Administración de Microsoft SQL Server 2008
Administración de Microsoft SQL Server 2008 Dataprix Fri, 05/23/2014 - 19:27Acceder a MySql desde Sql Server 2008
How to access from SQL Server to MySQL databases il_masacratore Thu, 11/17/2016 - 17:52We could need to access to MySQL from SQL Server. An easy way to do it is creating a linked server that uses an ODBC connection.
How to link SQL Server and MySQL, step by step
- Download the ODBC client of MySQL from here, choosing the platform of the SQL Server.
- Install using the assistant (only have to click next, next..) and set a system DSN. To configure the DSN use the Manager of data sources ODBC, select the 'System DSN', click add and select 'MySQL ODBC 5.3 driver'.
Click OK and you will see a form like this. Fill in the text boxes and test the connection using the 'Test' button.

- Create the linked server in the database.
We have to connect to the SQL Server database, with SQL Server Management Studio, por example, and in the 'objects tree' select 'Server objects', click on right button over 'Linked servers', and finally select 'New linked server', fill in the data in text boxes, and that's all.

Now we will have access to the MySQL server. If we explore the list of linked servers we can select our new linked server and navigate and see the tables of the linked MySQL database.
We can use it in SQL queries by using the T-SQL function openquery as this:
select [campo,] from OPENQUERY([servidor vinculado], [select mysql])
[[ad]]
SQLServer 2008: Actualizar estadísticas de tabla de forma dinámica en toda una base de datos
Update SQL Server table statistics dynamically throughout a database il_masacratore Thu, 03/04/2010 - 11:53In Oracle databases there is a table that allows to list all the tables in the database (table 'dba_tables') and we can use this 'dba_tables' to create maintenance scripts dynamically. In SQL Server we can create also scripts of tables maintenace by querying the table [dataBase].dbo.sysobjects.
In the example below we use a T-SQL script to update statistics for all tables in a SQL Server database by querying dynamically the data dictionary (using the table dbo.sysobjects). This T-SQL code can be encapsulated in a stored procedure or in a job to be executed by the SQL Server Agent to automatically keep statistics updated on all tables of the dbo scheme in a SQL Server database.
Update statistics from all tables of the 'dbo' scheme on a SQL Server database
-- Declaration of variables
DECLARE @dbName sysname
DECLARE @sample int
DECLARE @SQL nvarchar(4000)
DECLARE @ID int
DECLARE @Table sysname
DECLARE @RowCnt int
-- Filter by database and percentage for recalculation of statistics
SET @dbName = 'AdventureWorks2008'
SET @sample = 100
--Temporary Table
CREATE TABLE ##Tables
(
TableID INT IDENTITY(1, 1) NOT NULL,
TableName SYSNAME NOT NULL
)
--We feed the table with the list of tables
SET @SQL = ''
SET @SQL = @SQL + 'INSERT INTO ##Tables (TableName) '
SET @SQL = @SQL + 'SELECT [name] FROM ' + @dbName + '.dbo.sysobjects WHERE xtype = ''U'' AND [name] <> ''dtproperties'''
EXEC sp_executesql @statement = @SQL
SELECT TOP 1 @ID = TableID, @Table = TableName
FROM ##Tables
ORDER BY TableID
SET @RowCnt = @@ROWCOUNT
-- For each table
WHILE @RowCnt <> 0
BEGIN
SET @SQL = 'UPDATE STATISTICS ' + @dbname + '.dbo.[' + @Table + '] WITH SAMPLE ' + CONVERT(varchar(3), @sample) + ' PERCENT'
EXEC sp_executesql @statement = @SQL
SELECT TOP 1 @ID = TableID, @Table = TableName
FROM ##Tables
WHERE TableID > @ID
ORDER BY TableID
SET @RowCnt = @@ROWCOUNT
END
--Drop the temporal table
DROP TABLE ##Tables
[[ad]]
Update statistics from all tables of all schemes on a SQL Server database
But if we have tables in schemes different than the dbo this script woud fail for this tables contained in other schemas. Another version of the script, that update all the table statistics in a SQLServer Database for all the tables, for the dbo scheme and for all other schemes is: (changes in red)
