Ejemplo 2: Reglas de Asociación
Ejemplo 2: Reglas de Asociación bernabeu_dario 25 Octubre, 2010 - 13:20
Este proceso utiliza 2 importantes operadores de preprocesamiento: Primero el operador discretización de frecuencias, que discretiza atributos numéricos colocando los valores en intervalos de igual tamaño.
Segundo, el operador filtro nominal a binominal crea para cada posible valor nominal de un atributo polinominal una nueva característica binominal (binaria) que es verdadera si el ejemplo tiene el valor nominal particular.
Estos operadores de preprocesamiento son necesarios debido a que determinados esquemas de aprendizaje no pueden manejar atributos de ciertos tipos de valores. Por ejemplo, el muy eficiente operador de minería de conjuntos de ítems frecuentes FPGrowth utilizado en esta configuración de proceso solo puede manejar características binominales y no numéricas ni polinominales.
El siguiente operador es el operador de minería de conjuntos de ítems frecuentes FPGrowth. Este operador calcula eficientemente conjuntos de valores de atributos que ocurren juntos con frecuencia. A partir de estos así llamados conjuntos de ítems frecuentes se calculan la mayoría de las reglas de confianza con el generador de reglas de asociación.
Nota: Para localizar más fácilmente un operador en el árbol de operadores, se puede escribir el nombre del mismo en el cuadro [Filter] de la pestaña “Operators”.
1. Agregar el operador Retrieve en la zona de trabajo y localizar el archivo //Samples/data/Iris con el navegador del parámetro repository entry.
2. Agregar el operador Utility → Subprocess. Cambiar el nombre del mismo a “Preprocesamiento” haciendo clic derecho y seleccionando “Rename” o bien presionando la tecla <F2>.
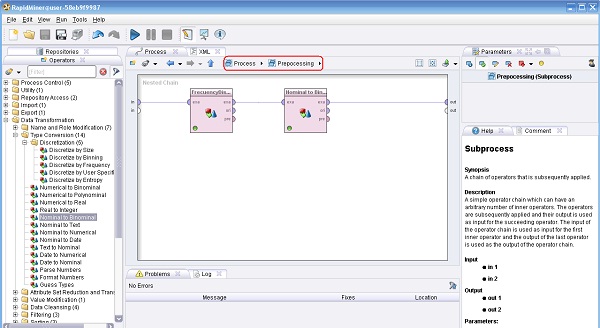
3. Conectar la salida del operador Retrieve a la entrada del operador Preprocesamiento (Subprocess) y luego doble clic sobre este último (observar que aparece un botón en la parte superior de este marco, al lado de “Process”, y que permite alternar entre el proceso y los subprocesos). En el panel Nested Chain del subnivel, agregar los siguientes operadores:
3.1 Data Transformation → Type Conversion → Discretization → Discretize by Frequency. Cambiar el nombre del mismo a “DiscretizaciónPorFrecuencias” y el parámetro number of bins (cantidad de intervalos) a 5, luego conectar la entrada in del panel a la entrada exa (example set, conjunto de ejemplos) de este operador.
3.2 Data Transformation → Type Conversion → Discretization → Nominal to Binominal. Cambiar el nombre del mismo a “Nominal2Binominal”, conectar la salida exa del operador anterior a la entrada exade este operador, y luego la salida exa de éste al conector out del panel.
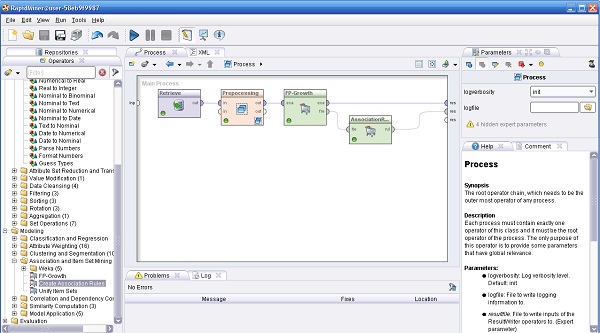
4. En el Proceso principal, agregar 2 operadores más:
4.1 Modeling → Association and Item Set Mining → FP-Growth. Cambiar el parámetro min support a 0.1, conectar la salida out del operador Preprocesamiento a la entrada exa de este operador y la salidaexa de éste último al conector res (result, resultado) de la zona de trabajo.
4.2 Modeling → Association and Item Set Mining → Create Association Rules. Cambiar el nombre del mismo a “GeneradorReglasAsociación”, conectar la salida fre (frequent sets, conjuntos frecuentes) del operador FP-Growth a la entrada ite (item sets, conjuntos de elementos) de este operador y la salida rul (rules, reglas) de éste último a otro conector res de la zona de trabajo.
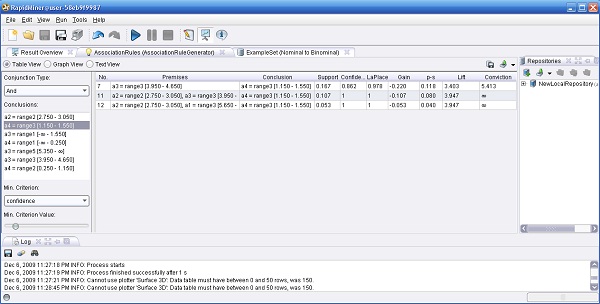
5. Ejecutar el proceso. El resultado se mostrará en un visor de reglas donde se puede seleccionar la conclusión deseada en una lista de selección en el lado izquierdo. Como para todas las otras tablas disponibles en RapidMiner, se pueden ordenar las columnas haciendo clic en la cabecera de la columna. Presionando CTRL durante estos clics permite la selección de hasta 3 columnas para ordenar.