. Denominábamos nivel interno lo que aquí hemos denominado nivel físico.
| Nota |
| Es preciso ir con cuidado para no confundir los niveles que se describen aquí con los descritos en el caso de los ficheros, aunque reciban el mismo nombre. |
De este modo, de acuerdo con ANSI/SPARC, habría los tres niveles de esquemas que mencionamos a continuación:
a) En el nivel externo se sitúan las diferentes visiones lógicas que los procesos usuarios (programas de aplicación y usuarios directos) tendrán de las partes de
la BD que utilizarán. Estas visiones se denominan esquemas externos.
b) En el nivel conceptual hay una sola descripción lógica básica, única y global, que denominamos esquema conceptual, y que sirve de referencia para el resto de los esquemas.
c) En el nivel físico hay una sola descripción física, que denominamos esquema interno.
Figura 4
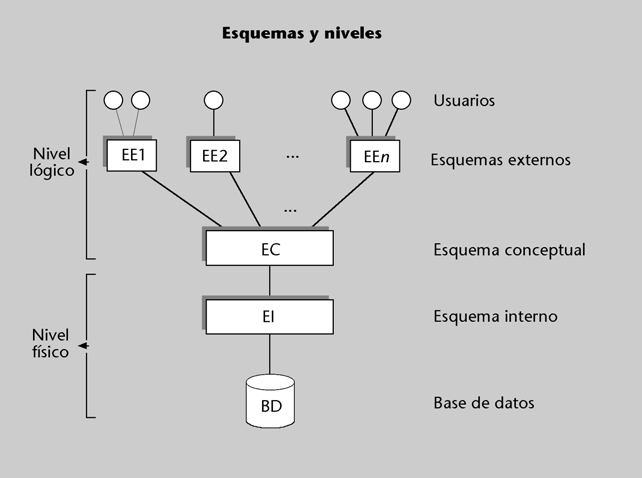
En el esquema conceptual se describirán las entidades tipo, sus atribu- tos, las interrelaciones y las restricciones o reglas de integridad.El esquema conceptual corresponde a las necesidades del conjunto de la empresa o del SI, por lo que se escribirá de forma centralizada durante el denominado diseño lógico de la BD.
Sin embargo, cada aplicación podrá tener su visión particular, y seguramente parcial, del esquema conceptual. Los usuarios (programas o usuarios directos) verán la BD mediante esquemas externos apropiados a sus necesidades. Estos esquemas se pueden considerar redefiniciones del esquema conceptual, con las partes y los términos que convengan para las necesidades de las aplicaciones (o grupos de aplicaciones). Algunos sistemas los denominan subesquemas.
Al definir un esquema externo, se citarán sólo aquellos atributos y
aquellas entidades que interesen; los podremos redenominar, podremos definir datos derivados o redefinir una entidad para que las aplicaciones que utilizan este esquema externo crean que son dos, definir combina- ciones de entidades para que parezcan una sola, etc.Ejemplo de esquema externo
Imaginemos una BD que en el esquema conceptual tiene definida, entre muchas otras, una entidad alumno con los siguientes atributos: numatri, nombre, apellido, numDNI, direccion, fechanac, telefono. Sin embargo, nos puede interesar que unos determinados programas o usuarios vean la BD formada de acuerdo con un esquema externo que tenga definidas dos entidades, denominadas estudiante y persona.
a) La entidad estudiante podría tener definido el atributo numero-matricula (definido como derivable directamente de numatri), el atributo nombrepila (de nombre), el atributo apellido y
el atributo DNI (de numDNI).
b) La entidad persona podría tener el atributo DNI (obtenido de numDNI), el atributo nombre (formado por la concatenación de nombre y apellido), el atributo direccion y el atributo edad
(que deriva dinámicamente de fechanac).
El esquema interno o físico contendrá la descripción de la organiza-
ción física de la BD: caminos de acceso (índices, hashing, apuntado- res, etc.), codificación de los datos, gestión del espacio, tamaño de la página, etc.
| * En inglés, el ajuste se conoce con el nombre de tuning. |
El esquema de nivel interno responde a las cuestiones de rendimiento (espacio y tiempo) planteadas al hacer el diseño físico de la BD y al ajustarlo* posteriormente a las necesidades cambiantes.