-- Declaration of variables
DECLARE @dbName sysname
DECLARE @sample int
DECLARE @SQL nvarchar(4000)
DECLARE @ID int
DECLARE @Table sysname
DECLARE @RowCnt int
-- Filter by database and percentage for recalculation of statistics
SET @dbName = 'AdventureWorks2008'
SET @sample = 100
--Temporary Table
CREATE TABLE ##Tables
(
TableID INT IDENTITY(1, 1) NOT NULL,
TableName SYSNAME NOT NULL
)
--We feed the table with the list of tables of all schemas
SET @SQL = ''
SET @SQL = 'INSERT INTO ##Tablas(TableName) '
SET @SQL = @SQL + ' select ''['' + TABLE_CATALOG + ''].['' + TABLE_SCHEMA + ''].['' + TABLE_NAME + '']'' from INFORMATION_SCHEMA.TABLES'
EXEC sp_executesql @statement = @SQL
SELECT TOP 1 @ID = TableID, @Table = TableName
FROM ##Tables
ORDER BY TableID
SET @RowCnt = @@ROWCOUNT
-- For each table
WHILE @RowCnt <> 0
BEGIN
-- Update statistics using only the table name
SET @SQL = 'UPDATE STATISTICS ' + @Tabla + ' WITH SAMPLE ' + CONVERT(varchar(3), @sample) + ' PERCENT'
EXEC sp_executesql @statement = @SQL
SELECT TOP 1 @ID = TableID, @Table = TableName
FROM ##Tables
WHERE TableID > @ID
ORDER BY TableID
SET @RowCnt = @@ROWCOUNT
END
--Drop the temporal table
DROP TABLE ##Tables
Cambiar en SQLServer 2008 la columna clave de una tabla a una nueva del tipo integer que sea identidad usando OVER
How to change in SQL Server the key column to an identity by using T-SQL and OVER clause Carlos Mon, 11/21/2016 - 12:10You can have the need to change the type of the key column of a SQL Server table, due to a previous bad design, or simply to a change of requirements.
If you have to change the type of a key column and the new column type has to be integer, and even identity, you can do it by using some criteria in order to get the rows ordered (PK= index clustered= order by in physical disk by this column).
We will change the type of the PK column of a table in a sample with 2 typical invoice tables master-detail where the key columns are nchar. 'invheader.invoiceid' is the primary key of the master table and 'invlines.lineid' is the primary key of the detail table.
[[ad]]
Steps to change the type of primary keys in SQL Server
Add a new column to the master table to create new id's
We start choosing the column type and creating it in the master table.
Next, un UPDATE sentence will inform the values of the new column with an incremental id calculated with a join with a select over the same table that uses the function ROW_NUMBER() to create an incremental line counter.
USE DBTEST;
ALTER TABLE INVHEADER ADD PK_INVHEADER int NULL;
UPDATE INVHEADER SET PK_INVHEADER = A.ROWNUMBER
FROM INVHEADER
INNER JOIN (SELECT ROW_NUMBER() OVER (ORDER BY DATE ASC) AS ROWNUMBER
FROM INVHEADER ) A ON INVHEADER.invoiceid = A.invoiceid;
Add a new column to the detail table to create new id's
With the table of invoice lines, INVLINES, we will add also a new column for the new row identifiers. The SQL sentences will use the same method with ROW_NUMBER(), but also joining the master table to inform the new foreig key created in previous step.
USE DBTEST;
ALTER TABLE INVLINES ADD PK_LINE int NULL;
ALTER TABLE INVLINES ADD FK_HEADER int NULL;
UPDATE INVLINES SET PK_LINE = A.ROWNUMBER,
FK_HEADER = PK_HEADER
FROM INVLINES INNER JOIN
(SELECT ROW_NUMBER() OVER (ORDER BY DATE ASC) AS ROWNUMBER, lineid, invoiceid
FROM INVLINES INNER JOIN INVHEADER ON INVHEADER.invoiceid=INVLINES.invoiceid) A
ON INVLINES.lineid = A.lineid;Alter tables to use new primary keys
The new PK's and FK are yet informed with int id's. Finally, we have to define the fields as NOT NULL and Primary Key, or even as Identity, and alter the foreign key in detail table, or add a new one.
An easy way to make this changes in tables design is using the visual environtment of SQL Server Management Studio, selecting Database diagram in the tree of the Objects explorer.

