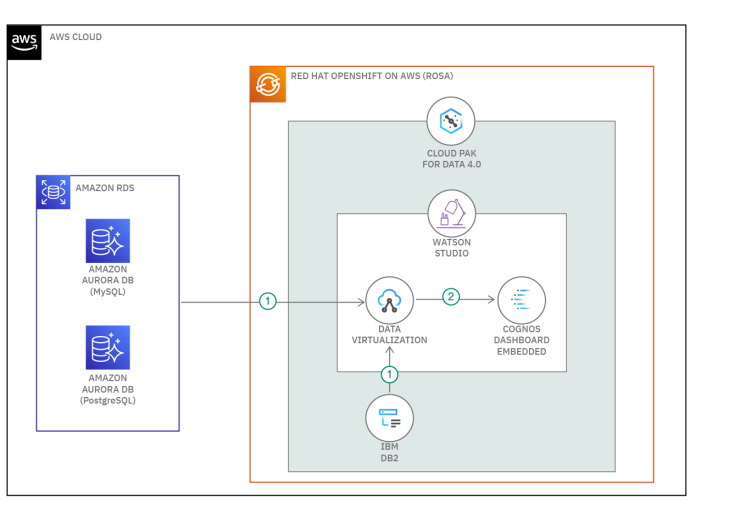
Apache Spark
- Read more about Apache Spark
- Log in to post comments
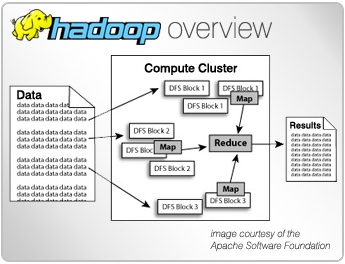
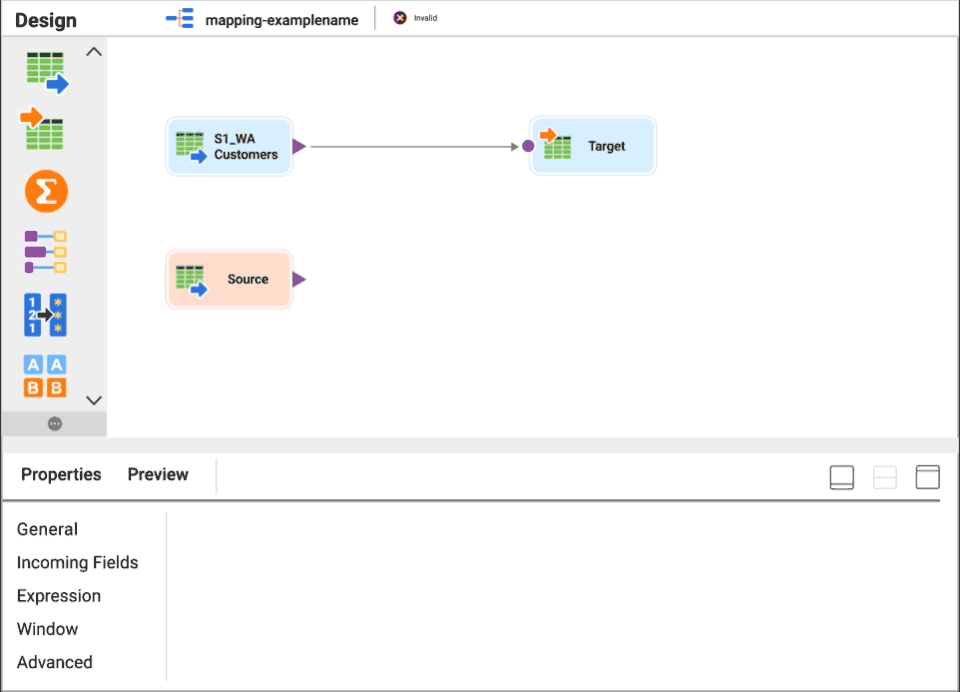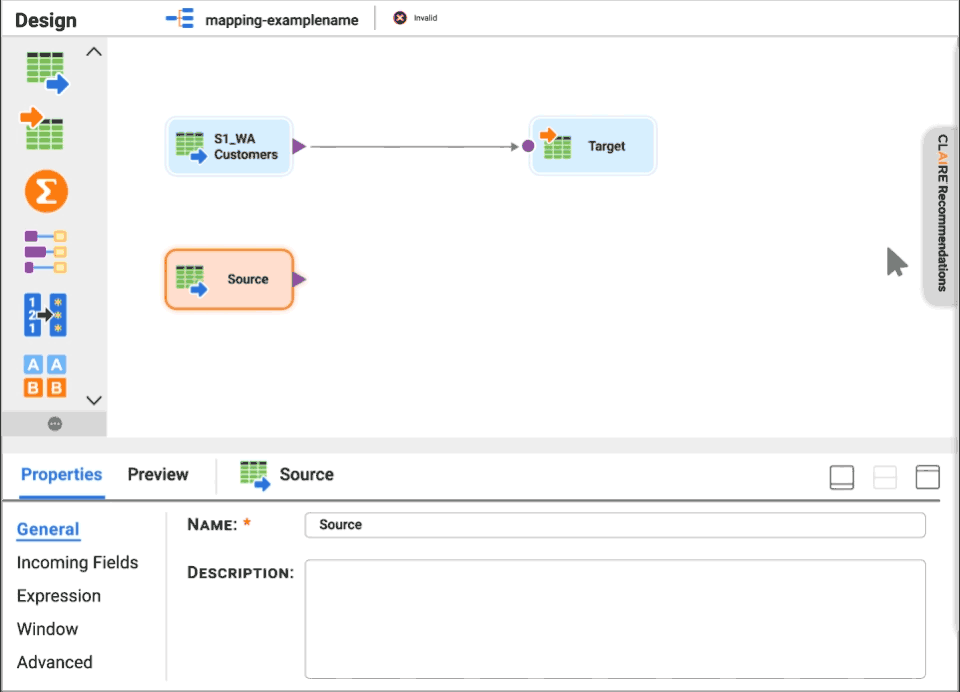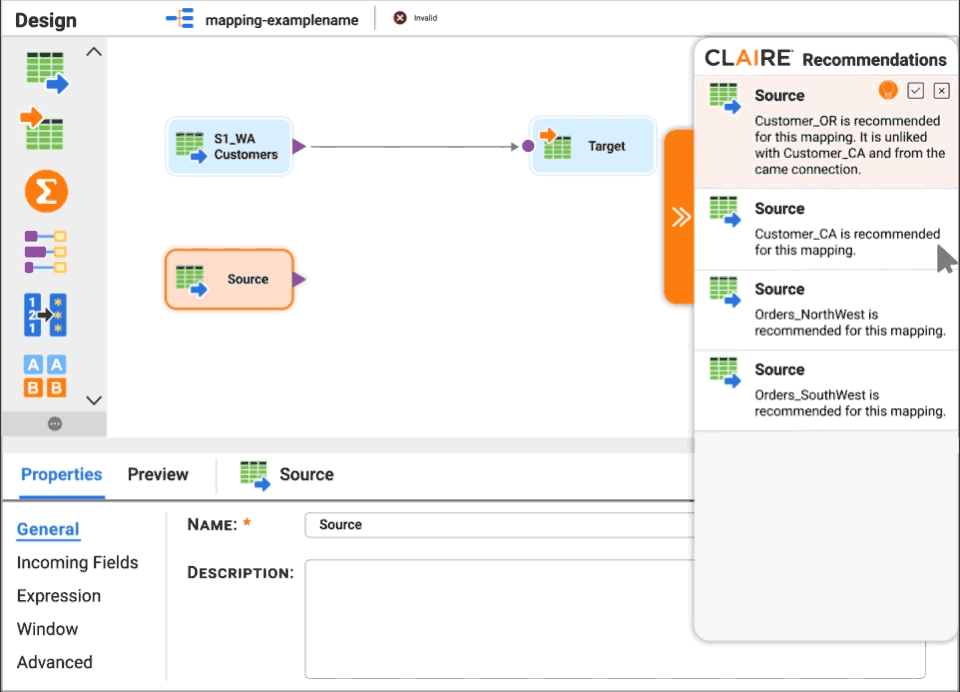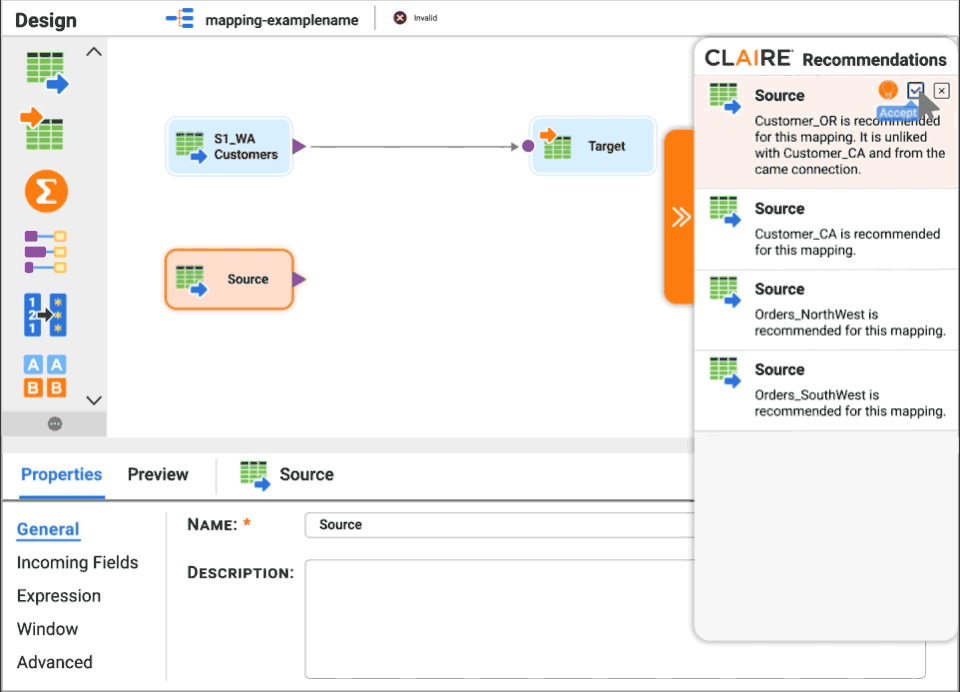
Spark is an open source framework from Apache Software Foundation for distributed processing of large amounts of data on clusters of computers, designed for use in Big Data environments, and created to enhance the capabilities of its predecessor MapReduce.
Spark inherits the scalability and fault tolerance capabilities of MapReduce, but far surpasses it in terms of processing speed, ease of use and analytical capabilities...