De acuerdo con la arquitectura ANSI/SPARC, para crear una BD hace falta definir previamente su esquema conceptual, definir como mínimo un esquema externo y, de forma eventual, definir su esquema interno. Si este último esquema no se define, el mismo SGBD tendrá que decidir los detalles de la organización física. El SGBD se encargará de hacer las correspondencias (mappings) entre los tres niveles de esquemas.
Esquemas y niveles en los SGBD relacionales
En los SGBD relacionales (es decir, en el mundo de SQL) se utiliza una terminología ligeramente diferente. No se separan de forma clara tres niveles de descripción. Se habla de un solo esquema –schema–, pero en su interior se incluyen descripciones de los tres niveles. En el schema se describen los elementos de aquello que en la arquitectura ANSI/SPARC se denomina esquema conceptual (entidades tipo, atributos y restricciones) y las vistas –view–, que corresponden aproximadamente a los esquemas externos.
El modelo relacional en que está inspirado SQL se limita al mundo lógico. Por ello, el estándar ANSI-ISO de SQL no habla en absoluto del mundo físico o interno; lo deja en manos de los SGBD relacionales del mercado. Sin embargo, estos SGBD proporcionan la posibilidad de incluir dentro del schema descripciones de estructuras y características físicas (índice, tablespace, cluster, espacios para excesos, etc.).
4.2. Independencia de los datos
4.2. Independencia de los datos Dataprix 4 Diciembre, 2009 - 10:59
| Los dos tipos de independencia de los datos se han explicado. |
En este subapartado veremos cómo la arquitectura de tres niveles que acabamos de presentar nos proporciona los dos tipos de independencia de los datos:la física y la lógica.
Hay independencia física cuando los cambios en la organización física de la BD no afectan al mundo exterior (es decir, los programas usuarios
o los usuarios directos).De acuerdo con la arquitectura ANSI/SPARC, habrá independencia física cuando los cambios en el esquema interno no afecten al esquema conceptual ni a los esquemas externos.
Figura 5
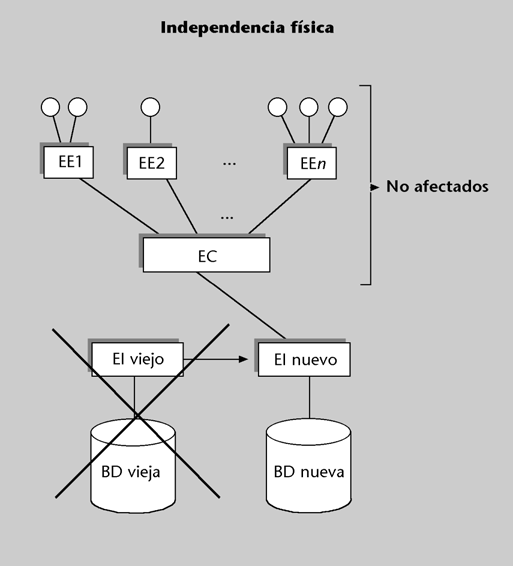
Es obvio que cuando cambiemos unos datos de un soporte a otro, o los cambiemos de lugar dentro de un soporte, no se verán afectados ni los programas de aplicación ni los usuarios directos, ya que no se modificará el esquema conceptual ni el externo. Sin embargo, tampoco tendrían que verse afectados si cambiásemos, por ejemplo, el método de acceso a unos registros determinados*, el formato o la codificación, etc. Ninguno de estos casos debería afectar al
| * Por ejemplo, eliminando un índice en árbol-B o sustituyéndolo por un hashing. |
mundo exterior, sino sólo a la BD física, el esquema interno, etc.
Si hay independencia física de los datos, lo único que variará al cambiar el esquema interno son las correspondencias entre el esquema conceptual y el interno. Obviamente, la mayoría de los cambios del esquema interno obligarán a rehacer la BD real (la física).
Hay independencia lógica cuando los usuarios* no se ven afectados por los cambios en el nivel lógico.
* Programas de aplicacióno usuarios directos.