If we want that new keys are also of type identity remember that we have first to select the max value of this field on both tables to asign to identity the starting values. With SQL Server 2012 and above we can use Sequences to better control the values of identity columns.
As an extra information, useful if you plan to migrate between Oracle, MySQL or SQL Server databases, Oracle uses also sequencies but don't have a similar feature to 'Identity' in fields properties, and MySQL have the same feature od 'Identity' with the equivalent 'AUTO_INCREMENT' clause.
[[ad]]
Como deshabilitar el autocommit en SQL Server Management Studio
How to disable autocommit option in SQL Server Management Studio il_masacratore Tue, 04/27/2010 - 11:02Have you ever wondered how to disable the autocommit option in Sql Server Management Studio?
The answer is quick. Simply uncheck the option SET IMPLICIT_TRASLATIONS. To do it follow next path from the menu:
Tools> Options> Execution of the query> SQL Server> ANSI, then Uncheck Option SET IMPLICIT_TRANSACTIONS.

It seems rather simple but is a common doubt when you start using SQL Server Management Studio. By sharing this tip I hope to save time to someone that wants to disable the autocommit option in SQL Management Studio.
[[ad]]
Como recuperar la clave del usuario sa en Sql Server 2008
How to recover the password of the user sa on SQL Server Carlos Mon, 11/28/2016 - 10:34With SQL Server, when we forget or we lose the password of the DBA user 'sa', and we are the administrators of the database, we have a little problem. It's easy to forget this password because probably we have our own user administrator and don't use to log in with the sa account.
We also could have inherited the administration of a SQL Server database, with any documentation or information about the sa account, or any other domain account with administrator privileges. Even worse, we coul'd have installed an SQL Server database and next deleted the only login with admin privileges without knowing the password of the sa user.
For all this situations there is a better solution than reinstalling the database.
With SQL Server 2005, SQL Server 2008, SQL Server 2012, SQL Server 2014, SQL Server 2016.., as a recovery plan for this 'disaster', we can start the SQLServer database in 'single-user' mode and access with any user of the administrator's group of the windows OS. The 'single-user' mode is intended to perform maintenance tasks, such as applying patches and other maintenance jobs.
This single user mode will allow us to connect using sqlcmd, for example, and add a database user to the SQL Server rol 'sysadmin'. After, with this user, we will have and admin user with privileges to change the password of the sa account.
Steps to recover the sa password on SQL Server
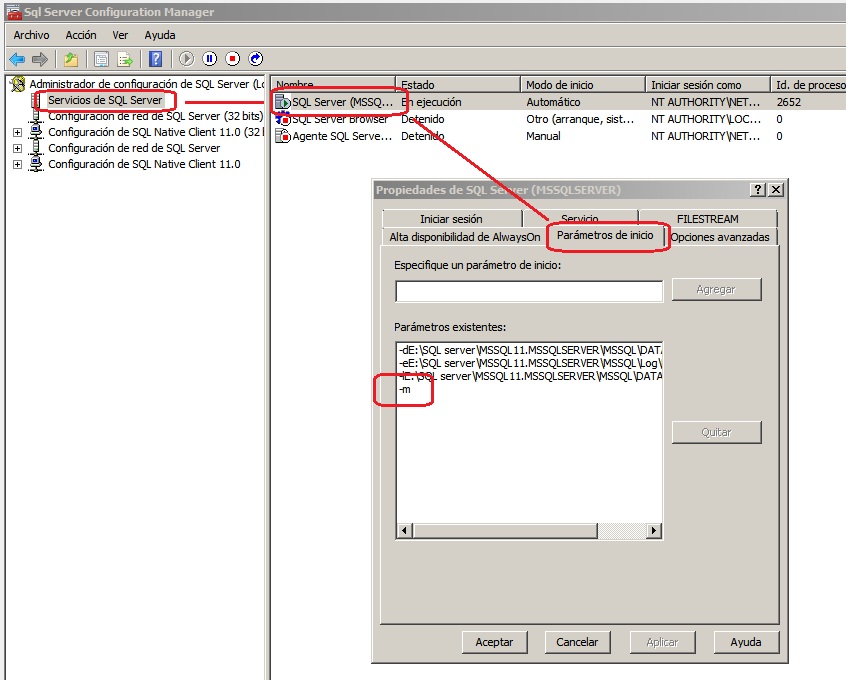
- Open the SqlServer Configuration Manager application. Search the SqlServer Service and look at 'Properties'. In the Advanced options or Init parameters add a -m at the end of the line. Press Accept and reboot the service.
(SQL Server Configuration Manager lived as an isolated application in SQL Server 2008.
In newer versions as SQL Server 2012 and systems as Windows 8 or Windows 10 this tool is an add in of the general 'Microsoft Management Console' (mmc.exe), and you will have to add this add in to use it.
Another option is to download an use the SQL Server Management Studio (SSMS), the administration tools of SQL Server 2016 that allows to administrate also instances from SQL Server 2008 and later)
- Once restarted, open the command line and the SQLCMD client and excecute this command lines:
sqlcmd -S localhost 1> EXEC sp_addsrvrolmember 'DOMINIO\Dba','sysadmin';
- Return to the SQL Server Configuration Manager (or Microsoft Management Console), remove the -m parameter added in previous steps and reboot the service.
Finally, connect to the database with the domain user modified in the command line (dba in this example), change the password of the user 'sa' and save it in a save place. That's all.
If we have applications that connect to our database and don't want that this applications enter in our database when we have activated the single-user mode, the -m parameter allows to identify what application is allowed to connect to the database in single user mode. We only have to specify the app name after -m.
For example, -m"SQLCMD" set the single-user mode for connections, and limits the connection to only the client software SQLCMD. If we prefer to work from the IDE and want to limit the connexion to only Management Studio, we should use -m"Microsoft SQL Server Management Studio - Query".
SQL Server Books
¿Do you want to learn more and go deeper into SQL Server database administration?
Check out this books about SQL Server.
SQLServer 2008: Consulta uniendo datos de SSAS con los de una tabla de cualquier otra bbdd mediante openquery
How to use Openquery to make a join between a SSAS cube and a table from any other database il_masacratore Thu, 12/01/2016 - 11:56Imagine you need a report with data from an OLAP sales cube, and also with data from a table of the relational data source, or from a table of an external or remote database.
If the relational database belongs to a SQL Server instance, you can create a linked server. With a linked server you can construct a MDX query in the SQLServer instance where you have the cube, joining with an external database to complete the data with information from tables of the relational database. Perhaps this is not the most smart solution, and could be better to redesign something in the ETL process, but sometimes could be a practical or temporary solution to a specific need.
Steps to make a MDX join with data from an OLAP cube and a table from another database
Next, the three steps to create the linked server and create a simple query to complete a total anual amount of sales with the name of the manager of the shop, joining the 'sales' cube with a 'store' table:
- Prepare the query MDX with the data from the SSAS cube, including a field that we will use as a foreign key in the join with the table of the relational database
SELECT [Measures].[Sales amount] ON COLUMNS, [Business].[Store id].members ON ROWS FROM [Sales] WHERE [Time].[Year].&[2013]
- In the Objects Explorer of SSMS search in the tree of the relational database instance the section 'Linked Servers', and press the right button and select in contextual menu 'New linked server'. Complete the fields with connection info to the SSAS instance to create the linked server.