Figura 6
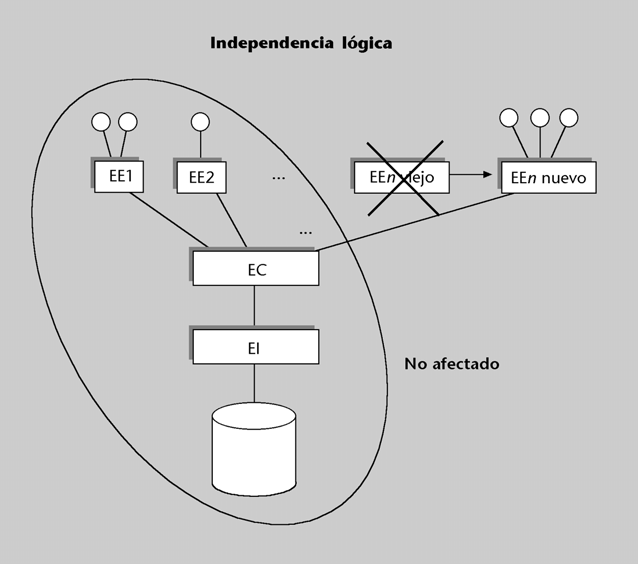
Dados los dos niveles lógicos de la arquitectura ANSI/SPARC, diferenciaremos las dos situaciones siguientes:
| Si eliminamos... |
| ... el atributo apellido, por ejemplo, no se verán afectados los esquemas externos (ni los usuarios) que no hagan referencia a este atributo.
Si se alarga el atributo dirección al esquema conceptual, no será necesario modificar el esquema externo donde se ha definido la dirección.
|
1) Cambios en el esquema conceptual. Un cambio de este tipo no afectará a los esquemas externos que no hagan referencia a las entidades o a los atributos modificados.
2) Cambios en los esquemas externos. Efectuar cambios en un esquema externo afectará a los usuarios que utilicen los elementos modificados. Sin embargo, no debería afectar a los demás usuarios ni al esquema conceptual, y tampoco, en consecuencia, al esquema interno y a la BD física.
Usuarios no afectados por los cambios
Notad que no todos los cambios de elementos de un esquema externo afectarán a sus usuarios. Veamos un ejemplo de ello: antes hemos visto que cuando eliminábamos el atributo apellido del esquema conceptual, debíamos modificar el esquema externo donde definíamos nombre, porque allí estaba definido como concatenación de nombre y apellido. Pues bien, un programa que utilizase el atributo nombre no se vería afectado si modificásemos el esquema externo de modo que nombre fuese la concatenación de nombre y una cadena constante (por ejemplo, toda en blanco). Como resultado, habría desaparecido el apellido de nombre, sin que hubiera sido necesario modificar el programa.
Los SGBD actuales proporcionan bastante independencia lógica, pero menos de la que haría falta, ya que las exigencias de cambios constantes en el SI piden grados muy elevados de flexibilidad. Los sistemas de ficheros tradicionales, en cambio, no ofrecen ninguna independencia lógica.
4.3. Flujo de datos y de control
4.3. Flujo de datos y de control Carlos 20 May, 2009 - 12:25Para entender el funcionamiento de un SGBD, a continuación veremos los principales pasos de la ejecución de una consulta sometida al SGBD por un programa de aplicación. Explicaremos las líneas generales del flujo de datos y de control entre el SGBD, los programas de usuario y la BD.
Recordad que el SGBD, con la ayuda del SO, lee páginas (bloques) de los soportes donde está almacenada la BD física, y las lleva a un área de buffers o memorias caché en la memoria principal. El SGBD pasa registros desde los buffers hacia el área de trabajo del mismo programa.
| *Por ejemplo, una variable con estrucctura de tupla |
Supongamos que la consulta pide los datos del alumno que tiene un determinado DNI. Por lo tanto, la respuesta que el programa obtendrá será un solo registro y lo recibirá dentro de un área de trabajo propia*.