- Edit the query that you will execute in the relational database. This query encapsulate the previous MDX query using openquery and the linked server created in previous step.
The tip to be able to select fields of the cube is to use alias, because by default the column header have the MDX format of the attribute or measure of the cube. Next, just do the join with the table using the field selected before to use as foreign key .
SELECT ssas.Store_id ,ssas.Sales_Amount ,store.manager
FROM (SELECT "[Business].[Store id].[MEMBER_CAPTION]" as Store_id
,"[Measures].[Sales amount]" AS Sales_Amount
FROM openquery( SSAS_INSTANCE, 'SELECT [Measures].[Sales amount] ON COLUMNS,
[Business].[Store id].members ON ROWS
FROM [Sales]
WHERE [Time].[Year].&[2013]')) ssas
LEFT JOIN [dbo].[Stores] store ON ssas.Store_id = store.Store_id
That's all!
Create table condicionado usando el diccionario de datos de Sql Server 2008
SQL08: Create a conditioned table using the data dictionary of SQL Server il_masacratore Sat, 06/18/2011 - 17:40Sometimes we need to check the existence of a table in a script or scheduled task to record error logs, first executions etc ...
Let us take an example, a package of integration services that normally distribute or run there where we go and that leaves traces in a custom table that is not the default for loading logs. We could always include a performance task or sql script, run right or wrong, as the first to run on the package and then continue. Being purists this just is not quite careful
CREATE TABLE LogsEtl (Execution int PRIMARY KEY, Package varchar (50), Date datetime); GO
In the first run the output is correct but fail after creating the table. This can substitute vision consulting sys.objects, where there is a record for each object in the database, and verify the existence of the table before creating it. The visibility of the metadata is limited to securables owned by the user or on which the user has any permissions. The structure of the view is as follows:
name (sysname) object_id (int)If we change the previous instruction by a create table conditioned by a query on the view looking the table name as parameter object_id (function that returns the unique identifier of an object by name) have something like this:
IF NOT EXISTS (SELECT * FROM WHERE object_id = OBJECT_ID sys.objects (N '[dbo]. [LogsEtl]') AND TYPE = N'U ') CREATE TABLE LogsEtl (Execution int PRIMARY KEY, Package varchar (50), Date datetime); GOIn this way we are doing careful and implementation will always be correct (unless the lack of permissions.)
Actually it has other applications because it could make any kind of script conditioned by the existence or not of objects in the DB or modification. For example, one could do the same query, or universal script to update / rebuild indexes based on elapsed time since last modification. We could control at administration level what is "inventing" that user with more permissions than it should have etc etc ...
Some more examples in msdn.
Cómo solventar el error 'No se permite guardar los cambios' en SQL Server 2008
Cómo solventar el error 'No se permite guardar los cambios' en SQL Server 2008 il_masacratore Tue, 11/17/2009 - 10:39Dado que es algo que se suele repetir y ya me lo han comentado más de una vez, creo oportuno crear un post donde se describa el problema y la solución en Sql server 2008 para newbies. Más que nada para que no perdaís tiempo buscando...
Problema:
Al modificar el tipo de campo en una tabla ya creada (pero vacía) o al añadir alguna clave foránea me aperece un mensaje como el siguiente:"No se permite guardar los cambios. Los cambios que ha realizado requieren que se quiten y se vuelvan a crear las tablas".
Ejemplo:

Solución:
Desmarcar la opción que impide hacer este tipo de cambios. Para ello debemos abrir la pantalla de opciones (Herramientas>Opciones), y en el apartado Designers>Diseñadores de tabla y base de datos desmarcar la opción Impedir guardar cambios que requieran volver a crear tablas. Captura:


Un tip muy útil
Pues sí, es algo muy tonto pero que si no lo sabes te deja bastante descolocado cuando empiezas con SQLServer
- Log in to post comments
Gracias ya lo había hecho
Gracias ya lo había hecho antes pero no recordaba.
- Log in to post comments
Nuevas bases de datos en nuestro servidor SQL Server 2008. Pensemos y evitemos valores por defecto
Nuevas bases de datos en nuestro servidor SQL Server 2008. Pensemos y evitemos valores por defecto il_masacratore Tue, 11/30/2010 - 14:24
Con SQL Server podemos caer muy fácilmente en lo que se dice habitualmente sobre los productos Microsoft "Siguiente, siguiente y listo". No vamos a negarlo, Microsoft consigue hacer que gente sin mucha idea salga adelante y es todo un mérito. Pero vayamos al tema. Si se empieza una nueva aplicación y tenemos que crear la estructura de datos, no dejemos solos a los desarroladores y tampoco que usen el MS Management Studio. Normalmente, en lo que a la base de datos se refiere, cuando se crean se tienen en cuenta varias cosas:
- Ajuste adecuado de los tipos de datos para cada columna
- Foreign Keys e índices
- Tamaños por defecto en ficheros de log
- Fillfactor en los índices
Los dos primeros puntos son las buenas prácticas que se suelen comentar pero poca cosa podemos hacer como administradores de la base de datos, más que asegurarnos que tiene lugar y ayudar si es necesario. Además el tema índices es algo que se puede plantear más tarde. Pero de los dos últimos puntos somos los responsables. Deberíamos conocer el tipo de aplicación, el uso que tendrá(lect/escr) y estimar el volumen de crecimiento de los datos para poder aportar nuestro granito de arena.
Inicialmente podemos ajustar el tamaño de los archivos de la base de datos (propiedades de la base de datos). Si esperamos montar una base de datos que crecerá muy rápido incrementaremos el tamaño inicial si hace falta y ajustaremos el crecimiento de los archivos de Registro(.ldf) y de Datos de filas (.mdf). Si por el contrario es pequeña podríamos dejar los valores por defecto. Ajustando este valor evitaremos diseminar los datos por el disco (son las dos imágenes de abajo).
Otro tema a tener en cuenta y que también tiene impacto es jugar con los valores de fillfactor de los índices, en base también al porcentaje de lectura/escritura y el volumen de datos.