Figura 7
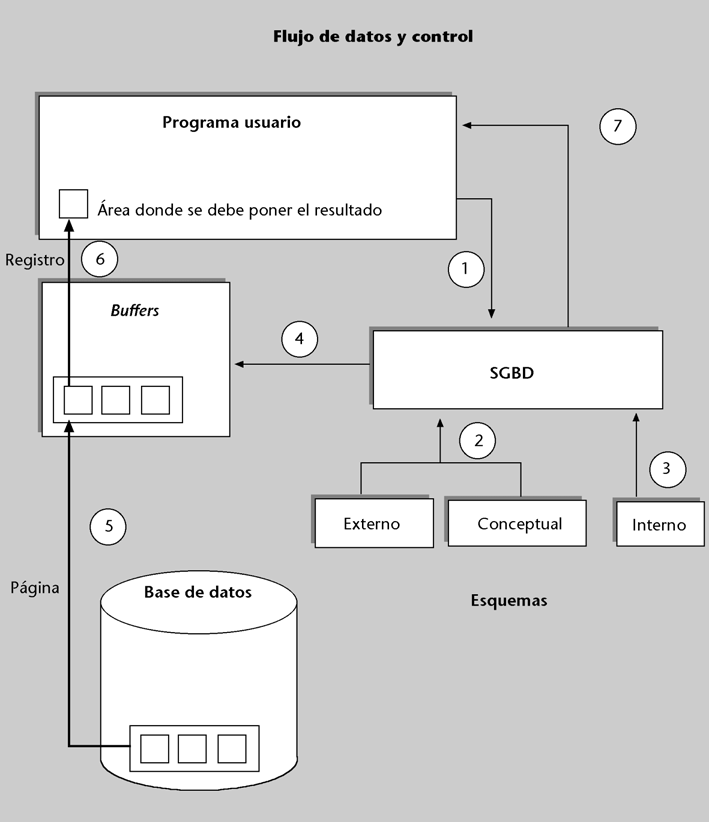
| Ejecución de una consulta |
| En la figura vemos representada la BD, los tres nivelesde esquemas, el área de los buffers, el SGBD y el programa de aplicación que le hace la consulta. |
El proceso que se sigue es el siguiente:
a) Empieza con una llamada (1) del programa al SGBD, en la que se le envía la operación de consulta. El SGBD debe verificar que la sintaxis de la operación recibida sea correcta, que el usuario del programa esté autorizado a hacerla, etc. Para poder llevar a cabo todo esto, el SGBD se basa (2) en el esquema externo con el que trabaja el programa y en el esquema conceptual.
b) Si la consulta es válida, el SGBD determina, consultando el esquema interno (3), qué mecanismo
| * Por ejemplo, siempre tiene la posibilidad de hacer una búsqueda secuencial. |
debe seguir para responderla. Ya sabemos que el programa usuario no dice nada respecto a cómo se debe hacer físicamente la consulta. Es el SGBD el que lo debe determinar. Casi siempre hay varias formas y diferentes caminos para responder a una consulta*. Supongamos que ha elegido aplicar un hashing al valor del DNI, que es el parámetro de la consulta, y el resultado es la dirección de la página donde se encuentra (entre muchos otros) el registro del alumno buscado.
c) Cuando ya se sabe cuál es la página, el SGBD comprobará (4) si por suerte esta página ya se encuentra en aquel momento en el área de los buffers (tal vez como resultado de una consulta anterior de este usuario o de otro). Si no está, el SGBD, con la ayuda del SO, la busca en disco y la carga en los buffers (5). Si ya está, se ahorra el acceso a disco.
d) Ahora, la página deseada ya está en la memoria principal. El SGBD extrae, de entre los distintos registros que la página puede contener, el registro buscado, e interpreta la codificación y el resultado según lo que diga el esquema interno.
| Diferencias entre SGBD |
| Aunque entre diferentes SGBD puede haber enormes diferencias de funcionamiento, suelen seguir el esquema generalque acabamos de explicar. |
e) El SGBD aplica a los datos las eventuales transformaciones lógicas que implica el esquema externo (tal vez cortando la dirección por la derecha) y las lleva al área de trabajo del programa (6).
f) A continuación, el SGBD retorna el control al programa (7) y da por terminada la ejecución de la consulta.