Archivos de la base de datos

Configuración del crecimiento automático.
Eso entre otras cosas de las que ya hablaré. También es interesante que si tenemos poco espacio en disco para datos y ya no vale solo con el SHRINKFILE para vaciar logs, ante una situación de crisis podemos jugar con las prioridades y poner límites en el crecimiento automático para ciertas bases de datos que crecen de forma desmesurada ...
Politíca de backup simple para SQL Server 2008. BACKUP y RESTORE
Politíca de backup simple para SQL Server 2008. BACKUP y RESTORE il_masacratore Mon, 02/01/2010 - 13:37A continuación dejo un par de ejemplos de como funciona el backup simple de sqlserver 2008 y como hacer un restore. En el primer ejemplo hacemos un drop de la base de datos que en un entorno real puede significar la perdida de un datafile o disco etc etc. El segundo ejemplo es algo más rebuscado y lo que se hace es restaurar la copia de la base de datos para recuperar una tabla y extraer sus datos. En ambos ejemplos se trabaja con bases de datos de ejemplo descargables aquí.
Ejemplo 1. BACKUP Y RECUPERACION SIMPLE EN CASO DE PERDIDA DE LA BASE DE DATOS
En el siguiente ejemplo se hace una copia simple y una diferencial de la base de datos AdventureWorks2008. Una vez hecho se hace un drop de la base de datos para luego restaurar la base de datos al último estado antes de borrar la base de datos.
USE master;
--Modo de recuperació simple para la base de datos en cuestion
ALTER DATABASE AdventureWorks2008 SET RECOVERY SIMPLE;
GO
--Backup simple
BACKUP DATABASE AdventureWorks2008 TO DISK='F:\SQL08\BACKUPDATA\AW2008_Full.bak'
WITH FORMAT;
GO
--Backup diferencial
BACKUP DATABASE AdventureWorks2008 TO DISK='F:\SQL08\BACKUPDATA\AW2008_Diff.bak'
WITH DIFFERENTIAL;
GO
--Destrucción!!!!
DROP DATABASE AdventureWorks2008;
GO
--Restauración del último backup
RESTORE DATABASE AdventureWorks2008 FROM DISK='F:\SQL08\BACKUPDATA\AW2008_Full.bak'
WITH FILE=1, NORECOVERY;
--Restauración de los diferenciales
RESTORE DATABASE AdventureWorks2008 FROM DISK='F:\SQL08\BACKUPDATA\AW2008_Diff.bak'
WITH FILE=1, RECOVERY;
Para este ejemplo cabe destacar que cada vez que restauramos utilizamos la opción NORECOVERY hasta importar el último fichero. También es bueno saber que el parámetro WITH FILE=X indica que "fichero" se importa. En el caso de que estuvieramos añadiendo al primer fichero la copia diferencial en lugar de crear un nuevo fichero, en el momento de restaurar el segundo fichero deberíamos poner WITH FILE=2. Por último, WITH FORMAT elimina el contenido en lugar de añadir.
Ejemplo 2. BACKUP Y RECUPERACIÓN SIMPLE EN CASO DE PERDIDA DE UNA TABLA
Este es el típico caso en el que en una base de datos conviven distintas aplicaciones y hemos perdido alguna tabla o se han hecho modificaciones que requieren recuperar datos. En este caso es posible que por ello no podamos restaurar la base de datos actual con la copia. A continuación muestro como recuperar la base de datos en una nuevo con otro fichero y otro nombre para poder traspasar o comprobar datos:
Partimos de un caso como el anterior donde se tiene una copia full y diferenciales. Suponemos que sabemos cuando se ha producido el error.
USE master;
--Modo de recuperació simple para la base de datos en cuestion
ALTER DATABASE AdventureWorksDW2008 SET RECOVERY SIMPLE;
GO
--Backup simple
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008.bak'
WITH FORMAT;
GO
--Creación de tabla
CREATE TABLE AdventureWorksDW2008.dbo.Prueba
(
F1 char(2000),
F2 char(2000)
)
--Backup diferencial
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008_D1.bak'
WITH DIFFERENTIAL;
--Drop de la tabla
DROP TABLE AdventureWorksDW2008.dbo.Prueba;
--Segundo backup diferencial
BACKUP DATABASE AdventureWorksDW2008 TO DISK='F:\SQL08\BACKUPDATA\AWDW2008_D2.bak'
WITH DIFFERENTIAL;
GO
--Restauración del último backup completo en otra base de datos
RESTORE DATABASE AdventureWorks2008DWTemp FROM DISK='F:\SQL08\BACKUPDATA\AWDW2008.bak'
WITH FILE=1,
MOVE N'AdventureWorksDW2008_Data' TO 'F:\SQL08\DATA\MSSQL10.TEST\MSSQL\DATA\AdventureWorksDW2008Temp_Data.mdf',
MOVE N'AdventureWorksDW2008_Log' TO 'F:\SQL08\DATA\MSSQL10.TEST\MSSQL\DATA\AdventureWorksDW2008Temp_Log.mdf',
NORECOVERY;
--Restauración de los diferenciales
RESTORE DATABASE AdventureWorks2008DWTemp FROM DISK='F:\SQL08\BACKUPDATA\AWDW2008_D1.bak'
WITH FILE=1,
RECOVERY;
Este segundo caso sería más sencillo en un entorno donde se incluyera copia de los ficheros de transacciones y pudieramos hacer una restauración point-in-time.
El código que aquí encontramos perfectamente se puede partir y podemos programar ya las copias (full y/o diferenciales) en jobs del agente de sql server. Por ejemplo podríamos hacer la copia full el domingo y de lunes a sabado seguir con los diferenciales, pero esto también se puede programar usando SQL Server Management Studio y hacerlo de forma visual (aunque saber hacerlo desde código no está de más)...
Sincronización de la base de datos de Microsoft Dynamics AX 2009 sobre Sql Server 2008
SQL08: Synchronization Database Microsoft Dynamics AX 2009 on SQL Server 2008 il_masacratore Tue, 04/13/2010 - 11:08For those database administrators who have to deal with such a Dynamics Ax 2009 and his henchmen (developers, consultants, etc.  ) I leave here a couple of things you should know (or I should say) when we join ax2009 and sql server 2008. Sometimes you can point to the database as a source of the problem but not always. Some requirements to consider for installing Ax2009 are that the user you want access to the system should be user and DOMAIN in sql server role must be a member of securityadmin dbcreator and to create the new database from Ax installer. Once installed (or during the installation process) the problem with the database that we can find include:
) I leave here a couple of things you should know (or I should say) when we join ax2009 and sql server 2008. Sometimes you can point to the database as a source of the problem but not always. Some requirements to consider for installing Ax2009 are that the user you want access to the system should be user and DOMAIN in sql server role must be a member of securityadmin dbcreator and to create the new database from Ax installer. Once installed (or during the installation process) the problem with the database that we can find include:
Case 1:
Another known problem in data synchronization can be caused by the lack of permits. The message goes like this:
"Cannot execute a data definition language command on ().
The SQL database has issued an error.
Problems during SQL data dictionary synchronization.
The operation failed.
Synchronize failed on 1 table(s)"
This particular case is solved giving db_ddladmin permissions on the database in question. According to the official document setup Dynamics Ax 2009 AOS user must have the roles db_ddladmin, db_datareader, and db_datawriter on your database-enabled everything work properly.
Case 2:
Ax2009 may be that in adding a field on a table can not be reflected in the database but in the AOT
Axapta. If it is something that occurs only in the field, or rather with that type of field (Extended Data Type) database has nothing to do. The problem is probably that the functionality of hanging this type of field is disabled. This usually happens at a new facility which has not been activated at all (Thanks Alexander for the help!  ).
).
In another post I hope to discuss what steps to follow when you synchronize a table Ax.
Cómo montar dos entornos en un mismo servidor SQL Server 2008 sin que se "pisen"
SQL08: affinity_mask, IO_affinity_mask and like riding two on a single server environments without being "walked" il_masacratore Mon, 04/19/2010 - 10:56We put ourselves in position
In our environment we may need to have two replicas of a / s data base distinct environments (the classic example would be production and test). In deciding as we do the most common questions we must ask ourselves are:
- Is this new environment will be temporary? Does large data bases in terms of volume and / or load to be borne is high (even test)?
- Is there version SqlServer2008 development? That alone is at hand if you have an MSDN subscription ...
- Is there an extra server?
Based on these questions and all that it can happen one can opt for different solutions:
"The easiest and if the database to bear the burden are small we can use the same server for all databases (created on the same server with different names (_test) and Holy Easter ...). In order not to disturb each other we can use Resource Governor.
"The most" aseptic "if resources permit and where it would be worthwhile to mount on different servers (if we have the development version)
"Another option is a mixture of the above. Fit the two environments on the same server but different instances.
-Etc ...
1 server cpu n (n> 1) + 2 = 2 instances environments
One option that I like about the above is the third, where we mounted two instances to separate the two environments and we set the processor affinity to control the dedication of each processor to each instance. We must also control the memory assigned to each instance (server memory and max server memory).
Example:
In a 6-core dedicated server 2 of the four processors to service the test environment while the remaining 6 were awarded the production environment. To do so we just have to open the SSMS and the Server Properties: XXXX in the part of processors each processor to enable manually (by unchecking the automatic award). View image.

It's good to know also that we can allocate and deallocate the convenience since you can vary dynamically for each instance. If necessary change is good if the carrying capacity is upon us. But all is not gold that glitters, and we know that to be managing two instances we are already consuming more than if gestionáramos only one.
Concepts: affinity mask, affinity io mask
Cómo habilitar conexiones remotas a un servidor SQL Server sobre Windows
Cómo habilitar conexiones remotas a un servidor SQL Server sobre Windows Carlos Wed, 03/04/2020 - 20:23Tras la instalación de un servidor SQL Server en una máquina con Windows Server, el siguiente paso lógico es configurarlo para permitir conexiones remotas a la base de datos desde otros equipos.

Para ello hay que utilizar primero el Administrador de configuración de SQL Server para habilitar el protocolo TCP/IP sobre la dirección IP del server, y después abrir los puertos necesarios (el 1433 por defecto), desde el Firewall de Windows.
Estos son los pasos básicos que yo suelo seguir, probando a conectar desde una máquina cliente como mi PC o portátil al servidor.
Comprobar que hay conexión entre el cliente y el servidor (ip 192.168.1.116)
Nunca está de más comprobar con un simple ping que hay conectividad entre las dos máquinas abriendo una consola de comandos (cmd) desde el cliente:
C:\Users\Administrador>ping 192.168.1.116 Pinging 192.168.1.116 with 32 bytes of data: Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128 Reply from 192.168.1.116: bytes=32 time<1ms TTL=128
(Pruebo todo directamente con la IP para descartar posibles problemas de resolución de nombres de servidor)
Comprobar con telnet que no esté abierto ya el puerto
Telnet se utiliza también desde la linea de comandos. Si tienes windows 10 y no lo tienes activado consulta aqui cómo habilitarlo.
En este ejemplo utilizamos el puerto por defecto de SQL Server 1433, aunque para más seguridad es recomendable utilizar puertos diferentes, pero ese es otro tema..
C:\Users\Administrador>telnet 192.168.1.116 1433 Connecting To 192.168.1.116...Could not open connection to the host, on port 1433: Connect failed
Habilitar el protocolo TCP/IP sobre la dirección IP del server
Abrir en el servidor el programa Administrador de configuración de SQL Server (Sql Server Configuration Manager), desde el menú de aplicaciones de SQL Server, o buscando el programa en el buscador del server.

Una vez abierto, en el menú de la izquierda, en 'Configuración de red de SQL Server', Seleccionar 'Protocolos de [Nombre de la instancia]', y hacer doble click sobre el Nombre de protocolo TCP/IP para acceder a sus propiedades y seleccionar 'Si' en 'Habilitado', y en la pestaña de Direcciones IP, seleccionar también 'Si' en 'Habilitado' de la IP del server, este caso 192.168.1.116, y asegurarse de que el puerto es correcto (en este caso 1433 ya estaba bien porque es el puerto por defecto, pero si no hay que modificarlo)

Después de estas modificaciones hay que reiniciar el servicio principal de SQL Server desde la misma aplicación, en el menú 'Servicios de SQL Server'
Abrir el puerto TCP desde el Firewall de Windows Server
El siguiente paso es abrir la aplicación Firewall de Windows, desde el panel de control (Panel de control\Sistema y seguridad\Firewall de Windows), o buscando Firewall en el buscador de aplicaciones.
Una vez abierto, seleccionar 'Configuración avanzada' en el menú de la izquierda, y después, en el menú hacer click con el botón derecho sobre 'Reglas de entrada', y seleccionar 'Nueva Regla' (También se puede hacer desde la opción de menú 'Acción')

Seleccionar regla tipo 'Puerto', y después 'TCP', y escribir 1433 en la opción 'Puerto específico local'. Esta es la configuración más sencilla, y sirve si esta es la única instancia de SQL Server instalada en el Servidor Windows.

Si hubiera más instancias sería necesario abrir más puertos, activar el servicio SQL Server Browser, y abrir otro puerto UDP, y también crear una nueva regla personalizada en el firewall para el servicio.
Seleccionando las siguientes opciones (normalmente las que vienen por defecto ya van bien) se finaliza la creación de la regla del firewall, y el telnet por el puerto 1433 desde la máquina cliente ya debería responder:
C:\Users\Administrador>telnet 192.168.1.116 1433

Una vez que el telnet responde, ya se podrá conectar con SQL Server Management Studio u otra aplicación cliente, al menos por IP ;)